Introduction à l'optimisation des coûts et des performances sur BigQuery
On poursuit
Dans la première partie de cette série, j'ai présenté quelques connaissances préalables ainsi que les éléments opérationnels nécessaires pour exécuter les requêtes et entamer le travail d'optimisation.
Dans cette partie, j'aborde les erreurs de requêtage les plus courantes qui finissent par coûter plus cher à nos clients ou qui provoquent des problèmes de performance. Considérez ce contenu comme un guide de référence à consulter dans les parties suivantes pour corriger ce que vous aurez identifié.

Si vous avez hâte de passer à la pratique, n'hésitez pas à sauter directement à la partie 3, où je présenterai des requêtes concrètes et expliquerai comment les utiliser.
Erreurs de requêtage courantes qui font grimper les coûts et la complexité
Avant d'entrer dans les requêtes qui vous fourniront les données réelles, voici quelques exemples d'erreurs très fréquentes que nous observons dans l'écriture de requêtes BigQuery. Elles peuvent prolonger inutilement les temps de traitement et, presque toujours, alourdir la facture.
Tout cela est documenté en ligne, mais je tiens à mettre en avant les cas les plus fréquents que nous rencontrons chez DoiT International en accompagnant régulièrement des centaines de clients.
SELECT \*
C'est probablement la principale source de surcoûts, à la fois en montant dépensé et en nombre de clients qui tombent dans le piège.
Il existe certains cas où il faut sélectionner toutes les colonnes d'une table ou d'une vue, mais la plupart du temps, c'est inutile et cela ne fait que scanner des données superflues. Ces cas se présentent généralement lorsque vous avez déjà filtré la portée d'une vue ou utilisé une Common Table Expression (CTE) pour cibler les données nécessaires, ou encore lorsque vous travaillez avec une petite table — comme une table de faits — dont toutes les données sont nécessaires, pour ne citer que deux exemples courants.
En dehors de ces rares cas, ne faites jamais de SELECT * sur vos données. Puisque BigQuery facture en fonction du volume de données scannées par vos requêtes, sélectionnez toujours uniquement ce dont vous avez besoin pour limiter ce coût.
Prenons l'exemple d'une table de 5 To avec 5 colonnes (en supposant que chaque colonne contient la même quantité de données, soit 1 To par colonne) et que vous deviez tout scanner. Un SELECT * sur cette table coûtera 25 $ pour cette seule requête, alors qu'un SELECT sur les 2 colonnes dont vous avez besoin n'en coûtera que 10 $. Cela peut sembler peu, mais si vous l'exécutez 100 fois par jour, l'addition monte vite.
Voici un exemple de ce qu'il NE FAUT PAS faire avec un SELECT * (table de 1,6 To) :
SELECT *
FROM `bigquery-public-data.crypto_bitcoin.transactions`
Jointures inutiles ou trop volumineuses
Sur BigQuery et les autres entrepôts de données qui privilégient une approche OLAP, la bonne pratique consiste à dénormaliser les schémas de la base. Cela aplatit les structures de données et réduit le nombre de jointures nécessaires par rapport à une base relationnelle traditionnelle.
La raison : une jointure est bien plus lente dans BigQuery que dans une base traditionnelle, en raison du mode de stockage des données dans le système sous-jacent. Pour donner un ordre d'idée, lire la colonne suivante d'une table sera bien plus rapide que d'aller chercher une autre table sur disque, filtrer ses données, en extraire les correspondances, puis servir le résultat joint. Cela représente bien plus de lectures et de traitement que d'avoir les données (ou une copie) directement dans la même table.
Il va sans dire que joindre de grandes tables prend plus de temps et scanne davantage de données. Éviter ces jointures et stocker la colonne nécessaire directement dans la même table fait économiser énormément de temps de traitement et de coûts de scan.
Pour terminer sur les jointures inutiles, évoquons le concept de self-join, où les données d'une table doivent être découpées en fenêtres temporelles ou ordonnées en interne sur des lignes en double (ce que de nombreux SGBD appellent le ranking). C'est un processus TRÈS lent ; la recommandation générale est de l'éviter au profit des fonctions de fenêtrage ou analytiques proposées par BigQuery.
Pour illustrer cela, car beaucoup de clients n'utilisent jamais cette fonctionnalité, voici un exemple de classement des job IDs en double dans votre vue INFORMATION_SCHEMA :
SELECT
query,
job_id AS jobId,
COALESCE(total_bytes_billed, 0) AS totalBytesBilled,
ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnk
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
Cross Joins
Beaucoup de personnes venant d'un SGBDR avec un bagage de génie logiciel pourraient lever un sourcil en lisant cette section : les cross joins, ça s'utilise vraiment ?
Croyez-le ou non, ils ont leur utilité (principalement dans les scénarios purement ensemblistes) et, sur BigQuery, ils sont indispensables dans certains cas. L'exemple type est l'éclatement de tableaux en lignes (unnesting), une opération assez courante en analytique.
Voici un exemple tiré de requêtes utilisées plus loin dans la série, qui montre l'unnesting d'une colonne de type RECORD à l'aide d'un CROSS JOIN :
SELECT
user_email AS user,
job_id AS jobId,
tables.project_id AS projectId,
tables.dataset_id AS datasetId,
tables.table_id AS tableId,
ROW_NUMBER() OVER (PARTITION BY job_id ORDER BY end_time DESC) as _rnk
FROM
`<project-name>`.`<region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
CROSS JOIN
UNNEST(referenced_tables) AS tables
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 14 DAY)
AND CURRENT_TIMESTAMP()
Le problème, c'est que bien souvent, le cross join est placé comme l'opération la plus interne de la requête, ce qui fait remonter BEAUCOUP plus de données que ce qui sera réellement renvoyé en sortie. Vous êtes donc facturé pour la lecture d'un grand volume de données qui sera probablement écarté plus tard dans la requête — mais même écarté, BigQuery vous facturera ce qu'il a dû scanner et lire.
Cela dit, l'analyseur de requêtes BigQuery progresse pour détecter ces situations et corriger les plans d'exécution afin d'en limiter l'impact. Au fil de la rédaction de ces articles et des démonstrations chez nos clients, j'ai constaté des améliorations tout au long de 2022 : certains cas étaient identifiés et réordonnancés pour éviter ce scénario. Mais comme toujours, ne supposez jamais que l'optimiseur corrigera de mauvaises pratiques de requêtage.
La règle de base : placez toujours vos cross joins au point le plus externe possible de votre requête. Cela réduit le volume de données lues avant l'opération, donc le nombre de slots consommés et le volume facturé par BigQuery.
Common Table Expressions (CTE)
Les Common Table Expressions, ou CTE, sont des outils formidables qui simplifient considérablement le code SQL.
Pour ceux qui ne les connaîtraient pas, ce sont essentiellement des tables temporaires en mémoire qui n'existent que pour le job en cours. C'est un excellent moyen de structurer du code SQL qui s'enfonce dans plusieurs niveaux de sous-requêtes.
Notez qu'elles servent surtout à la lisibilité, pas à la performance, car elles ne matérialisent pas les données et seront ré-exécutées si elles sont utilisées plusieurs fois. De bons exemples : toutes les requêtes du dépôt GitHub de cette série, écrites davantage pour la lisibilité et la facilité de modification que pour la performance.
Cela dit, le principal problème de coût et de performance que nous rencontrons consiste à utiliser une CTE dans une requête puis à la référencer plusieurs fois, ce qui fait que la requête de la CTE est exécutée plusieurs fois. Vous serez donc facturé plusieurs fois pour la lecture des mêmes données.
Là encore, l'analyseur de requêtes BigQuery progresse sur ce point et détecte parfois ce comportement pour corriger le plan d'exécution et n'exécuter la CTE qu'une seule fois. Une dernière vérification effectuée pendant la rédaction a montré, sur plusieurs exécutions, que certaines requêtes n'exécutaient les CTE qu'une fois, et d'autres plusieurs fois.
Ne pas utiliser les partitions dans les clauses WHERE
Les partitions sont l'une des fonctionnalités les plus importantes de BigQuery pour réduire les coûts et optimiser les performances de lecture. Pourtant, elles sont souvent inutilisées et beaucoup d'argent est dépensé en requêtes qui ne devraient pas coûter autant.
Une partition découpe une table sur disque en plusieurs partitions physiques distinctes selon une valeur entière ou de type timestamp/datetime/date présente dans une colonne spécifique. Ainsi, lorsque vous lisez les données d'une table partitionnée et que vous spécifiez une plage sur cette colonne, seules les partitions contenant les données de cette plage seront scannées, et non toute la table — ce qu'on appelle un table scan dans le monde des bases de données.
Par exemple, dans la requête suivante, je récupère le total d'octets facturés pour toutes les requêtes des 14 derniers jours. La table JOBS_BY_PROJECT est partitionnée sur la colonne creation_time (la documentation du schéma se trouve ici) et, exécutée sur une table d'environ 17 Go, elle traite 884 Mo de données.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
À l'inverse, la requête suivante utilise la colonne start_time, qui n'est pas partitionnée mais reste habituellement à quelques fractions de seconde de creation_time. Exécutée sur le même jeu de données, elle traite 15 Go. La raison : elle scanne la table entière pour en extraire les valeurs demandées.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
La différence est notable, même sur un petit jeu de données : la première requête coûte environ 0,004 USD et la seconde environ 0,75 USD. Dans ce cas, ne pas utiliser correctement une colonne partitionnée revient environ 21 fois plus cher.
Côté performance, la première requête a pris environ 2 secondes et la seconde environ 5 secondes. Ce n'est pas grand-chose pour une table aussi petite, mais sur une table de plusieurs To, l'écart pourrait facilement atteindre plusieurs minutes par exécution.
Vues trop complexes
C'est un problème très courant qui dépasse largement le cadre de BigQuery : créer des vues complexes qui dégradent les performances. BigQuery, comme la plupart de ses cousins pseudo et réellement relationnels, prend en charge un objet appelé vue, qui est essentiellement une requête présentant ses résultats comme une table afin d'en faciliter l'interrogation.
Les vues sont extrêmement utiles pour abstraire de la logique, masquer des colonnes aux utilisateurs qui n'ont pas à les voir, et bien d'autres usages. Le revers de la médaille : les résultats d'une vue ne sont pas matérialisés — autrement dit, ils ne sont pas stockés sur disque — et à chaque interrogation, le moteur peut être amené à les recalculer pour les fournir à la requête appelante.
Ainsi, si la vue contient des calculs assez lourds exécutés à chaque interrogation, cela ajoute une pénalité de performance non négligeable à la requête appelante. Il est judicieux de réfléchir à la quantité de logique présente dans chaque vue. Si elle est un peu trop complexe, mieux vaut peut-être la pré-calculer dans une autre table ou la loger dans une vue matérialisée pour gagner en performance.
Petits inserts
Il arrive souvent qu'un seul ou un petit nombre d'enregistrements doivent être insérés dans une table, en particulier dans les applications de type streaming. Le souci, c'est que BigQuery porte bien son nom : Big, et il préfère traiter de gros volumes de données à la fois.
Les petits inserts consomment généralement autant de temps et de slots pour insérer 1 Ko que pour insérer 10 Mo. Faire 1 000 inserts de lignes de 1 Ko peut donc consommer jusqu'à 1 000 fois plus de temps de slot qu'un seul insert de 10 Mo de lignes.
Le mieux est de regrouper les données par lots et de les insérer en batch plutôt que de multiplier les petits inserts. Cela vaut aussi pour les opérations de streaming : évitez les Streaming Inserts, regroupez plutôt vos données par lots et insérez-les avec un délai d'arrivée acceptable.
Abus des instructions DML
C'est un problème majeur qui survient en général lorsqu'on traite BigQuery comme un SGBDR traditionnel et qu'on recrée des données à volonté.
Trois exemples typiques que l'on rencontre relativement souvent ressemblent à ceci :
DELETE TABLE <table-name> IF EXISTS;
CREATE TABLE <table-name> …;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
TRUNCATE TABLE <table-name>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
DELETE FROM TABLE <table-name> WHERE <condition>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
Sur un SGBDR comme SQL Server ou MySQL, ces opérations sont relativement peu coûteuses et probablement assez fréquentes en dehors d'un contexte d'entrepôt de données.
En revanche, dans BigQuery, ce sont des requêtes très peu performantes qu'il faut éviter en usage courant. Les instructions DML de BigQuery sont notoirement lentes parce que le moteur n'est absolument pas optimisé pour cela, contrairement à un SGBDR traditionnel.
Au lieu de procéder ainsi, envisagez un modèle additif : insérez de nouvelles lignes avec un timestamp pour indiquer qu'elles sont les plus récentes, puis supprimez périodiquement les anciennes si l'historique n'est pas nécessaire. Rappelez-vous que BigQuery est un entrepôt de données conçu pour l'analytique : il est optimisé pour exploiter des données existantes plutôt que pour les modifier de manière transactionnelle.
Une bonne façon d'illustrer cela : créez la même table dans votre SGBDR et dans BigQuery, insérez-y un grand volume de données d'exemple, puis examinez le plan d'exécution d'une instruction MERGE ou UPDATE (dans BigQuery, ce sera le query plan). En comparant les plans, vous remarquerez que BigQuery met beaucoup plus de temps sur la partie DDL ou JOIN (pour les MERGE) de la requête et, selon l'instruction, peut même comporter plusieurs étapes.
Pour illustrer, j'exécute une instruction de merge très simple qui insère lorsqu'aucune correspondance n'est trouvée sur la table transactions du jeu de données public crypto_bitcoin. Je merge un sous-ensemble d'un an de transactions avec l'ensemble complet (environ 400 Go et 1,54 To respectivement). Dans cet exemple, ci-dessous, vous remarquerez qu'il faut beaucoup de repartitionnement de données entre les phases, et l'essentiel du temps se concentre sur une opération de JOIN. Notez que pour un merge plus complexe, ces phases s'allongeraient encore et compteraient davantage d'étapes de repartitionnement.
Voici le plan d'exécution généré (réparti sur deux captures d'écran tant il est volumineux, ce qui démontre bien le propos) :
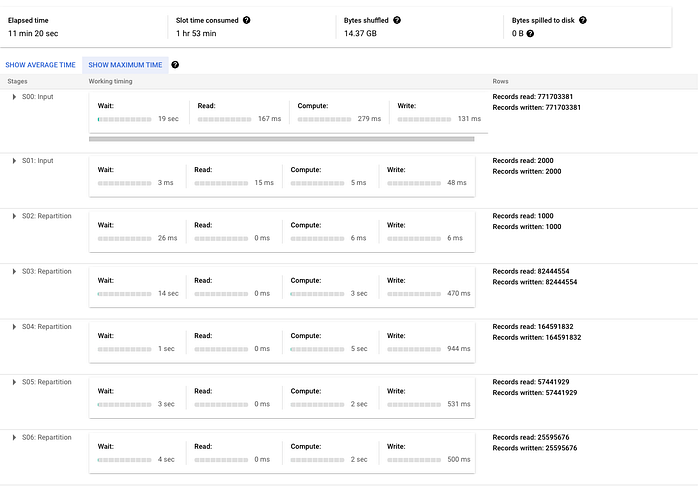
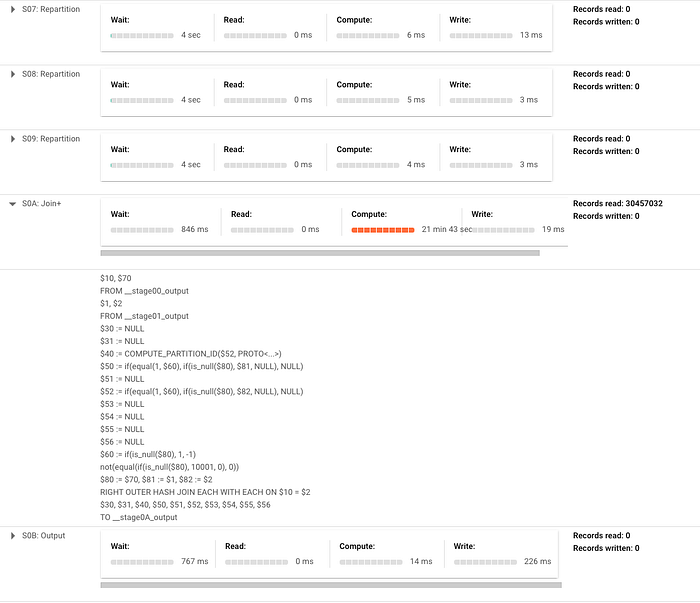
À suivre
Cela conclut la deuxième partie de cette série, et clôt la dernière section essentiellement théorique. La prochaine partie s'attaquera concrètement à l'examen et à l'analyse de vos métadonnées BigQuery.