Guia introdutório sobre otimizações de custo e performance no BigQuery
Continuando
Na primeira parte desta série, falei sobre alguns pré-requisitos e itens operacionais necessários para rodar queries e tocar o processo de otimização.
Nesta parte, vou abordar os erros mais comuns na escrita de queries que acabam custando mais dinheiro aos nossos clientes ou gerando problemas de performance. Encare isto como um guia de referência para consultar lá na frente, quando for corrigir o que encontrar nas próximas partes da série.

Se você já está a fim de colocar a mão na massa nas otimizações, pode pular direto para a parte 3 desta série, onde compartilho algumas queries e mostro como usá-las.
Erros comuns em queries que aumentam custo e complexidade
Antes de partir para as queries que vão entregar os dados de fato, quero mostrar alguns exemplos de erros muito comuns que vemos na escrita de queries no BigQuery — erros que podem fazer com que elas demorem mais do que o necessário e, quase sempre, também fiquem mais caras.
Tudo isso está documentado online, mas quero reunir aqui os mais frequentes que vemos na DoiT International, no dia a dia com centenas de clientes.
SELECT \*
Essa é provavelmente a maior fonte de custos extras, tanto em dinheiro gasto quanto em quantidade de clientes que cometem o erro.
Existem alguns cenários em que você realmente precisa selecionar todas as colunas de uma tabela ou view, mas, na maior parte das vezes, isso é desnecessário e só serve para escanear dados em excesso. Esses cenários costumam ocorrer quando você já filtrou o escopo de uma view, usou uma Common-Table-Expression (CTE) para chegar nos dados necessários, ou quando a tabela é pequena — como uma fact table em que todos os dados são realmente necessários, só para citar dois casos comuns.
Fora desses poucos cenários, você nunca deve fazer um SELECT * nos seus dados. Como o BigQuery cobra com base na quantidade de dados escaneados nas queries, selecione sempre apenas o que precisa para minimizar esse custo.
Por exemplo: se você tem uma tabela de 5 TB com 5 colunas (supondo que cada coluna contenha a mesma quantidade de dados, ou seja, 1 TB cada) e precisa escaneá-la inteira, um SELECT * nessa tabela vai custar US$ 25 só nessa query. Mas, se você fizer um SELECT apenas nas 2 colunas necessárias, o custo cai para US$ 10. Pode parecer pouco, mas se essa query roda 100 vezes por dia, a conta pesa rápido.
Aqui vai um exemplo do que NÃO fazer com um SELECT * (tabela de 1,6 TB):
SELECT *
FROM `bigquery-public-data.crypto_bitcoin.transactions`
Joins desnecessários ou grandes demais
No BigQuery e em outros data warehouses focados em estratégia OLAP, a melhor prática é desnormalizar os schemas do banco. Isso, na prática, "achata" as estruturas de dados e reduz a quantidade de joins necessários em comparação a um banco relacional tradicional.
O motivo é que uma operação de join é bem mais lenta no BigQuery do que num banco tradicional, pela forma como os dados são armazenados no sistema subjacente. Para colocar em perspectiva: ler a próxima coluna de uma tabela é muito mais rápido do que ir até outra tabela em disco, filtrar os dados, trazer os registros correspondentes e então entregar o resultado do join. É bem mais leitura e processamento do que simplesmente ter os dados (ou uma cópia) na mesma tabela.
Nem precisa dizer que juntar tabelas grandes consome mais tempo e escaneia mais dados, então evitar isso e guardar a coluna necessária na própria tabela economiza um tempão de processamento e bastante custo de scan.
Por fim, ainda sobre joins desnecessários, há o conceito de "self-join", em que os dados da tabela podem precisar ser separados em janelas de tempo ou ordenados internamente em linhas duplicadas (chamado de ranking em muitos bancos de dados). Esse é um processo MUITO lento, então a recomendação geral é não fazer isso e usar as window ou analytic functions oferecidas pelo BigQuery.
Como muitos clientes nunca usam essa funcionalidade, segue um exemplo de ranqueamento de IDs de jobs duplicados na sua view INFORMATION_SCHEMA:
SELECT
query,
job_id AS jobId,
COALESCE(total_bytes_billed, 0) AS totalBytesBilled,
ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnk
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
Cross Joins
Muita gente vinda de um RDBMS e com background em engenharia de software pode estar lendo esta seção de sobrancelha levantada, pensando: alguém realmente usa cross join????
Acredite ou não, há, sim, usos para eles (principalmente em cenários de dados puramente baseados em conjuntos) e, no BigQuery, existem alguns casos em que são obrigatórios. O exemplo clássico é o unnesting de arrays em linhas, uma operação bastante comum no trabalho com dados analíticos.
Aqui vai um exemplo extraído de queries que aparecem mais à frente na série, mostrando o unnesting de uma coluna do tipo RECORD com um CROSS JOIN:
SELECT
user_email AS user,
job_id AS jobId,
tables.project_id AS projectId,
tables.dataset_id AS datasetId,
tables.table_id AS tableId,
ROW_NUMBER() OVER (PARTITION BY job_id ORDER BY end_time DESC) as _rnk
FROM
`<project-name>`.`<region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
CROSS JOIN
UNNEST(referenced_tables) AS tables
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 14 DAY)
AND CURRENT_TIMESTAMP()
O problema aparece quando, muitas vezes, alguém coloca o cross join como a operação mais interna da query, puxando MUITO mais dados do que realmente vai para a saída. Ou seja, você é cobrado para ler um monte de dados que provavelmente serão descartados em uma fase posterior — mas, mesmo descartados depois, o BigQuery cobra por eles, já que precisou escanear e ler.
Dito isso, o analisador de queries do BigQuery vem evoluindo na detecção desses casos e ajustando os planos de execução para mitigar o problema. Ao longo da escrita destes artigos e nas demos para clientes, vi melhorias acontecendo durante 2022, com alguns casos sendo identificados e reordenados para evitar esse cenário. Mas, como sempre, nunca presuma que o sistema vai corrigir más práticas de querying.
A regra de ouro é fazer seus cross joins sempre no ponto mais externo possível da query. Assim, você reduz a quantidade de dados lidos antes do cross join, diminuindo a contagem de slots e o volume de dados que o BigQuery vai cobrar.
Common Table Expressions (CTEs)
As Common Table Expressions, ou CTEs, são recursos sensacionais que simplificam imensamente o código SQL.
Para quem não conhece, são, basicamente, tabelas temporárias em memória que existem apenas durante o job atual. São uma ótima maneira de quebrar códigos SQL que estão se enrolando em vários níveis de subqueries.
Vale notar que elas servem mais para legibilidade do que para performance, já que não materializam os dados e são reexecutadas se forem usadas várias vezes. Bons exemplos disso são todas as queries do repositório no GitHub desta série, escritas muito mais com foco em legibilidade e facilidade de modificação do que em performance.
Dito isso, o maior problema de custo e performance que vemos é usar uma CTE numa query e referenciá-la várias vezes — fazendo com que a CTE seja executada várias vezes. Resultado: você é cobrado pela leitura dos dados várias vezes.
Mais uma vez, o analisador de queries do BigQuery está evoluindo nesse ponto e, às vezes, detecta esse comportamento e corrige o plano de execução para rodar a CTE só uma vez. Numa checagem final durante a escrita deste caso de uso, observei em várias execuções que algumas queries rodavam as CTEs apenas uma vez e outras rodavam várias.
Não usar partições nas cláusulas WHERE
As partições são uma das funcionalidades mais importantes do BigQuery para reduzir custos e otimizar a performance de leitura. Mas, em muitos casos, elas simplesmente não são usadas, e muito dinheiro acaba indo embora em queries que não precisariam custar tanto.
Uma partição divide uma tabela em disco em diferentes partições físicas, com base em um valor inteiro ou timestamp/datetime/date de uma coluna específica. Assim, quando você lê dados de uma tabela particionada e especifica um intervalo nessa coluna, o BigQuery só precisa escanear as partições que contêm os dados daquele intervalo, e não a tabela inteira — o famoso table scan no mundo dos bancos de dados.
Por exemplo: na query a seguir, estou puxando o total de bytes faturados de todas as queries dos últimos 14 dias. A JOBS_BY_PROJECT é particionada pela coluna creation_time (a documentação do schema está aqui) e, ao rodar contra uma tabela de exemplo de cerca de 17 GB no total, processa 884 MB de dados.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
Em contraste, a query a seguir usa a coluna start_time, que não é particionada — embora costume estar a frações de segundo do valor de creation_time — rodando contra o mesmo dataset de exemplo, e processa 15 GB de dados. O motivo é que ela escaneia a tabela inteira para extrair os valores pedidos.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
Como dá para ver, a diferença é considerável mesmo num dataset menor: a primeira query custa cerca de US$ 0,004, e a segunda, cerca de US$ 0,75 — ou seja, neste caso, sai cerca de 21x mais caro não usar uma coluna particionada da forma certa.
Em performance, a primeira query levou cerca de 2 segundos para rodar, e a segunda, cerca de 5 segundos. Não é muita coisa numa tabela tão pequena, mas, escalando para uma tabela de vários TB, isso pode virar facilmente uma diferença de vários minutos por execução.
Uso de views complexas demais
Esse é um problema muito comum que vai bem além das paredes sagradas do BigQuery: a criação de views complexas que degradam a performance. O BigQuery, como a maioria de seus parentes pseudo e verdadeiramente relacionais, suporta um construto chamado view, que é, basicamente, uma query que se disfarça de tabela para facilitar consultas.
São extremamente úteis para abstrair lógica, esconder colunas de usuários que não precisam vê-las e por inúmeros outros motivos. Mas, junto com o lado bom, vem o ruim: os resultados de uma query não são materializados, ou seja, não ficam armazenados em disco. Assim, cada vez que ela é consultada, o motor de queries pode precisar recalcular os resultados para entregar à query chamadora.
Logo, se a view contém computações pesadas e elas são executadas a cada consulta, isso adiciona um impacto considerável de performance à query chamadora. É uma boa ideia avaliar quanta lógica há em cada view e, se estiver complicada demais, talvez seja melhor pré-calcular em outra tabela ou colocar em uma materialized view para melhorar a performance.
Inserts pequenos
Muitas vezes há um único registro ou um número pequeno deles que precisam ser inseridos em uma tabela, especialmente em aplicações do tipo streaming. O problema é que o BigQuery tem isso no nome: Big — e ele gosta de processar grandes blocos de dados de uma vez só.
Inserts pequenos, em geral, consomem o mesmo tempo e uso de slots para inserir 1 KB que para inserir 10 MB. Ou seja, fazer 1.000 inserts de uma linha de 1 KB pode consumir até 1.000 vezes mais tempo de slot do que um único insert de 10 MB de linhas.
O ideal é agrupar os dados em lotes e inseri-los como batch, em vez de fazer vários inserts pequenos. Isso vale também para operações de streaming: evite usar Streaming Inserts e simplesmente agrupe os dados, inserindo-os com um prazo de chegada.
Uso excessivo de comandos DML
Esse é um problemão que costuma surgir quando alguém trata o BigQuery como um sistema RDBMS tradicional e simplesmente recria os dados à vontade.
Três exemplos bem comuns têm a estrutura assim:
DELETE TABLE <table-name> IF EXISTS;
CREATE TABLE <table-name> …;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
TRUNCATE TABLE <table-name>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
DELETE FROM TABLE <table-name> WHERE <condition>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
Rodar isso em um RDBMS como SQL Server ou MySQL seria uma operação relativamente barata e, fora de um cenário de data warehouse, é provavelmente feito com bastante frequência.
Já no BigQuery, essas queries têm performance bem ruim e devem ser evitadas no uso regular. Os comandos DML do BigQuery são notoriamente lentos, porque ele simplesmente não é otimizado para isso, ao contrário de um RDBMS tradicional, em que esses comandos são otimizados.
Em vez de fazer algo assim, considere adotar um "modelo aditivo", em que novas linhas são inseridas com um timestamp para indicar que são as mais recentes, removendo periodicamente as linhas antigas, caso o histórico não seja necessário. Lembre-se: o BigQuery é um data warehouse afinado para análise, então é mais adequado para trabalhar com dados existentes do que para modificá-los de forma transacional.
Uma boa forma de ilustrar isso é criar a mesma tabela no seu RDBMS e no BigQuery, inserir uma grande quantidade de dados de exemplo e olhar o plano de execução de um comando MERGE ou UPDATE (no BigQuery, esse será o query plan). Olhe os planos: você vai notar que o BigQuery leva muito mais tempo na seção de DDL ou de JOIN (no caso do MERGE) e, dependendo do comando, pode até ter várias etapas.
Para ilustrar, estou rodando um comando merge bem simples para inserir quando não há correspondência, na tabela transactions do dataset público crypto_bitcoin. Estou fazendo merge de um subconjunto da tabela com um ano de transações com o conjunto completo (cerca de 400 GB e 1,54 TB, respectivamente). Neste exemplo, mostrado abaixo, dá para notar que ele precisa fazer bastante reparticionamento de dados entre as fases e que o grosso do tempo está em uma operação de JOIN. Vale lembrar que, se o merge fosse mais complicado, essas fases certamente cresceriam ainda mais e teriam mais etapas de reparticionamento.
Aqui está o plano de execução resultante (dividido em duas capturas, já que é grande demais para uma só, deixando o ponto bem claro):
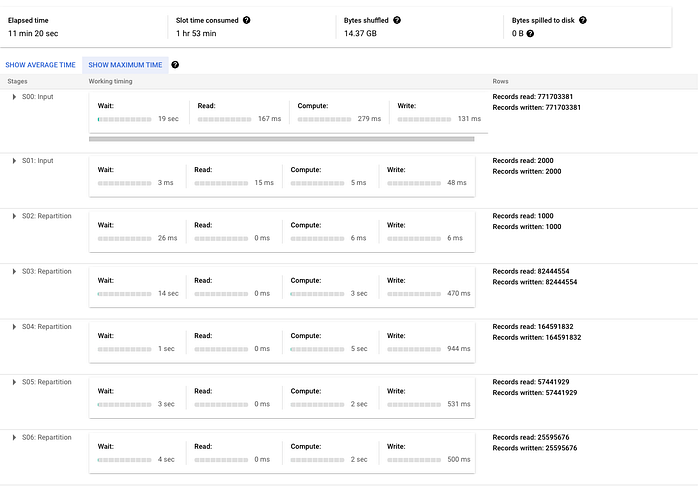
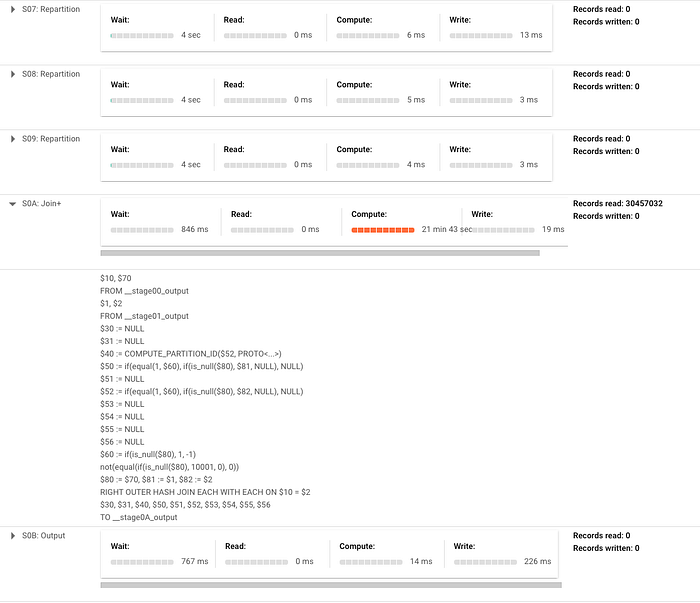
A seguir
Isso encerra a segunda parte desta série e é a última seção com trabalho majoritariamente teórico. Na próxima, vamos, de fato, examinar e analisar os metadados do seu BigQuery.