Ein Leitfaden zur Optimierung von Kosten und Performance in BigQuery
Weiter geht's
Im ersten Teil dieser Serie habe ich einige Grundlagen sowie operative Schritte beschrieben, die nötig sind, um Queries auszuführen und den Optimierungsprozess überhaupt anzustoßen.
In diesem Teil widme ich mich den häufigsten Fehlern beim Schreiben von Queries, die unsere Kunden am Ende mehr Geld kosten oder Performance-Probleme verursachen. Verstehen Sie diesen Teil als Nachschlagewerk – in den späteren Teilen werde ich darauf zurückgreifen, wenn es darum geht, die hier beschriebenen Probleme zu beheben.

Wenn Sie es kaum erwarten können, selbst Hand anzulegen, springen Sie direkt zu Teil 3 dieser Serie. Dort stelle ich konkrete Queries vor und zeige, wie Sie sie einsetzen.
Häufige Query-Fehler, die Kosten und Komplexität nach oben treiben
Bevor ich zu den Queries komme, die Ihnen die eigentlichen Daten liefern, möchte ich einige sehr verbreitete Fehler beim Schreiben von BigQuery-Queries zeigen. Solche Fehler führen dazu, dass Queries länger laufen als nötig – und fast immer auch mehr kosten als nötig.
All das ist online dokumentiert, aber ich möchte hier die häufigsten Fälle zusammenstellen, die wir bei DoiT International in der täglichen Arbeit mit hunderten Kunden sehen.
SELECT \*
Das ist vermutlich die größte Ursache für Mehrkosten – sowohl gemessen am ausgegebenen Geld als auch an der Zahl der Kunden, die diesen Fehler machen.
Es gibt Szenarien, in denen Sie tatsächlich alle Spalten einer Tabelle oder eines Views auswählen müssen, doch meistens ist das überflüssig und scannt nur unnötig viel Daten. Solche Fälle sind etwa: Sie haben den Scope eines Views bereits eingeschränkt oder per Common Table Expression (CTE) auf die benötigten Daten reduziert, oder Sie arbeiten mit einer kleinen Tabelle wie einer Faktentabelle, in der ohnehin sämtliche Daten benötigt werden – um nur zwei gängige Beispiele zu nennen.
Außerhalb dieser wenigen Szenarien sollten Sie niemals ein SELECT * auf Ihre Daten ausführen. Da BigQuery nach der Datenmenge abrechnet, die Ihre Queries scannen, sollten Sie immer nur das auswählen, was Sie wirklich brauchen, um diese Kosten gering zu halten.
Beispiel: Angenommen, Sie haben eine 5 TB große Tabelle mit 5 Spalten (jede Spalte enthält gleich viel Daten, also je 1 TB) und müssen alles scannen. Ein SELECT * auf diese Tabelle kostet Sie 25 USD allein für diese eine Query. Wählen Sie hingegen nur die 2 Spalten per SELECT aus, die Sie tatsächlich benötigen, kostet die Query nur 10 USD. Das klingt wenig – aber wenn diese Query 100-mal am Tag läuft, summiert sich das schnell.
Hier ein Beispiel, wie man es mit SELECT * NICHT machen sollte (Tabelle mit 1,6 TB):
SELECT *
FROM `bigquery-public-data.crypto_bitcoin.transactions`
Unnötige oder zu große Joins
In BigQuery und anderen Data Warehouses, die auf einen OLAP-Ansatz setzen, lautet die Best Practice, die Schemas in der Datenbank zu denormalisieren. Das flacht die Datenstrukturen ab und reduziert die Anzahl der nötigen Joins gegenüber einer klassischen relationalen Datenbank.
Der Grund: Eine Join-Operation ist in BigQuery deutlich langsamer als in einer klassischen Datenbank, was an der Art liegt, wie die Daten im darunterliegenden System abgelegt werden. Zur Einordnung: Die nächste Spalte in einer Tabelle zu lesen, geht viel schneller, als eine andere Tabelle auf der Disk anzusprechen, deren Daten zu filtern, die passenden Datensätze zu holen und das Ergebnis zusammenzuführen. Das sind deutlich mehr Lese- und Verarbeitungsschritte, als wenn die Daten (oder eine Kopie davon) bereits in derselben Tabelle liegen.
Es liegt auf der Hand, dass das Joinen großer Tabellen mehr Zeit kostet und mehr Daten scannt. Wenn Sie das vermeiden und die benötigte Spalte direkt in derselben Tabelle ablegen, sparen Sie immens viel Verarbeitungszeit und Scan-Kosten.
Ein letzter Punkt zu unnötigen Joins ist das Konzept des "Self-Joins", bei dem Daten aus derselben Tabelle in Zeitfenster aufgeteilt oder doppelte Zeilen intern in eine Reihenfolge gebracht werden müssen (in vielen Datenbanksystemen Ranking genannt). Das ist ein SEHR langsamer Prozess. Die generelle Empfehlung lautet daher: nicht so machen, sondern stattdessen die Window- bzw. Analyse-Funktionen von BigQuery nutzen.
Da viele Kunden diese Funktionalität nie verwenden, hier ein Beispiel: Ranking doppelter Job-IDs in Ihrem INFORMATION_SCHEMA-View:
SELECT
query,
job_id AS jobId,
COALESCE(total_bytes_billed, 0) AS totalBytesBilled,
ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnk
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
Cross Joins
Wer aus der RDBMS-Welt und einem Software-Engineering-Hintergrund kommt, schaut diesen Abschnitt vielleicht mit hochgezogener Augenbraue an und denkt: Cross Joins benutzt wirklich jemand????
Ob Sie es glauben oder nicht – es gibt sinnvolle Anwendungsfälle (meist in rein mengenbasierten Datenszenarien), und in BigQuery sind sie für einige Aufgaben sogar zwingend nötig. Das Paradebeispiel ist das Entschachteln (Unnesting) von Arrays in Zeilen – eine durchaus übliche Operation bei analytischen Daten.
Hier ein Beispiel aus einer Query, die später in der Serie auftaucht. Es zeigt das Unnesting einer Spalte vom Typ RECORD per CROSS JOIN:
SELECT
user_email AS user,
job_id AS jobId,
tables.project_id AS projectId,
tables.dataset_id AS datasetId,
tables.table_id AS tableId,
ROW_NUMBER() OVER (PARTITION BY job_id ORDER BY end_time DESC) as _rnk
FROM
`<project-name>`.`<region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
CROSS JOIN
UNNEST(referenced_tables) AS tables
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 14 DAY)
AND CURRENT_TIMESTAMP()
Das Problem: Häufig wird der Cross Join als innerste Operation der Query ausgeführt – und damit weit mehr Daten hineingezogen, als am Ende ausgegeben werden. Sie zahlen also für das Lesen einer großen Datenmenge, die in einer späteren Phase der Query wahrscheinlich wieder verworfen wird. Doch selbst wenn die Daten später verworfen werden, stellt BigQuery sie Ihnen in Rechnung, weil sie gescannt und gelesen werden mussten.
Dabei wird der Query-Analyzer von BigQuery immer besser darin, solche Fälle zu erkennen und die Ausführungspläne entsprechend anzupassen. Beim Schreiben dieser Artikel und in Kunden-Demos habe ich im Verlauf von 2022 spürbare Verbesserungen beobachtet: In einigen Fällen wurden solche Konstellationen erkannt und umsortiert, um das Problem zu vermeiden. Aber wie immer gilt: Verlassen Sie sich nie darauf, dass die Engine schlechtes Query-Verhalten korrigiert.
Faustregel: Setzen Sie Cross Joins immer so weit außen in der Query wie möglich. So reduzieren Sie die Datenmenge, die vor dem Cross Join gelesen wird – und damit Slot-Verbrauch und abgerechnete Datenmenge.
Common Table Expressions (CTEs)
Common Table Expressions, kurz CTEs, sind großartige Konstrukte, die SQL-Code erheblich vereinfachen.
Für alle, die damit nicht vertraut sind: Es handelt sich im Prinzip um temporäre In-Memory-Tabellen, die nur für den aktuellen Job existieren. Sie sind ein hervorragendes Mittel, um SQL-Code aufzubrechen, der sich sonst in mehreren Ebenen von Subqueries verlieren würde.
Beachten Sie aber: CTEs dienen primär der Lesbarkeit, nicht der Performance. Sie materialisieren die Daten nicht und werden bei mehrfacher Nutzung jedes Mal erneut ausgeführt. Gute Beispiele dafür finden Sie in allen Queries des GitHub-Repositorys zu dieser Serie – sie sind viel stärker auf Lesbarkeit und einfache Anpassbarkeit ausgelegt als auf Performance.
Vor diesem Hintergrund ist das größte Kosten- und Performance-Problem, das wir sehen, dass eine CTE in einer Query mehrfach referenziert und damit auch mehrfach ausgeführt wird. Das heißt: Sie zahlen mehrfach für das Lesen derselben Daten.
Auch hier wird der BigQuery-Query-Analyzer besser: Manchmal erkennt er dieses Verhalten und passt den Ausführungsplan so an, dass die CTE nur einmal läuft. Ein abschließender Sanity-Check während der Erstellung dieses Use Cases zeigte: In mehreren Query-Läufen wurden CTEs in einigen Fällen nur einmal, in anderen mehrfach ausgeführt.
Partitionen in WHERE-Klauseln nicht nutzen
Partitionen gehören zu den wichtigsten Funktionen von BigQuery, um Kosten zu senken und die Lese-Performance zu optimieren. Trotzdem werden sie in vielen Fällen nicht genutzt – und es wird viel Geld für Queries ausgegeben, das gar nicht nötig wäre.
Eine Partition zerlegt eine Tabelle auf der Disk in unterschiedliche physische Partitionen, basierend auf einem Integer- oder Timestamp/Datetime/Date-Wert in einer bestimmten Spalte. Wenn Sie aus einer partitionierten Tabelle lesen und einen Bereich auf dieser Spalte angeben, werden nur die Partitionen gescannt, die Daten in diesem Bereich enthalten – nicht die gesamte Tabelle (in der Datenbankwelt auch Table Scan genannt).
Beispiel: In der folgenden Query lese ich die gesamten abgerechneten Bytes für alle Queries der letzten 14 Tage aus. Die Tabelle JOBS_BY_PROJECT ist nach der Spalte creation_time partitioniert (die Schema-Doku finden Sie hier). Ausgeführt gegen eine Beispieltabelle mit einer Gesamtgröße von rund 17 GB, verarbeitet die Query 884 MB an Daten.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
Die folgende Query nutzt im Gegensatz dazu die Spalte start_time, die nicht partitioniert ist, aber meist nur Sekundenbruchteile vom creation_time-Wert entfernt liegt. Ausgeführt gegen denselben Beispieldatensatz wie oben, verarbeitet sie 15 GB an Daten. Der Grund: Sie scannt die gesamte Tabelle, um die gewünschten Werte herauszuziehen.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
Wie man sieht, ist der Unterschied selbst auf einem kleineren Datensatz beträchtlich: Die erste Query kostet etwa 0,004 USD, die zweite rund 0,75 USD. In diesem Fall ist es also etwa 21-mal teurer, eine partitionierte Spalte nicht richtig zu nutzen.
Auch bei der Performance: Die erste Query lief in etwa 2 Sekunden, die zweite in etwa 5 Sekunden. Bei einer so kleinen Tabelle ist das nicht viel. Skaliert man das aber auf eine Tabelle im Multi-TB-Bereich, kann der Unterschied pro Query-Lauf schnell mehrere Minuten betragen.
Übermäßig komplexe Views verwenden
Dieses Problem reicht weit über die heiligen Hallen von BigQuery hinaus: komplexe Views, die die Performance verschlechtern. BigQuery unterstützt – wie die meisten seiner pseudo- und echt-relationalen Verwandten – das Konstrukt eines Views: im Kern eine Query, deren Ergebnisse als Tabelle bereitgestellt werden, um das Abfragen zu vereinfachen.
Views sind extrem nützlich, um Logik zu kapseln, bestimmte Spalten vor Nutzern zu verbergen, und für unzählige weitere Zwecke. Doch mit dem Guten kommt auch ein Nachteil: Die Ergebnisse einer Query werden nicht materialisiert, also nicht auf der Disk abgelegt. Bei jedem Aufruf des Views muss die Query-Engine die Ergebnisse unter Umständen neu berechnen, um sie an die aufrufende Query zu liefern.
Enthält der View also rechenintensive Operationen, die bei jedem Aufruf erneut ausgeführt werden, summiert sich das zu einem spürbaren Performance-Hit für die aufrufende Query. Es lohnt sich daher, zu prüfen, wie viel Logik in einem View steckt. Ist er zu komplex, ist es oft besser, das Ergebnis vorab in eine andere Tabelle zu materialisieren oder einen Materialized View zu nutzen, um die Performance zu verbessern.
Small Inserts
Häufig müssen einzelne oder wenige Datensätze in eine Tabelle eingefügt werden – besonders bei Streaming-artigen Anwendungen. Das Problem: BigQuery trägt es schon im Namen – Big. Es verarbeitet bevorzugt große Datenblöcke auf einmal.
Small Inserts brauchen in der Regel genauso viel Zeit und Slot-Kapazität, ob Sie 1 KB oder 10 MB einfügen. 1.000 Inserts mit je 1 KB können also bis zu 1.000-mal so viel Slot-Verbrauchszeit kosten wie ein einziger Insert mit 10 MB Zeilen.
Besser ist es, Daten zu bündeln und als Batch einzufügen, statt zahlreiche kleine Inserts abzusetzen. Das gilt auch für Streaming-Operationen: Verzichten Sie nach Möglichkeit auf Streaming Inserts, sammeln Sie Ihre Daten und fügen Sie sie gebündelt mit einer Eintreff-Deadline ein.
Übermäßiger Einsatz von DML-Statements
Das ist ein großes Problem, das vor allem dann auftritt, wenn jemand BigQuery wie ein klassisches RDBMS behandelt und Daten beliebig neu erzeugt.
Drei Paradebeispiele, die wir relativ häufig sehen, sind so aufgebaut:
DELETE TABLE <table-name> IF EXISTS;
CREATE TABLE <table-name> …;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
TRUNCATE TABLE <table-name>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
DELETE FROM TABLE <table-name> WHERE <condition>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
Auf einem RDBMS wie SQL Server oder MySQL wären solche Operationen relativ günstig und werden außerhalb von Data-Warehouse-Setups durchaus oft eingesetzt.
In BigQuery hingegen sind das sehr ineffiziente Queries, die im Regelbetrieb vermieden werden sollten. BigQuery-DML-Statements sind notorisch langsam, denn die Engine ist – anders als ein klassisches RDBMS – schlicht nicht dafür optimiert.
Statt so vorzugehen, sollten Sie ein "additives Modell" in Erwägung ziehen: Neue Zeilen werden mit einem Timestamp eingefügt, der die jeweils aktuellste Version markiert; ältere Zeilen werden bei Bedarf periodisch entfernt, sofern keine Historie benötigt wird. Denken Sie daran: BigQuery ist ein Data Warehouse, das auf Analytik getrimmt ist – also stärker auf das Arbeiten mit bestehenden Daten ausgelegt als auf transaktionale Änderungen.
Das lässt sich gut so veranschaulichen: Legen Sie dieselbe Tabelle in Ihrem RDBMS und in BigQuery an, fügen Sie eine größere Menge Beispieldaten ein und schauen Sie sich den Ausführungsplan eines MERGE- oder UPDATE-Statements an (in BigQuery ist das der Query Plan). Sie werden feststellen, dass BigQuery deutlich mehr Zeit für den DDL- bzw. JOIN-Teil (bei MERGE-Statements) der Query benötigt – und je nach Statement sogar mehrere Schritte ausführt.
Zur Veranschaulichung lasse ich ein sehr einfaches MERGE-Statement laufen, das auf der Tabelle transactions im öffentlichen Datensatz crypto_bitcoin einfügt, wenn kein Match gefunden wird. Ich merge eine Teilmenge der Tabelle mit einem Jahr Transaktionen in den vollständigen Datensatz (rund 400 GB bzw. 1,54 TB). Im Beispiel unten sieht man, dass viele Repartitionen zwischen den Phasen nötig sind und der Großteil der Zeit auf eine JOIN-Operation entfällt. Bei einem komplexeren Merge würden diese Phasen noch deutlich umfangreicher und es kämen weitere Repartitionierungs-Phasen hinzu.
Hier der ausgegebene Ausführungsplan (in zwei Screenshots aufgeteilt, da er ziemlich groß ist – aber genau das untermauert den Punkt):
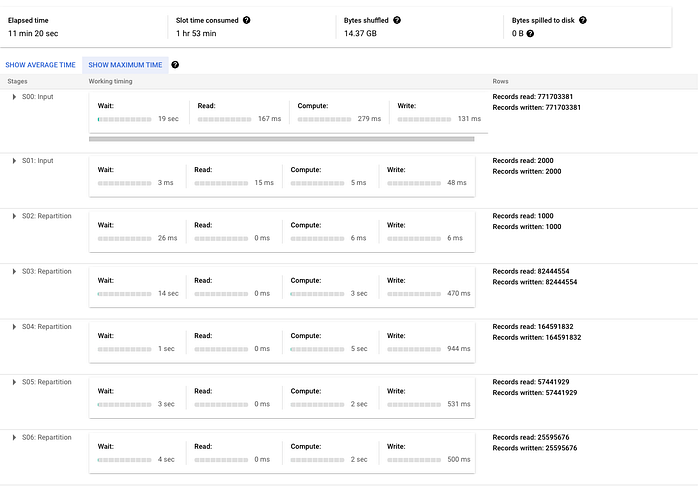
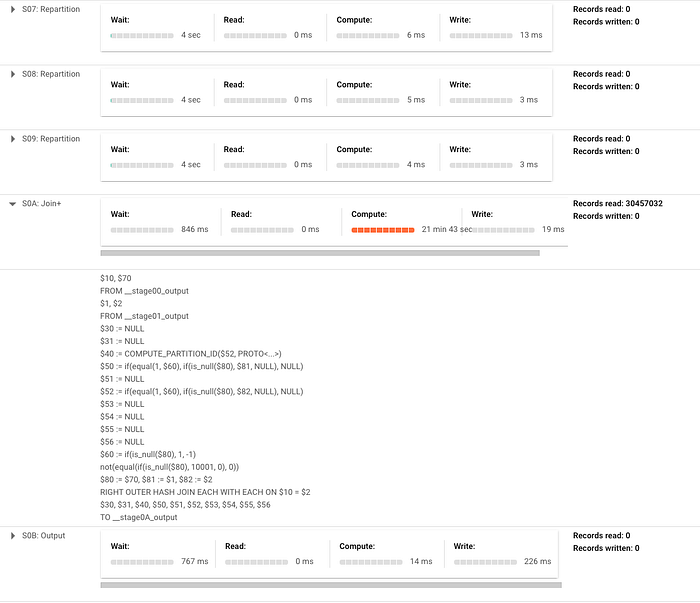
Ausblick
Damit endet der zweite Teil dieser Serie und zugleich der weitgehend theoretische Block. Im nächsten Teil schauen wir uns Ihre BigQuery-Metadaten konkret an und werten sie aus.