Guía introductoria para optimizar costos y rendimiento en BigQuery
Sigamos
En la primera parte de esta serie repasé algunos conocimientos previos y temas operativos necesarios para ejecutar consultas y arrancar con el proceso de optimización.
En esta parte voy a cubrir los errores más comunes al escribir consultas, esos que terminan costándole más dinero a nuestros clientes o que generan problemas de rendimiento. Tómalo como una guía de referencia para las próximas entregas, donde veremos cómo solucionar lo que vayas detectando.

Si tienes ganas de poner manos a la obra con las optimizaciones, salta directo a la parte 3 de la serie, donde te daré algunas consultas y luego veremos cómo usarlas.
Errores comunes en consultas que aumentan costos y complejidad
Antes de meterme con las consultas que te darán los datos reales, quiero mostrar algunos ejemplos de errores muy frecuentes al escribir consultas en BigQuery. Estos errores hacen que las consultas tarden más de lo necesario y, casi siempre, salgan más caras.
Todos están documentados en línea, pero quiero incluir aquí los más habituales que vemos en DoiT International al trabajar a diario con cientos de clientes.
SELECT \*
Esta es probablemente la mayor causa de costos extra, tanto por el dinero que se gasta como por la cantidad de clientes que la cometen.
Hay algunos escenarios en los que necesitarás seleccionar todas las columnas de una tabla o vista, pero la mayoría de las veces es innecesario y solo se está escaneando información de más. Esos escenarios suelen darse cuando ya filtraste el alcance de una vista, cuando usaste una Common-Table-Expression (CTE) para reducir los datos al mínimo necesario o cuando tienes una tabla pequeña, como una tabla de hechos, donde se necesita toda la información, por mencionar dos casos comunes.
Fuera de esos pocos escenarios, nunca deberías hacer un SELECT * sobre tus datos. Como BigQuery cobra según la cantidad de datos que se escanean en tus consultas, conviene seleccionar siempre solo lo que necesitas para minimizar el costo.
Por ejemplo, si tienes una tabla de 5 TB con 5 columnas (asumiendo que cada columna contiene la misma cantidad de datos, es decir, 1 TB cada una) y necesitas escanearla por completo: si haces un SELECT * sobre esta tabla, esa sola consulta costará $25, pero si solo haces un SELECT sobre las 2 columnas que necesitas, la consulta costará apenas $10. Puede no parecer mucho, pero si la ejecutas 100 veces al día, ese número se acumula bastante rápido.
Aquí va un ejemplo de lo que NO debes hacer con un SELECT * (tabla de 1.6 TB):
SELECT *
FROM `bigquery-public-data.crypto_bitcoin.transactions`
Joins innecesarios o demasiado grandes
En BigQuery y otros data warehouses enfocados en una estrategia OLAP, la mejor práctica es desnormalizar los esquemas de la base de datos. Esto básicamente "aplana" las estructuras de datos y reduce la cantidad de joins necesarios respecto de una base de datos relacional tradicional.
El motivo es que una operación de join dentro de BigQuery es mucho más lenta que en una base de datos tradicional, debido a cómo se almacenan los datos en el sistema subyacente. Para ponerlo en perspectiva: leer la siguiente columna de una tabla es muchísimo más rápido que ir a otra tabla en disco, filtrar los datos, traer los registros coincidentes y después servir los datos unidos. Son muchas más lecturas y procesamiento de datos que tener simplemente la información (o una copia) en la misma tabla.
No hace falta decir que unir tablas grandes va a tomar más tiempo y escanear más datos, así que evitar este paso y guardar la columna que necesitas en la misma tabla ahorra muchísimo tiempo de procesamiento y costos de escaneo.
Por último, dentro de los joins innecesarios está el concepto de "self-join", donde los datos de la tabla podrían tener que dividirse en ventanas de tiempo o establecer un orden interno sobre filas duplicadas (lo que en muchos sistemas de bases de datos se llama ranking). Es un proceso MUY lento, así que la recomendación general es evitarlo y, en su lugar, usar las funciones de ventana o analíticas que ofrece BigQuery.
Para dar un ejemplo, ya que muchos clientes nunca llegan a usar esta funcionalidad, aquí va un caso de cómo asignar ranking a job IDs duplicados en tu vista INFORMATION_SCHEMA:
SELECT
query,
job_id AS jobId,
COALESCE(total_bytes_billed, 0) AS totalBytesBilled,
ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnk
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
Cross Joins
Mucha gente que viene de un RDBMS y tiene formación en ingeniería de software estará leyendo esta sección con una ceja levantada y pensando: ¿en serio hay quien usa cross joins?
Aunque no lo creas, sí tienen sus usos (sobre todo en escenarios de datos puramente basados en conjuntos), y en BigQuery hay algunas cosas para las que son indispensables. El ejemplo más claro es desanidar arrays en filas, una operación bastante común al trabajar con datos analíticos.
Aquí va un ejemplo extraído de algunas consultas que usaremos más adelante en la serie, mostrando el desanidado de una columna de tipo RECORD usando un CROSS JOIN:
SELECT
user_email AS user,
job_id AS jobId,
tables.project_id AS projectId,
tables.dataset_id AS datasetId,
tables.table_id AS tableId,
ROW_NUMBER() OVER (PARTITION BY job_id ORDER BY end_time DESC) as _rnk
FROM
`<project-name>`.`<region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
CROSS JOIN
UNNEST(referenced_tables) AS tables
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 14 DAY)
AND CURRENT_TIMESTAMP()
El problema es que muchas veces, al usarlos, se coloca el cross join como la operación más interna de la consulta, y termina trayendo MUCHA más información de la que se va a entregar como salida. Te están cobrando por leer una cantidad enorme de datos que probablemente se descarten en una fase posterior y, aunque se descarten, BigQuery igual te cobra porque tuvo que escanearlos y leerlos.
Dicho esto, el analizador de consultas de BigQuery cada vez detecta mejor estos casos y ajusta los planes de ejecución para mitigarlos. Mientras escribía estos artículos y hacía demos a clientes, vi mejoras durante el 2022 en las que algunos casos se detectaban y reordenaban para evitar este escenario, pero como siempre, nunca asumas que va a corregir tus malas prácticas de consulta.
La regla de oro es hacer siempre los cross joins en el punto más externo posible de tu consulta. De esta forma se reduce la cantidad de datos que se leen antes del cross join, lo que disminuye el consumo de slots y la cantidad de datos por los que BigQuery te facturará.
Common Table Expressions (CTEs)
Las Common Table Expressions, o CTEs, son herramientas geniales que simplifican muchísimo el código SQL.
Para quienes no las conocen, son básicamente tablas temporales en memoria que existen solo durante el job actual. Son una forma excelente de descomponer código SQL que se va metiendo en varios niveles de subqueries.
Ten en cuenta que se usan más por legibilidad que por rendimiento, ya que no materializan los datos y se vuelven a ejecutar cada vez que se referencian. Buenos ejemplos son todas las consultas del repositorio de GitHub de esta serie, escritas más para legibilidad y facilidad de modificación que para rendimiento.
Dicho eso, el mayor problema de costo y rendimiento que vemos es usar una CTE en una consulta y luego referenciarla varias veces, con lo cual la CTE se ejecuta múltiples veces. Esto significa que se te facturará por leer los datos varias veces.
Una vez más, el analizador de consultas de BigQuery está mejorando en este aspecto y a veces detecta este comportamiento y corrige el plan de ejecución para que se ejecuten una sola vez. Al hacer una verificación final mientras escribía este caso, en varias ejecuciones algunas consultas corrieron las CTEs una sola vez y otras las corrieron varias.
No usar particiones en las cláusulas WHERE
Las particiones son una de las funcionalidades más importantes de BigQuery para reducir costos y optimizar el rendimiento de lectura. Sin embargo, en muchos casos no se utilizan y se gasta un montón de dinero en consultas que no deberían costar tanto.
Una partición divide una tabla en disco en distintas particiones físicas según un valor entero, timestamp, datetime o date de una columna específica. Así, cuando lees datos de una tabla particionada y especificas un rango sobre esa columna, solo se escanean las particiones que contienen los datos de ese rango y no toda la tabla, lo que en el mundo de las bases de datos se conoce como un table scan.
Por ejemplo, en la siguiente consulta saco el total de bytes facturados de todas las consultas de los últimos 14 días. La vista JOBS_BY_PROJECT está particionada por la columna creation_time (la documentación del esquema está aquí) y, ejecutada contra una tabla de muestra de unos 17 GB en total, procesa 884 MB de datos.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
En contraste, la siguiente consulta usa la columna start_time, que no está particionada pero suele estar a fracciones de segundo del valor de creation_time, contra el mismo dataset de muestra, y procesa 15 GB de datos. La razón es que escanea toda la tabla extrayendo los valores solicitados.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT
query,
total_bytes_billed AS totalBytesBilled
FROM
`<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY)
AND CURRENT_TIMESTAMP()
Como se ve, hay una diferencia bastante grande incluso en un dataset pequeño: la primera consulta cuesta unos $0.004 USD y la segunda alrededor de $0.75 USD, así que en este caso resulta unas 21 veces más caro no aprovechar correctamente una columna particionada.
En cuanto al rendimiento, la primera consulta tardó unos 2 segundos en ejecutarse y la segunda unos 5 segundos. No es mucho para una tabla tan chica, pero si escalamos esto a una tabla de varios TB, la diferencia podría ser fácilmente de varios minutos por consulta.
Usar vistas demasiado complicadas
Este es un problema muy común que va mucho más allá de las venerables paredes de BigQuery: crear vistas complejas que degradan el rendimiento. BigQuery, como la mayoría de sus pares pseudo-relacionales y relacionales, soporta un constructo llamado vista, que es básicamente una consulta que disfraza sus resultados como una tabla para facilitar las consultas.
Son extremadamente útiles para abstraer lógica, ocultar columnas a usuarios que no necesitan verlas y un sinfín de otras razones. Pero junto con lo bueno viene lo malo: los resultados no se materializan, es decir, no se almacenan en disco, así que cada vez que se consulta la vista, el motor puede tener que recalcular los resultados para entregárselos a la consulta que la invoca.
Entonces, si la vista contiene cálculos bastante pesados y se ejecutan cada vez que se consulta, eso le agrega un buen golpe de rendimiento a la consulta que la llama. Conviene revisar cuánta lógica hay en cada vista y, si es demasiado compleja, evaluar si sería mejor pre-calcularla en otra tabla o usar una vista materializada para mejorar el rendimiento.
Inserts pequeños
Muchas veces hay que insertar uno o pocos registros en una tabla, especialmente en aplicaciones de tipo streaming. El problema es que BigQuery lo lleva en el nombre: Big, y le gusta procesar grandes bloques de datos a la vez.
Los inserts pequeños suelen tomar casi el mismo tiempo y consumo de slots para insertar 1 KB que para insertar 10 MB. Así que hacer 1,000 inserts de filas de 1 KB puede consumir hasta 1,000 veces más tiempo de slots que un único insert de 10 MB de filas.
Lo mejor es agrupar los datos en lotes e insertarlos como batch en lugar de hacer numerosos inserts pequeños. Esto aplica también a las operaciones de streaming: evita usar Streaming Inserts y simplemente agrupa tus datos en batches, luego insértalos con un deadline de llegada.
Abusar de las sentencias DML
Este es un gran problema que normalmente surge cuando alguien trata a BigQuery como un sistema RDBMS tradicional y recrea datos a discreción.
Tres ejemplos típicos que se ven con relativa frecuencia se estructuran así:
DELETE TABLE <table-name> IF EXISTS;
CREATE TABLE <table-name> …;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
TRUNCATE TABLE <table-name>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
DELETE FROM TABLE <table-name> WHERE <condition>;
INSERT INTO <table-name> (<columns>) VALUES (<values>);
Ejecutar esto en un RDBMS como SQL Server o MySQL sería una operación relativamente económica y bastante frecuente cuando no se usan en un esquema de data warehouse.
En cambio, dentro de BigQuery son consultas con muy mal rendimiento y se deben evitar en uso regular. Las sentencias DML de BigQuery son notoriamente lentas porque el motor no está optimizado para ellas, a diferencia de un RDBMS tradicional donde sí lo está.
En lugar de hacer algo así, considera usar un "modelo aditivo" donde se insertan filas nuevas con un timestamp que indica que es la última versión y, periódicamente, se eliminan las filas antiguas si no se necesita el historial. Recuerda que BigQuery es un data warehouse afinado para analítica, así que está más orientado a trabajar con datos existentes que a modificarlos de manera transaccional.
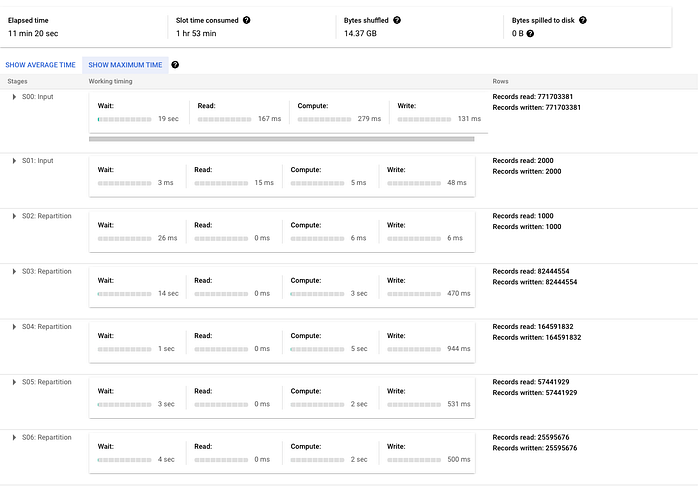
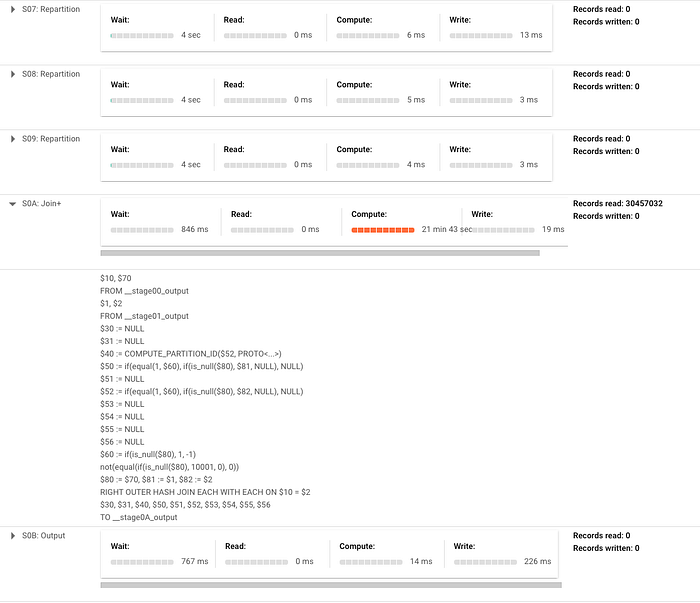
Una buena forma de ilustrarlo es crear la misma tabla en tu RDBMS y en BigQuery, insertar una gran cantidad de datos de muestra y revisar el plan de ejecución de una sentencia MERGE o UPDATE (en BigQuery será el query plan). Al mirar los planes notarás que BigQuery toma mucho más tiempo en la sección DDL o JOIN (en el caso de los MERGE) y, según la sentencia, hasta puede tener varios pasos.
Para ilustrarlo, estoy ejecutando una sentencia merge muy simple para insertar cuando no haya coincidencia en la tabla transactions del dataset público crypto_bitcoin. Hago merge de un subconjunto de la tabla, equivalente a un año de transacciones, contra el conjunto completo (unos 400 GB y 1.54 TB respectivamente). En este ejemplo, que se muestra abajo, notarás que tiene que hacer mucho reparticionamiento de datos entre fases y que el grueso del tiempo está en una operación de JOIN. Ten en cuenta que si fuera un merge más complejo, estas fases se expandirían aún más y habría más fases de reparticionamiento.
Aquí está el plan de ejecución generado (dividido en dos capturas porque es bastante grande, justamente para reforzar el punto):
Lo que viene
Con esto cierra la segunda parte de la serie y la última sección con un enfoque mayormente teórico. La próxima entrega se va a centrar en analizar de verdad la metadata de tu BigQuery.