
本記事では、BigQuery環境を把握するための複数のアプローチを比較し、柔軟性を最大限に引き出すカスタムPythonスクリプトをご紹介します。
進化のスピードが速いデータ分析の世界において、Google BigQueryは膨大なデータセットに対して超高速なSQLクエリを実行できる、強力なサーバーレス型データウェアハウスとして際立っています。データサイエンティスト、データエンジニア、アナリティクスのエキスパート、いずれの立場であっても、BigQueryの幅広い機能を使いこなしていく過程は、まるで隠された宝物を掘り当てるような体験になりがちです。組織の成長に合わせてBigQueryの利用範囲も広がっていくと、多くのユーザーが直面する課題のひとつが、さまざまなスコープにまたがるテーブルやデータセットを効率よく一覧化することです。
本記事では、BigQueryでテーブルとデータセットを一覧化するさまざまな方法をご紹介します。最終的なゴールは、組織全体にわたってこれらの資産を一覧化することにあり、その過程で各アプローチに内在する制約も明らかにしていきます。
基本的なGUI操作から、より高度なSQLクエリやAPI呼び出しまで、各種テクニックを掘り下げながら、それぞれの強みと制約を見ていきます。最後には、最も高い柔軟性を備えつつもひと手間かかるソリューションをご紹介します——もっとも、その手間の大半はすでにこちらで済ませてあります!
取り上げるオプションは以下のとおりです。
- Google Cloud Console ウェブUI
- BigQuery CLI
- Dataplex(Data Catalog)
- INFORMATION_SCHEMA
- カスタムスクリプト
そして、評価軸として次の点を見ていきます。
- 一覧化のスコープ
- 取得できる情報の詳細さ
- 柔軟性
- 料金
まずは馴染みのあるGoogle Cloud ConsoleのウェブUIから始めるのが分かりやすいでしょう。BigQueryプロダクトページからBigQuery Studioに移動すると、現在のプロジェクト(および追加した他のプロジェクト)のデータセットとテーブルがエクスプローラペインに表示されます。さらに、リソース(データセット、テーブル、ビュー)を名前やラベルで検索することもでき、アクセス権を持つprojectsとorganisationsの両方にまたがる結果が返されます。
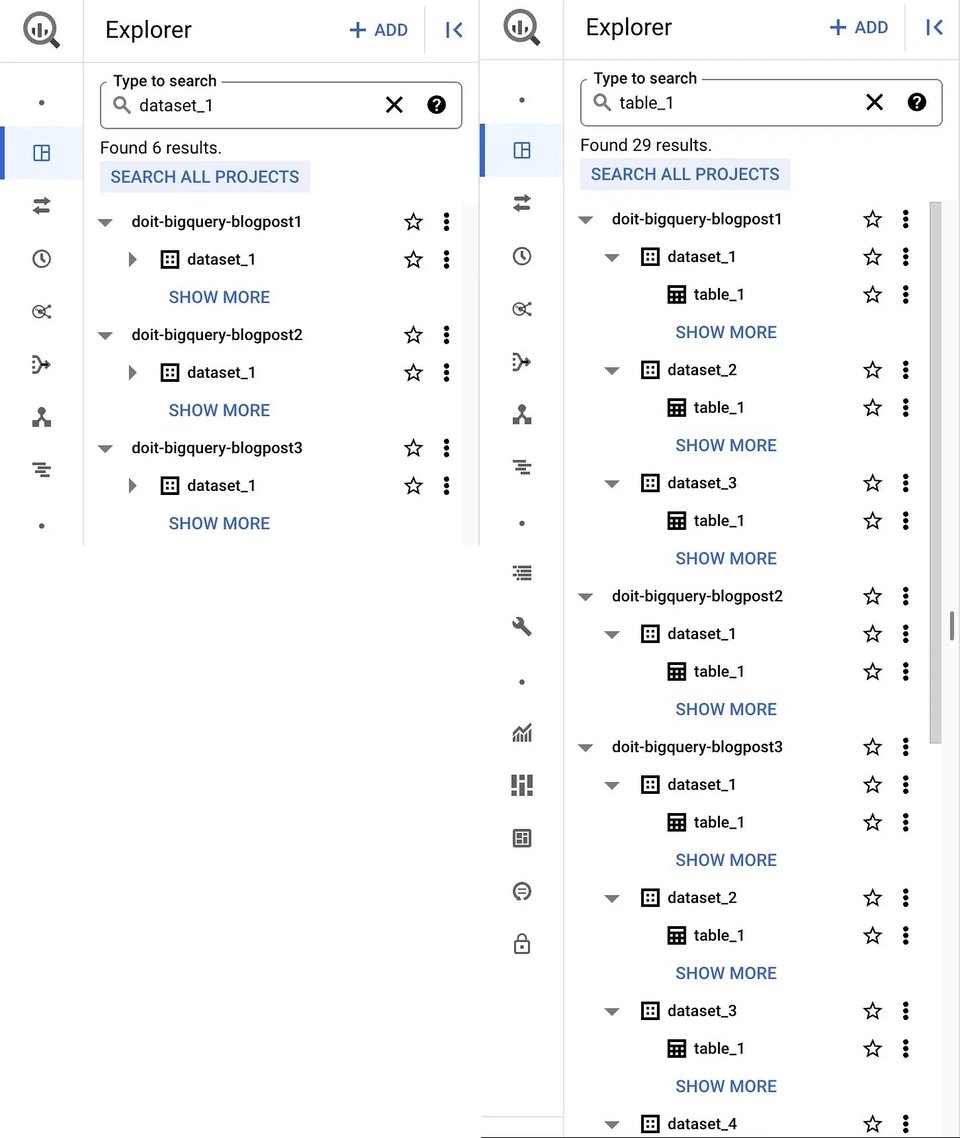 BigQuery UIのデータセット(左)とテーブル(右)
BigQuery UIのデータセット(左)とテーブル(右)
メリット:
- BigQuery Studioから簡単にアクセスできる。
projectsとorganisationsを横断して検索でき、スコープに制限がない。- 無料で利用できる。
デメリット:
- 組織内、あるいはアクセス可能なすべてのデータセットやテーブルを網羅した一覧は得られない。
- テーブルに関するその他のメタデータは取得できない。
UIがあまり好みではなく、コマンドラインで作業したいタイプの方には、BigQuery CLIのほうが魅力的に映るかもしれません。
PROJECT_IDが分かっていれば、以下のコマンドで該当プロジェクト内のすべてのデータセットを一覧表示できます。
bq ls --project_id $PROJECT_ID BigQuery CLIのデータセット
BigQuery CLIのデータセット
あるいは、PROJECT_IDとDATASET_IDの両方が分かっていれば、以下のコマンドで該当データセット内のすべてのテーブルを一覧表示できます。
bq ls --project_id $PROJECT_ID --dataset_id=$DATASET_ID BigQuery CLIのテーブル
BigQuery CLIのテーブル
メリット:
- 使いやすいCLI。
- 特に
--format: <none|json|prettyjson|csv|sparse|pretty>フラグを使えば、出力をそのままjqなどによる軽量な後続処理に活用できる。 - メタデータ操作は無料。
デメリット:
- 一覧化のスコープが限定される:データセットレベルではプロジェクト単位、テーブルレベルではデータセット単位にとどまる。
- 取得できる詳細情報も限定的。
組織内の関連データをくまなく見つけ出したい、と考えたときに真っ先に思い浮かぶのがData Catalogでしょう。Data Catalogはかつて単独のプロダクトでしたが、2022年半ば以降はDataplexの一機能になっています。Dataplexは、データレイク、データウェアハウス、データベースを横断したデータの整理、セキュリティ、分析を自動化するGoogle Cloudのインテリジェントなデータマネジメントプラットフォームで、組織におけるデータの発見性、ガバナンス、コンプライアンスを支援します。Data Catalogは、組織のデータ資産の中央インベントリとして機能します。
組織やシステムを横断した検索や、データタイプ・タグなどによるフィルタリングが可能です。今回のユースケースに即していえば、UI上で適切なフィルタを指定するだけで、特定の組織内のすべてのデータセットとテーブルを取得できます。
うれしいのは、UIよりCLIを好む方のために、gcloudコマンドでも同じことが実現できる点です。
データセットの場合:
gcloud data-catalog search "type=dataset" --include-organization-ids=YOUR_ORG_ID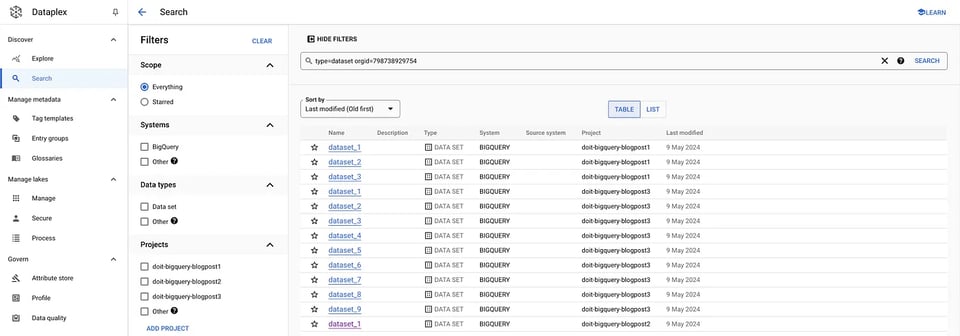 Dataplexのデータセット
Dataplexのデータセット
テーブルの場合:
gcloud data-catalog search "type=table" --include-organization-ids=YOUR_ORG_ID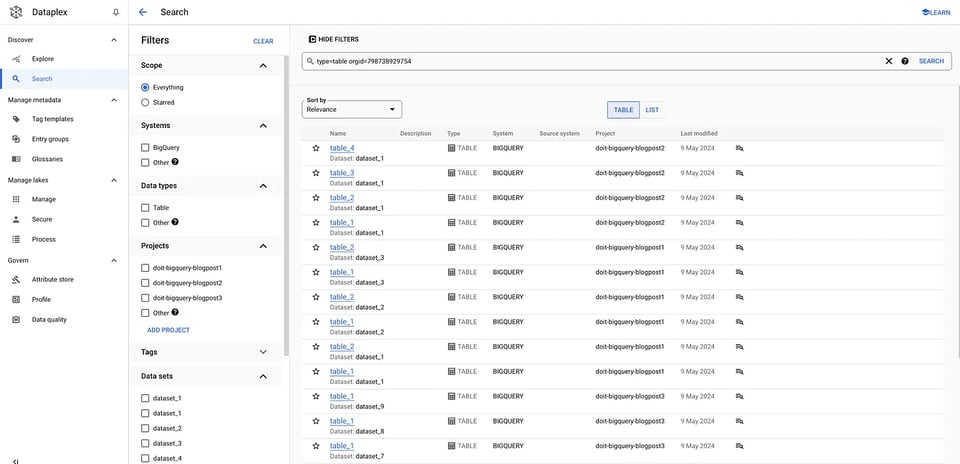 Dataplexのテーブル
Dataplexのテーブル
メリット:
- 組織を横断して検索でき、しかもBigQueryに限定されない。
デメリット:
- Data Catalogはさまざまな種類のメタデータ(ビジネス系・技術系の双方)を保持しているが、テーブルサイズや格納されている総バイト数といった情報は取得できない。
- DataplexもData Catalogも有償だが、ほとんどのユースケースでは料金は許容範囲に収まるはず。詳細は料金ページをご確認ください。
BigQueryを使い込んでいる方であれば、INFORMATION_SCHEMAはおなじみでしょう。BigQueryのINFORMATION_SCHEMAビューは読み取り専用のシステム定義ビューで、BigQueryオブジェクトに関するメタデータを提供します。多種多様なビューが存在するため、全体像はドキュメントをご確認ください。
今回のユースケースで特に注目したいのは、SCHEMATAビューとTABLESビューです。
SCHEMATAビューを使えば、リージョン内のすべてのデータセットを一覧表示できます(us-central1の例)。
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.SCHEMATA;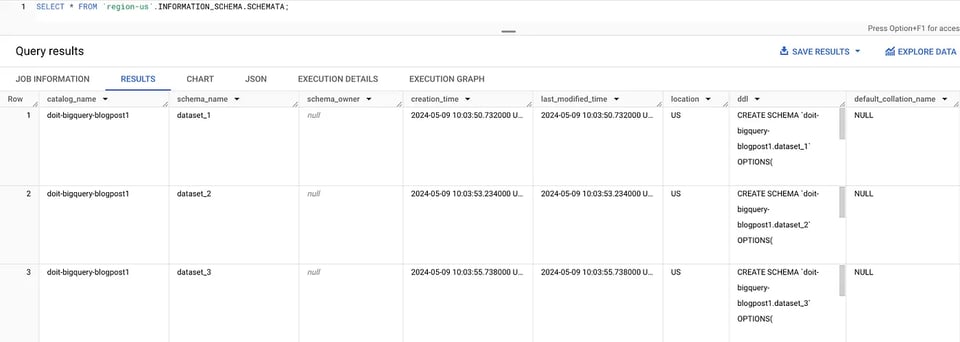 INFORMATION_SCHEMAのデータセット
INFORMATION_SCHEMAのデータセット
あるいは、TABLESビューを使えば、リージョン内のすべてのテーブルを一覧表示できます(us-central1の例)。
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.TABLES;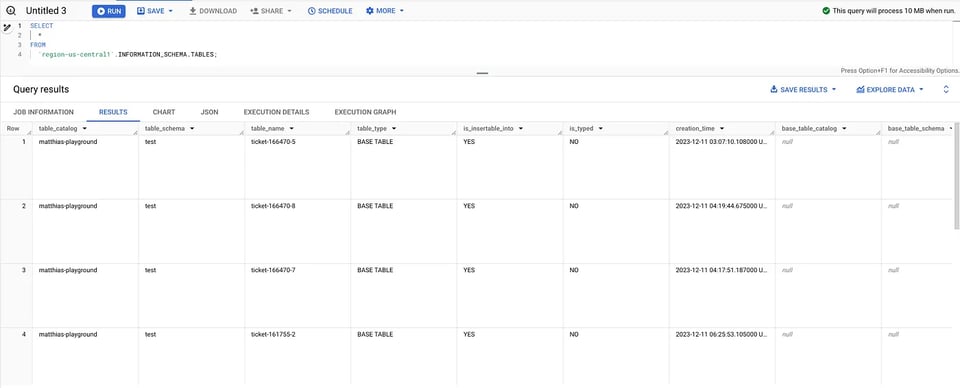 INFORMATION_SCHEMAのテーブル
INFORMATION_SCHEMAのテーブル
メリット:
- BigQuery上でSQLを使い、プログラムから手軽にアクセスできる。
- 非常に詳細な情報が得られる。たとえば
[TABLES](https://cloud.google.com/bigquery/docs/information-schema-tables#schema) [view](https://cloud.google.com/bigquery/docs/information-schema-tables#schema)には`creation_time`、`ddl`が含まれ、TABLE_STORAGE ビューにはtotal_rowsやテーブルサイズ(物理ストレージ・論理ストレージの両方)の情報がある。
デメリット:
- 情報の対象範囲はせいぜいリージョン単位にとどまる(組織レベルのビューでも同様)。リージョンの一覧はすでにかなり長く、動的に変わる可能性もあるため、それを前提にスクリプトを組むのは理想的とは言えない。
- 無料ではないが、ほとんどのユースケースで料金は許容範囲に収まるはず。
例によって、技術に長けたお客様から「組織全体を可視化したうえで、プロジェクト横断でテーブルの詳細情報も取得したい」というご相談が寄せられました。
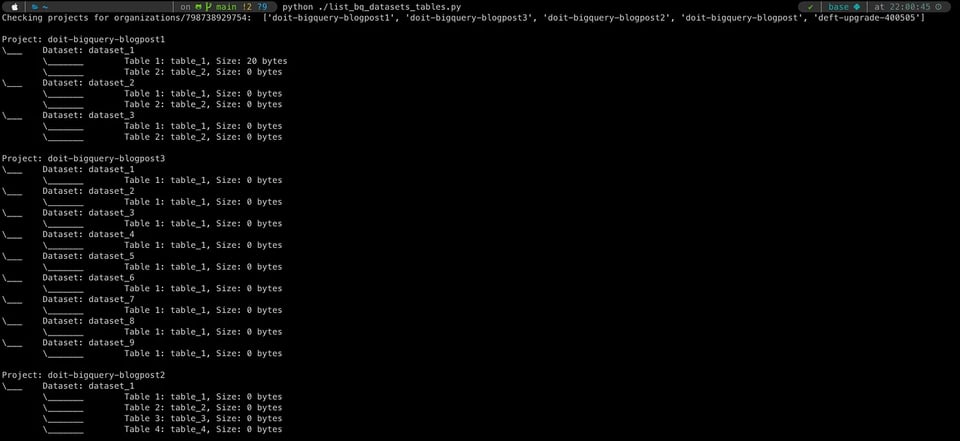
そこで、まさにそれを実現する小さなスクリプトを書き上げました。私たちのGitHubでも公開しています。いくつかの環境変数を設定することで、組織レベルにサービスアカウントをプロビジョニングし、その組織内のすべてのプロジェクトとデータセットをループ処理しながら、各データセット内のテーブルと関連する詳細情報(今回の場合はテーブルサイズ)を取得します。多少のPythonの知識とBigQuery APIへの理解は必要ですが、このアプローチでは最大の柔軟性が得られ(APIドキュメントを参照すればその他のテーブル属性も取得可能)、後続処理に合わせて任意のフォーマットで出力できます。
メリット:
- 最大限の柔軟性:
- APIから必要なデータをすべて抽出できる。
- 出力結果は思いどおりの形に整えられる。
- フィルタの追加やスクリプトの拡張も自由自在。
- 無料。DoiTからみなさまへ。
デメリット:
- スクリプトを書く時間と手間が追加で必要——とはいえ、その大半の下準備はすでに済ませてあります!
BigQueryの操作は複雑になりがちで、それぞれの方法には組織のニーズに応じた独自の利点があります。標準ツールはシンプルさと手軽さを提供しますが、カスタムスクリプトは多少の初期投資と引き換えに、他にはない柔軟性と詳細さを引き出せます。
これまでに別のアプローチを試したことはありますか?お気に入りの方法をぜひ共有してください。あるいは、ご自身のニーズに合わせて基本スクリプトを拡張してみてください!