
Wir vergleichen verschiedene Ansätze, um Transparenz über Ihren BigQuery-Bestand zu gewinnen, und stellen Ihnen ein eigenes Python-Skript für maximale Flexibilität vor.
In der rasant wachsenden Welt der Datenanalyse setzt sich Google BigQuery als leistungsstarkes, serverloses Data Warehouse durch, mit dem sich blitzschnelle SQL-Abfragen über riesige Datasets ausführen lassen. Egal ob Data Scientist, Data Engineer oder Analytics-Profi: Sich durch den enormen Funktionsumfang von BigQuery zu arbeiten, fühlt sich oft wie eine Schatzsuche an. Wenn Ihre Organisation wächst, wächst meist auch Ihr BigQuery-Bestand mit – und eine Herausforderung, vor der viele Anwender stehen, ist das effiziente Auflisten von Tabellen und Datasets über unterschiedliche Scopes hinweg.
Dieser Beitrag führt Sie durch die verschiedenen Methoden, mit denen sich Tabellen und Datasets in BigQuery auflisten lassen – mit dem klaren Ziel, diese Assets organisationsweit zu erfassen und dabei die jeweiligen Grenzen jedes Ansatzes aufzuzeigen.
Wir gehen die einzelnen Techniken Schritt für Schritt durch – von einfachen GUI-Interaktionen bis hin zu fortgeschritteneren SQL-Abfragen und API-Aufrufen – und beleuchten Stärken wie Schwächen. Am Ende stellen wir eine Lösung vor, die größtmögliche Flexibilität bietet, dafür aber etwas mehr Aufwand erfordert – sofern wir Ihnen die Vorarbeit nicht ohnehin schon abgenommen haben!
Wir schauen uns folgende Optionen an:
- Google Cloud Console Web-UI
- BigQuery CLI
- Dataplex (Data Catalog)
- INFORMATION_SCHEMA
- Eigenes Skript
Und betrachten dabei einige Bewertungskriterien:
- Umfang der Auflistung
- Detailtiefe der Informationen
- Flexibilität
- Preis
Ein guter Einstieg ist die vertraute Google Cloud Console Web-UI. Wenn Sie auf der BigQuery-Produktseite zu BigQuery Studio wechseln, finden Sie Datasets und Tabellen Ihres aktuellen Projekts (sowie weiterer Projekte, falls hinzugefügt) übersichtlich im Explorer-Bereich. Dort lässt sich auch nach Ressourcen (Dataset, Tabelle oder View) per Name oder Label suchen, und die Ergebnisse umfassen sowohl projects als auch organisations, auf die Sie Zugriff haben.
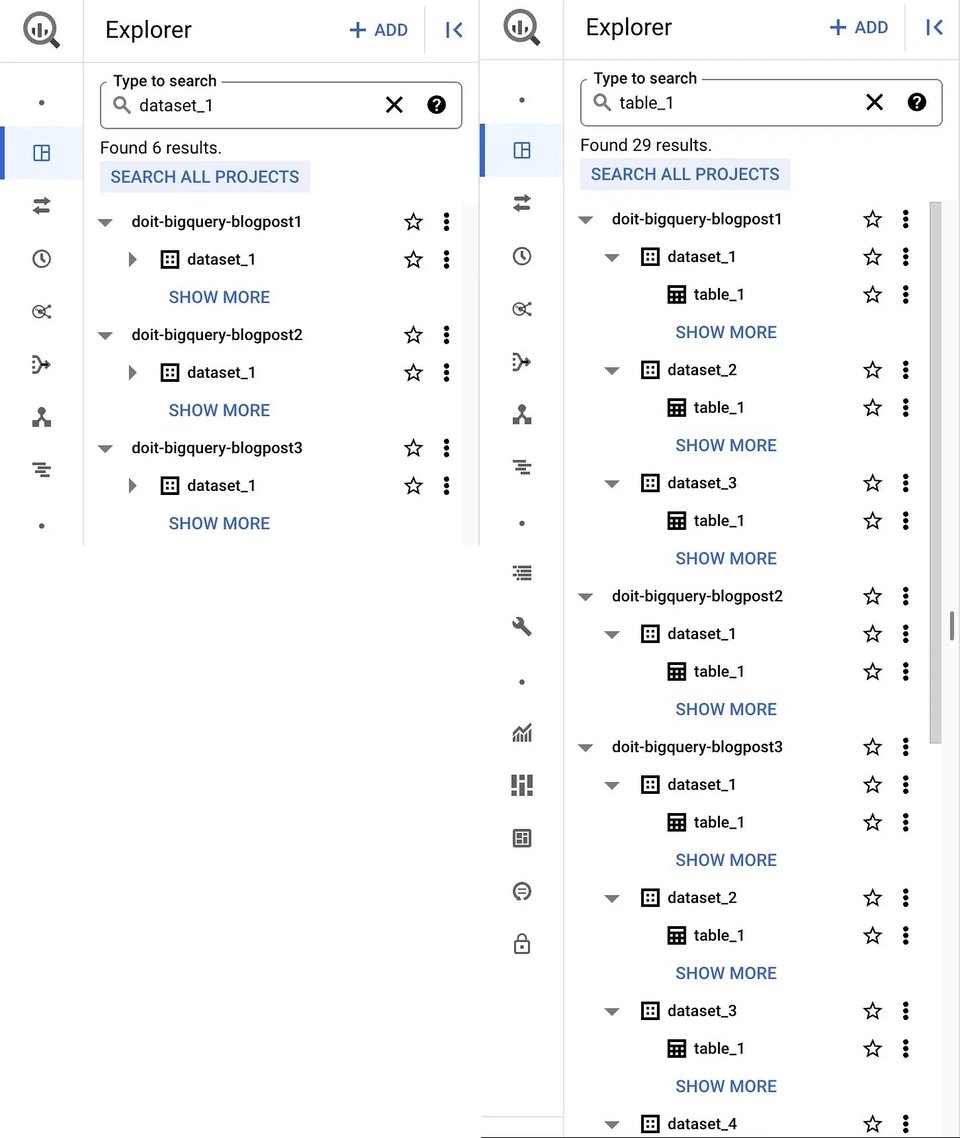 BigQuery UI Datasets (links) und Tabellen (rechts)
BigQuery UI Datasets (links) und Tabellen (rechts)
Pro:
- Direkt aus BigQuery Studio heraus erreichbar.
- Sucht über
projectsundorganisationshinweg – also keine Einschränkungen im Scope. - Dieser Ansatz ist kostenlos.
Contra:
- Liefert keine vollständige Liste aller Datasets oder Tabellen Ihrer Organisation bzw. derer, auf die Sie Zugriff haben.
- Liefert keine weiteren Metadaten zu Ihren Tabellen.
Wenn Sie kein großer Freund von UIs sind und Ihre Zeit lieber auf der Kommandozeile verbringen, dürfte Sie die BigQuery CLI eher ansprechen.
Mit einer PROJECT_ID listen Sie alle Datasets in diesem Projekt wie folgt auf:
bq ls --project_id $PROJECT_ID BigQuery CLI Datasets
BigQuery CLI Datasets
Oder mit PROJECT_ID und DATASET_ID alle Tabellen in diesem Dataset:
bq ls --project_id $PROJECT_ID --dataset_id=$DATASET_ID BigQuery CLI Tables
BigQuery CLI Tables
Pro:
- Einfach zu bedienende CLI.
- Die Ausgabe lässt sich für leichtgewichtige Weiterverarbeitung nutzen, z. B. mit
jq– insbesondere mit dem Flag--format: <none|json|prettyjson|csv|sparse|pretty>. - Metadaten-Operationen sind kostenlos.
Contra:
- Der Scope der Auflistung ist begrenzt: Auf Dataset-Ebene ist es ein Projekt, auf Tabellenebene ein Dataset.
- Auch die zurückgegebenen Details sind eingeschränkt.
Wenn es darum geht, alle relevanten Daten in der Organisation zu finden, kommt einem natürlich Data Catalog in den Sinn! Data Catalog war früher ein eigenständiges Produkt, ist aber seit Mitte 2022 Teil von Dataplex. Dataplex ist die intelligente Datenmanagement-Plattform von Google Cloud, die Organisation, Sicherheit und Analyse von Daten über Data Lakes, Warehouses und Datenbanken hinweg automatisiert und Ihre Organisation bei Discoverability, Governance und Compliance unterstützt. Data Catalog dient dabei als zentrales Inventar der Datenbestände Ihrer Organisation.
Es ermöglicht die Suche über Organisationen und Systeme hinweg sowie das Filtern nach Datentypen, Tags usw. Für unseren Anwendungsfall lassen sich alle Datasets & Tabellen innerhalb einer bestimmten Organisation einfach über den passenden Filter in der UI abrufen:
Praktisch: Wer CLI gegenüber UI bevorzugt, erreicht dasselbe mit einem gcloud-Befehl wie folgt:
Für Datasets:
gcloud data-catalog search "type=dataset" --include-organization-ids=YOUR_ORG_ID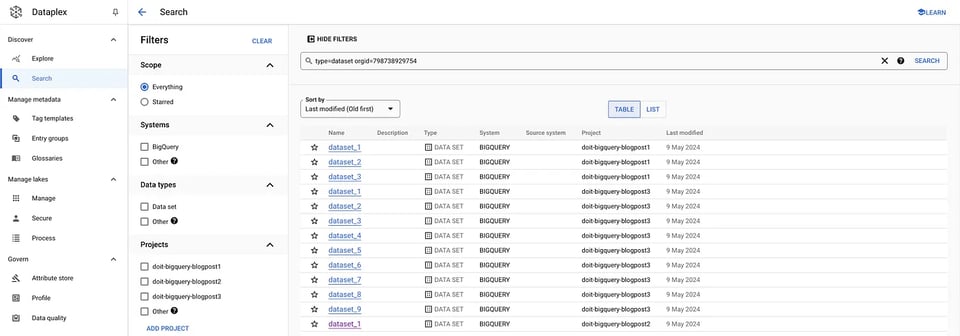 Dataplex Datasets
Dataplex Datasets
Für Tabellen:
gcloud data-catalog search "type=table" --include-organization-ids=YOUR_ORG_ID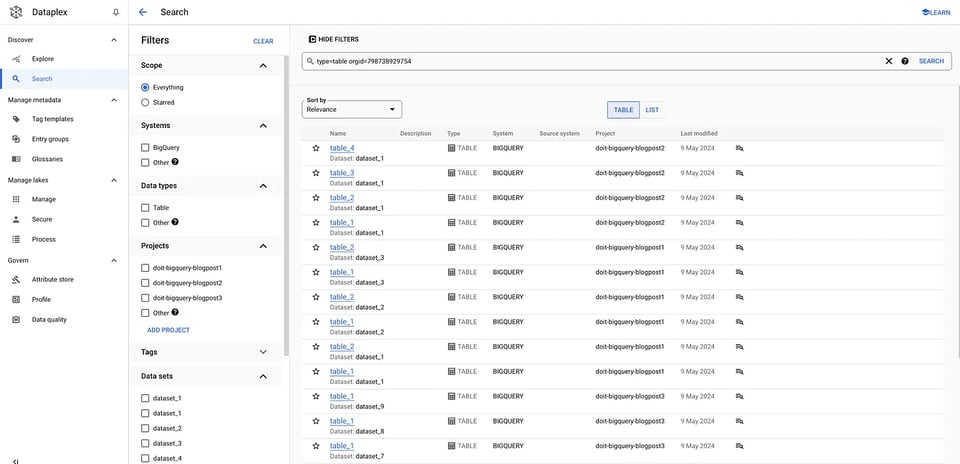 Dataplex Tables
Dataplex Tables
Pro:
- Sucht über Organisationen hinweg UND geht über die reine BigQuery-Suche hinaus.
Contra:
- Data Catalog speichert verschiedene Arten von Metadaten (sowohl fachliche als auch technische), allerdings fehlen Details wie Tabellengröße oder gespeicherte Bytes insgesamt.
- Weder Dataplex noch Data Catalog sind kostenlos, die Kosten sollten für die meisten Anwendungsfälle aber überschaubar bleiben. Details finden Sie auf der Preisseite.
BigQuery-Aficionados dürfte INFORMATION_SCHEMA bestens vertraut sein. Die BigQuery INFORMATION_SCHEMA-Views sind schreibgeschützte, systemdefinierte Views, die Metadaten zu Ihren BigQuery-Objekten bereitstellen. Es gibt eine Vielzahl unterschiedlicher Views – einen umfassenden Überblick finden Sie in der Dokumentation.
Für unseren Anwendungsfall sind insbesondere die SCHEMATA-View und die TABLES-View interessant:
Mit der SCHEMATA-View lassen sich alle Datasets innerhalb einer Region auflisten, z. B. für us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.SCHEMATA;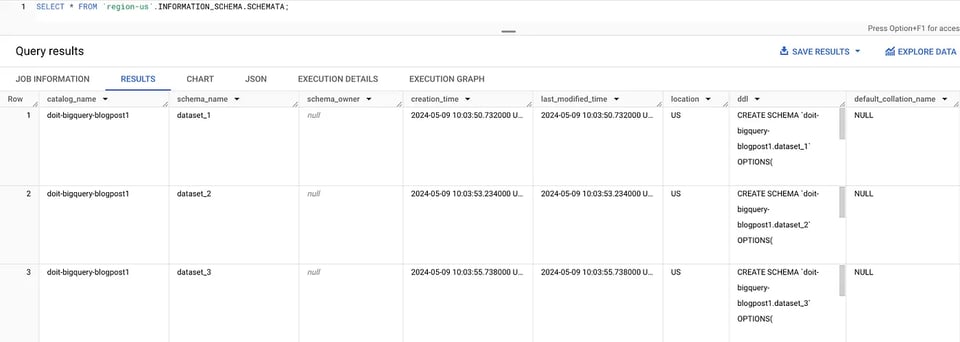 INFORMATION_SCHEMA Datasets
INFORMATION_SCHEMA Datasets
Oder die TABLES-View, um alle Tabellen innerhalb einer Region aufzulisten, z. B. für us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.TABLES;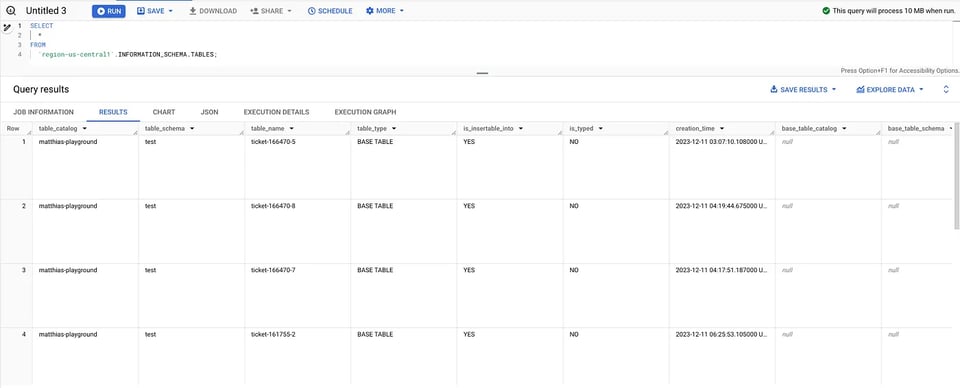 INFORMATION_SCHEMA Tables
INFORMATION_SCHEMA Tables
Pro:
- Einfacher, programmatischer Zugriff per SQL direkt in BigQuery.
- Sehr detaillierte Informationen; z. B. enthält
[TABLES](https://cloud.google.com/bigquery/docs/information-schema-tables#schema) [view](https://cloud.google.com/bigquery/docs/information-schema-tables#schema) `creation_time`, `ddl`,die TABLE_STORAGE-View liefert Informationen zutotal_rowssowie zur Tabellengröße (sowohl physischer als auch logischer Speicher).
Contra:
- Informationen sind bestenfalls auf eine Region beschränkt (selbst bei der View auf Organisationsebene). Da die Liste der Regionen ohnehin schon recht lang ist und sich dynamisch ändern kann, ist es wenig praktikabel, das per Skript abzubilden.
- Nicht kostenlos, die Kosten sollten für die meisten Anwendungsfälle aber überschaubar bleiben.
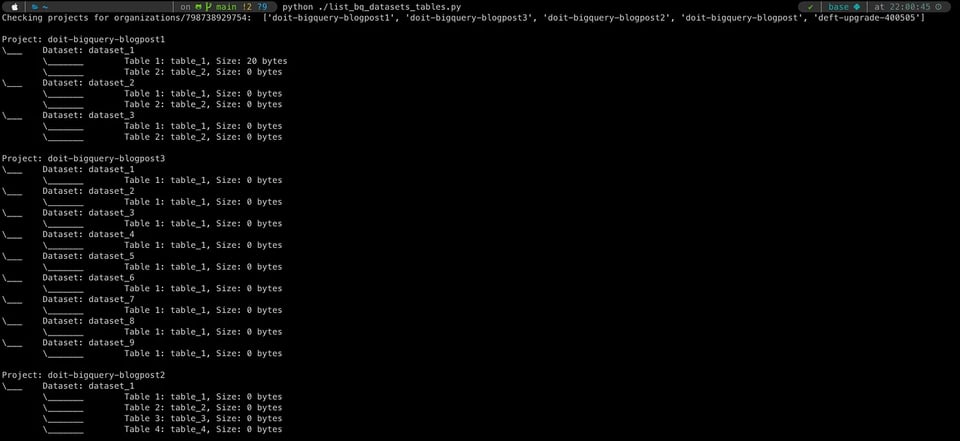
Wie das so ist, haben uns unsere technisch versierten Kunden auf die Probe gestellt und mit der Anforderung an uns gewandt, organisationsweite Sichtbarkeit zu schaffen und gleichzeitig umfangreiche Details zu Tabellen über alle Projekte hinweg abzurufen.
Am Ende ist daraus ein kleines Skript entstanden, das genau das leistet – Sie finden es auf unserem GitHub. Es benötigt einige Umgebungsvariablen, stellt einen Service-Account auf Organisationsebene bereit und durchläuft anschließend alle Projekte und Datasets dieser Organisation, um die enthaltenen Tabellen samt relevanter Details abzurufen (in diesem Fall: Tabellengröße). Grundlegende Python-Kenntnisse und etwas Vertrautheit mit der BigQuery-API vorausgesetzt, bietet dieser Ansatz die größte Flexibilität (weitere Tabellenattribute lassen sich anhand der API-Dokumentation ergänzen) und die Daten lassen sich in jedem gewünschten Format für die Weiterverarbeitung ausgeben.
Pro:
- Maximale Flexibilität:
- Holen Sie sich genau die Daten aus der API, die Sie brauchen.
- Die Ausgabe lässt sich beliebig gestalten.
- Filter ergänzen oder das Skript nach Belieben erweitern – ganz nach Ihren Anforderungen.
- Kostenlos – von DoiT für Sie.
Contra:
- Etwas Zeit und Aufwand für das Skript – aber den Großteil der Vorarbeit haben wir Ihnen schon abgenommen!
Sich in BigQuery zurechtzufinden, kann komplex sein – jede Methode hat ihre eigenen Stärken, je nach Anforderungen Ihrer Organisation. Standardwerkzeuge punkten mit Einfachheit und schneller Verfügbarkeit; ein eigenes Skript bietet dagegen unschlagbare Flexibilität und Detailtiefe – auch wenn es etwas Vorarbeit kostet.
Sind Sie bisher anders vorgegangen? Teilen Sie gerne Ihren bevorzugten Weg oder erweitern Sie das Basisskript nach Ihren Bedürfnissen!