
In questo articolo confrontiamo i diversi approcci per analizzare il Suo footprint BigQuery e Le proponiamo uno script Python personalizzato per la massima flessibilità.
Nel mondo in rapida evoluzione della data analytics, Google BigQuery si distingue come potente data warehouse serverless, capace di eseguire query SQL ultra-rapide su dataset di grandi dimensioni. Che si tratti di data scientist, data engineer o esperti di analytics, muoversi tra le numerose funzionalità di BigQuery è spesso come scoprire tesori nascosti. Con la crescita dell'organizzazione cresce anche il footprint BigQuery, e una delle sfide più comuni è elencare in modo efficiente tabelle e dataset su scope diversi.
L'obiettivo di questo articolo è guidarLa attraverso i vari metodi per elencare tabelle e dataset in BigQuery, con lo scopo specifico (e finale) di mappare questi asset nell'intera organizzazione, evidenziando di volta in volta i limiti intrinseci di ciascun approccio.
Esploreremo le diverse tecniche, dalle interazioni di base con la GUI fino alle query SQL e alle chiamate API più avanzate, mettendone in luce punti di forza e vincoli. Per concludere, presenteremo una soluzione finale che offre la massima flessibilità a fronte di un po' più di lavoro — sempre che non l'abbiamo già svolto noi al posto Suo!
Esamineremo le seguenti opzioni:
- Google Cloud Console web UI
- BigQuery CLI
- Dataplex (Data Catalog)
- INFORMATION_SCHEMA
- Script personalizzato
E lungo il percorso valuteremo alcune dimensioni chiave:
- Ambito dell'elenco
- Livello di dettaglio
- Flessibilità
- Costo
Un buon punto di partenza è la familiare Google Cloud Console web UI. Aprendo BigQuery Studio dalla pagina del prodotto BigQuery, dataset e tabelle del progetto attivo (e di altri progetti, se aggiunti) compaiono nel pannello Explorer. È inoltre possibile cercare risorse (dataset, tabella o vista) per nome o etichetta, ottenendo risultati che spaziano sia tra i projects sia tra le organisations a cui si ha accesso.
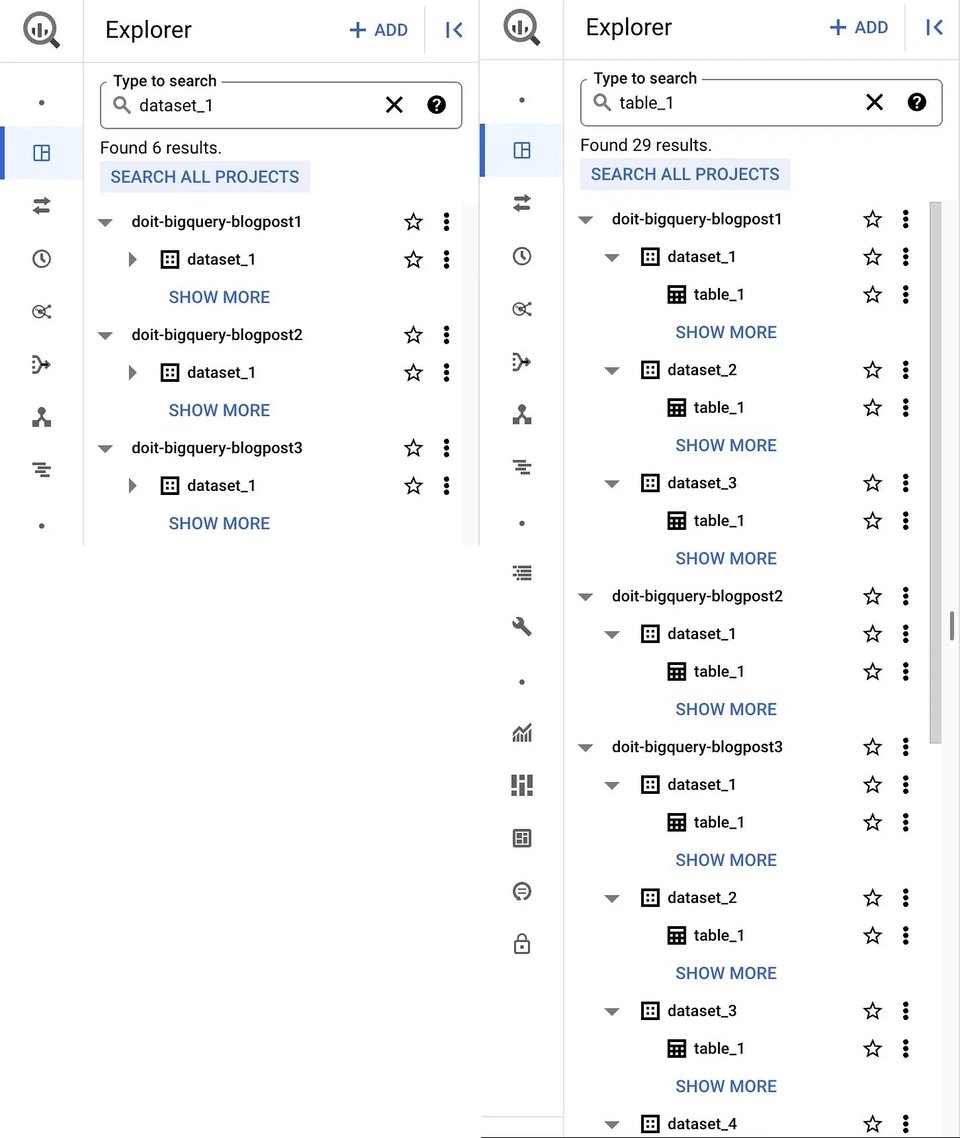 BigQuery UI: dataset (a sinistra) e tabelle (a destra)
BigQuery UI: dataset (a sinistra) e tabelle (a destra)
Pro:
- Accessibile direttamente da BigQuery Studio.
- Effettua ricerche su
projectseorganisations, senza limiti di ambito. - L'approccio è gratuito.
Contro:
- Non restituisce un elenco esaustivo di tutti i dataset o di tutte le tabelle dell'organizzazione, né di quelli a cui si ha accesso.
- Non fornisce ulteriori metadati sulle tabelle.
Se preferisce la riga di comando alle interfacce grafiche, la BigQuery CLI fa al caso Suo.
Dato un PROJECT_ID, è possibile elencare tutti i dataset del progetto con:
bq ls --project_id $PROJECT_ID BigQuery CLI: dataset
BigQuery CLI: dataset
Oppure, indicando sia PROJECT_ID sia DATASET_ID, è possibile elencare tutte le tabelle di quel dataset con:
bq ls --project_id $PROJECT_ID --dataset_id=$DATASET_ID BigQuery CLI: tabelle
BigQuery CLI: tabelle
Pro:
- CLI semplice da usare.
- L'output si presta a elaborazioni downstream leggere, ad esempio con
jq, soprattutto sfruttando il flag--format: <none|json|prettyjson|csv|sparse|pretty>. - Le operazioni sui metadati sono gratuite.
Contro:
- L'ambito è limitato: il progetto a livello di dataset, il dataset a livello di tabella.
- Anche i dettagli restituiti sono limitati.
Quando si tratta di individuare tutti i dati rilevanti dell'organizzazione, viene subito in mente Data Catalog. Un tempo prodotto a sé stante, dalla metà del 2022 è una funzionalità di Dataplex. Dataplex è la piattaforma intelligente di data management di Google Cloud, che automatizza organizzazione, sicurezza e analisi dei dati su data lake, warehouse e database, supportando l'organizzazione su discoverability, governance e compliance. Data Catalog funge da inventario centrale degli asset di dati dell'organizzazione.
Permette di effettuare ricerche su organizzazioni e sistemi, filtrando per tipo di dato, tag e altro. Nel nostro caso d'uso specifico, è possibile recuperare tutti i dataset e le tabelle di una determinata organizzazione semplicemente applicando il filtro corretto nella UI:
Il bello è che, per chi predilige la CLI alla UI, lo stesso risultato si ottiene con un comando gcloud:
Per i dataset:
gcloud data-catalog search "type=dataset" --include-organization-ids=YOUR_ORG_ID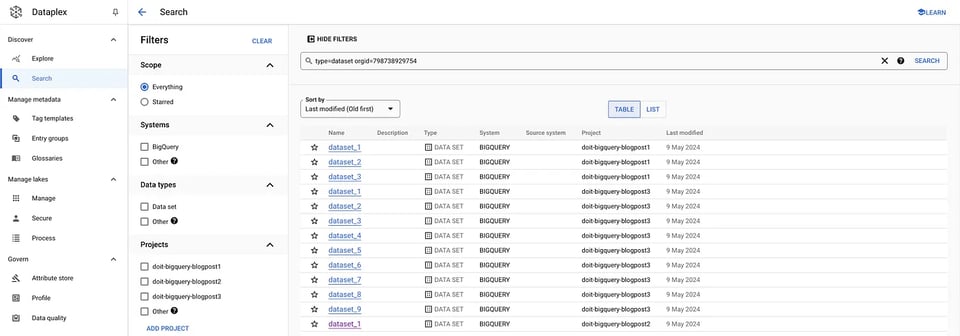 Dataplex: dataset
Dataplex: dataset
Per le tabelle:
gcloud data-catalog search "type=table" --include-organization-ids=YOUR_ORG_ID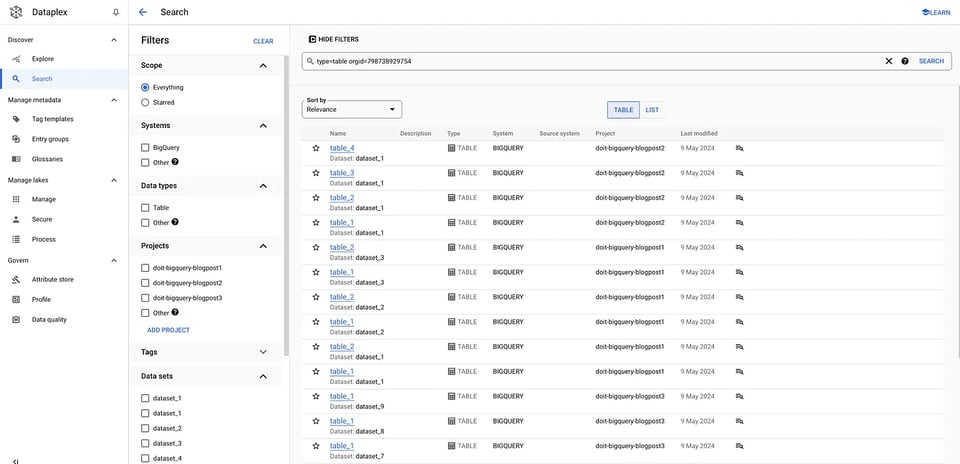 Dataplex: tabelle
Dataplex: tabelle
Pro:
- Ricerca su più organizzazioni e va oltre il solo BigQuery.
Contro:
- Data Catalog conserva diversi tipi di metadati (sia di business sia tecnici), ma tralascia alcuni dettagli come la dimensione delle tabelle o il totale dei byte memorizzati.
- Né Dataplex né Data Catalog sono gratuiti, anche se i costi restano contenuti per la maggior parte dei casi d'uso. Per i dettagli, consultare la pagina dei prezzi.
Chi conosce BigQuery a fondo avrà sicuramente familiarità con INFORMATION_SCHEMA. Le viste INFORMATION_SCHEMA di BigQuery sono viste di sola lettura, definite dal sistema, che restituiscono metadati sugli oggetti BigQuery. Ne esistono numerose: consultare la documentazione per una panoramica completa.
Per il nostro caso d'uso ci interessano in particolare la vista SCHEMATA e la vista TABLES:
La vista SCHEMATA consente di elencare tutti i dataset di una regione, ad esempio per us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.SCHEMATA;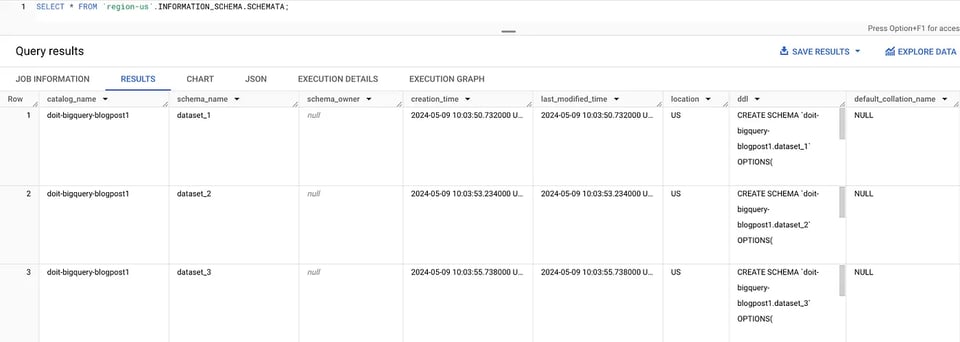 INFORMATION_SCHEMA: dataset
INFORMATION_SCHEMA: dataset
In alternativa, la vista TABLES elenca tutte le tabelle di una regione, ad esempio per us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.TABLES;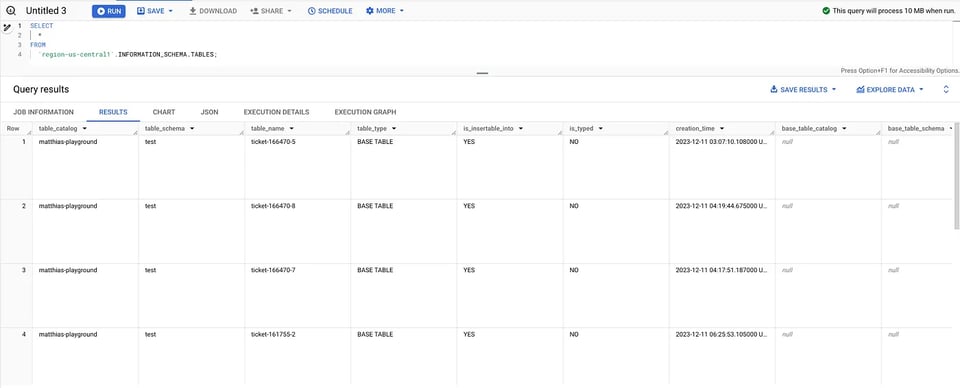 INFORMATION_SCHEMA: tabelle
INFORMATION_SCHEMA: tabelle
Pro:
- Accesso programmatico semplice, in SQL, direttamente da BigQuery.
- Informazioni molto dettagliate; ad esempio la
[TABLES](https://cloud.google.com/bigquery/docs/information-schema-tables#schema) [view](https://cloud.google.com/bigquery/docs/information-schema-tables#schema) include `creation_time`, `ddl`,la vista TABLE_STORAGE riportatotal_rowse la dimensione della tabella (storage sia fisico sia logico).
Contro:
- Le informazioni sono limitate al massimo a livello di regione (anche per la vista a livello di organizzazione). Dato che l'elenco delle regioni è già piuttosto lungo e può variare in modo dinamico, costruirci sopra uno script non è la strada ideale.
- Non è gratuito, anche se i costi restano contenuti per la maggior parte dei casi d'uso.
Come spesso accade, i nostri clienti più tecnici ci hanno messo alla prova, chiedendoci visibilità sull'intera organizzazione e dettagli rilevanti sulle tabelle distribuite tra i progetti.
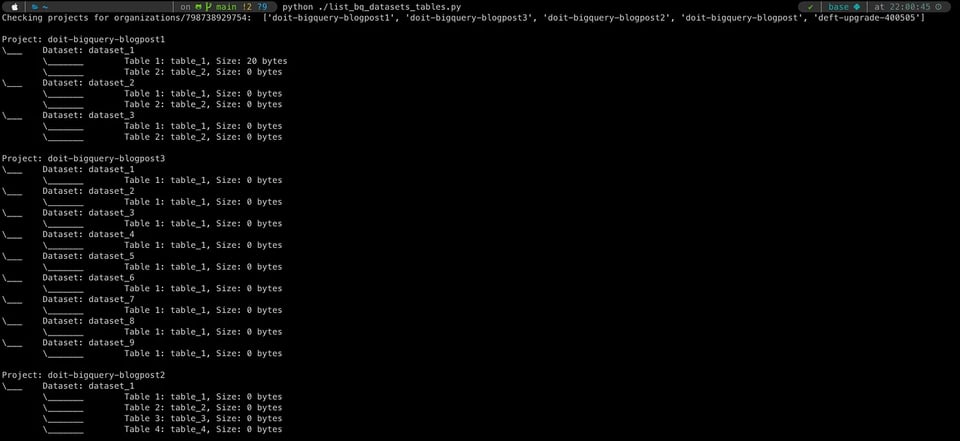
Abbiamo quindi scritto un piccolo script che fa esattamente questo, disponibile sul nostro GitHub. Richiede di impostare alcune variabili d'ambiente che effettuano il provisioning di un service-account a livello di organizzazione, per poi iterare su tutti i progetti e i dataset, recuperando le tabelle al loro interno e i dettagli rilevanti (in questo caso: la dimensione della tabella). Sono richieste conoscenze di base di Python e una certa familiarità con la BigQuery API, ma in cambio si ottiene la massima flessibilità (è possibile recuperare altre caratteristiche delle tabelle consultando la documentazione delle API) e i dati possono essere scritti nel formato preferito per l'utilizzo a valle.
Pro:
- Massima flessibilità:
- Estrazione dall'API di tutti i dati desiderati.
- Output nel formato che si preferisce.
- Filtri ed estensioni dello script senza limiti.
- Gratuito, da DoiT a Lei.
Contro:
- Tempo e impegno aggiuntivi per scrivere lo script — ma gran parte del lavoro l'abbiamo già fatto noi!
Muoversi in BigQuery può essere complesso e ogni metodo offre vantaggi specifici, adatti a esigenze organizzative diverse. Gli strumenti standard puntano su semplicità e accessibilità, mentre uno script personalizzato sblocca un livello di flessibilità e dettaglio impareggiabile, a fronte di un certo impegno iniziale.
Ha già adottato un approccio diverso in passato? Ci racconti il Suo metodo preferito o estenda lo script di base in base alle Sue esigenze!