
En este post comparamos distintos enfoques para obtener visibilidad de tu footprint en BigQuery y te compartimos un script en Python que te da total flexibilidad.
En el vertiginoso mundo de la analítica de datos, Google BigQuery destaca como un data warehouse serverless y potente que permite ejecutar consultas SQL ultrarrápidas sobre datasets enormes. Ya seas data scientist, data engineer o experto en analítica, recorrer todas las capacidades de BigQuery a veces se siente como descubrir tesoros escondidos. A medida que tu organización crece, su footprint en BigQuery también puede crecer, y uno de los retos que enfrentan muchos usuarios es listar de forma eficiente las tablas y los datasets en distintos ámbitos.
Este post busca guiarte por los diferentes métodos para listar tablas y datasets en BigQuery, con el objetivo final de listarlos en toda tu organización, señalando en el camino las limitaciones propias de cada enfoque.
A medida que recorremos las distintas técnicas —desde interacciones básicas en la GUI hasta consultas SQL más avanzadas y llamadas a la API— te llevarás una idea clara de sus fortalezas y de sus límites. Al final presentaremos una solución que ofrece la mayor flexibilidad, aunque exige algo más de trabajo… ¡a menos que ya lo hayamos hecho por ti!
Vamos a recorrer las siguientes opciones:
- UI web de Google Cloud Console
- CLI de BigQuery
- Dataplex (Data Catalog)
- INFORMATION_SCHEMA
- Script personalizado
Y en el camino consideraremos algunas dimensiones de evaluación:
- Alcance del listado
- Nivel de detalle incluido
- Flexibilidad
- Precios
Un buen punto de partida es la conocida UI web de Google Cloud Console. Si entras a BigQuery Studio dentro de la página del producto BigQuery, verás los datasets y las tablas de tu proyecto actual (y de otros proyectos, si los agregaste) desplegados en el panel Explorer. También te permite buscar recursos (dataset, tabla o vista) por nombre o etiqueta, y devuelve resultados que abarcan tanto los projects como las organisations a las que tengas acceso.
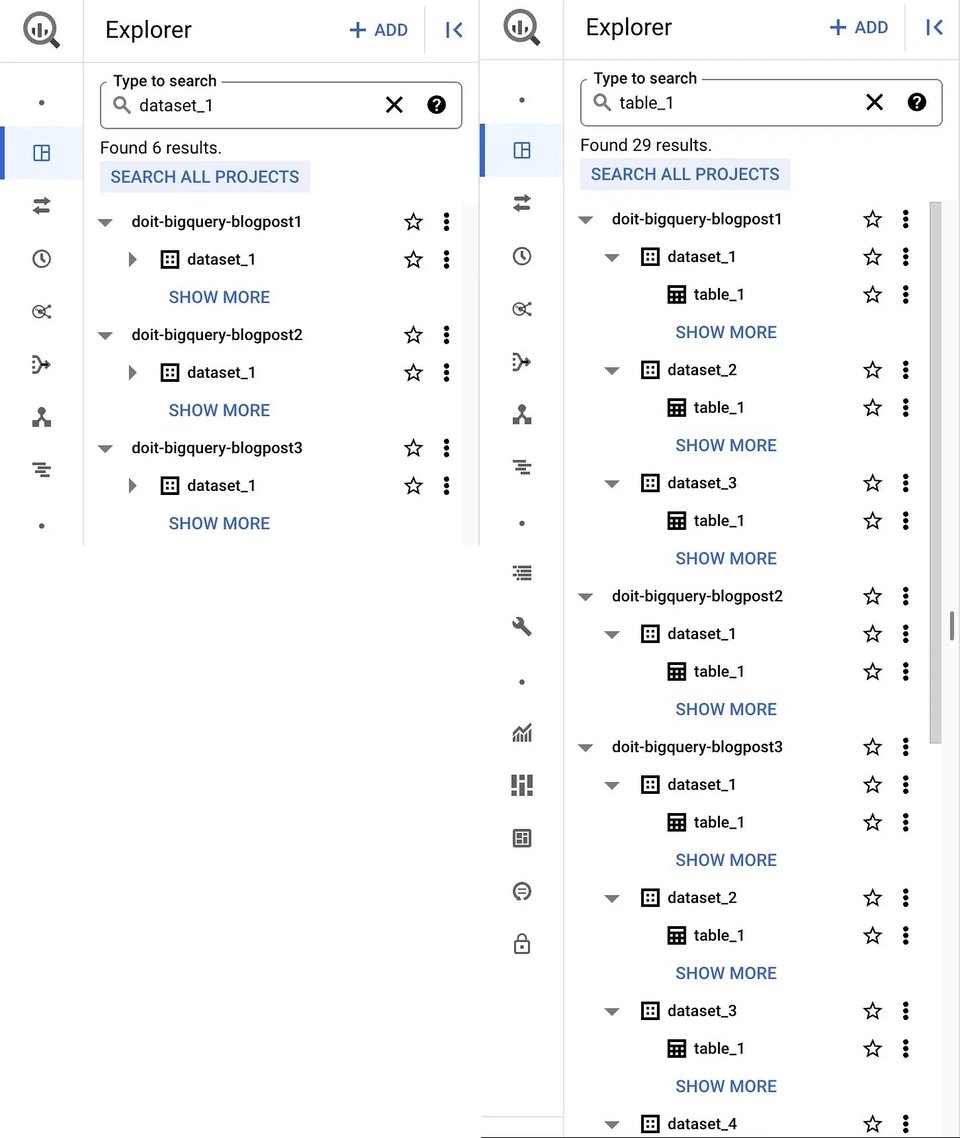 Datasets (izquierda) y tablas (derecha) en la UI de BigQuery
Datasets (izquierda) y tablas (derecha) en la UI de BigQuery
Pros:
- Se accede fácilmente desde BigQuery Studio.
- Puede buscar entre
projectsyorganisations, así que no tiene limitaciones de alcance. - Es un enfoque gratuito.
Contras:
- No entrega un listado exhaustivo de todos los datasets ni tablas de tu organización, ni siquiera de aquellos a los que tienes acceso.
- No proporciona otros metadatos sobre tus tablas.
Si no eres muy fan de las interfaces gráficas y prefieres pasar tu tiempo en la línea de comandos, lo más probable es que te llame más la CLI de BigQuery.
Dado un PROJECT_ID, puedes listar todos los datasets de ese proyecto ejecutando:
bq ls --project_id $PROJECT_ID Datasets en la CLI de BigQuery
Datasets en la CLI de BigQuery
O, dados PROJECT_ID y DATASET_ID, puedes listar todas las tablas de ese dataset ejecutando:
bq ls --project_id $PROJECT_ID --dataset_id=$DATASET_ID Tablas en la CLI de BigQuery
Tablas en la CLI de BigQuery
Pros:
- CLI fácil de usar.
- La salida sirve para procesamiento ligero downstream con, por ejemplo,
jq, sobre todo al usar el flag--format: <none|json|prettyjson|csv|sparse|pretty>. - Las operaciones de metadatos son gratuitas.
Contras:
- El alcance del listado es limitado: tu ámbito es un proyecto a nivel de dataset y un dataset a nivel de tabla.
- El detalle que devuelve el listado también es limitado.
Cuando se piensa en encontrar todos los datos relevantes de tu organización, ¡Data Catalog viene a la mente de inmediato! Data Catalog era un producto independiente, pero es una funcionalidad de Dataplex desde mediados de 2022. Dataplex es la plataforma inteligente de gestión de datos de Google Cloud, que automatiza la organización, la seguridad y el análisis de datos en data lakes, warehouses y bases de datos, y le ayuda a tu organización con discoverability, governance y compliance. Data Catalog funciona como el inventario central de los activos de datos de tu organización.
Te permite buscar entre organizaciones y sistemas, filtrar por tipo de dato, tags, etc. Para nuestro caso de uso en concreto, podemos recuperar todos los datasets y tablas dentro de una organización específica usando el filtro adecuado en la UI:
Lo bueno es que, para quienes prefieren la CLI a la UI, podemos lograr lo mismo con un comando gcloud como el siguiente:
Para datasets:
gcloud data-catalog search "type=dataset" --include-organization-ids=YOUR_ORG_ID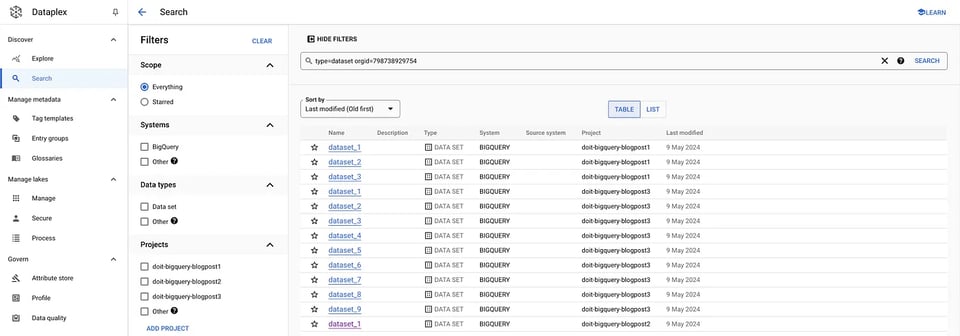 Datasets en Dataplex
Datasets en Dataplex
Para tablas:
gcloud data-catalog search "type=table" --include-organization-ids=YOUR_ORG_ID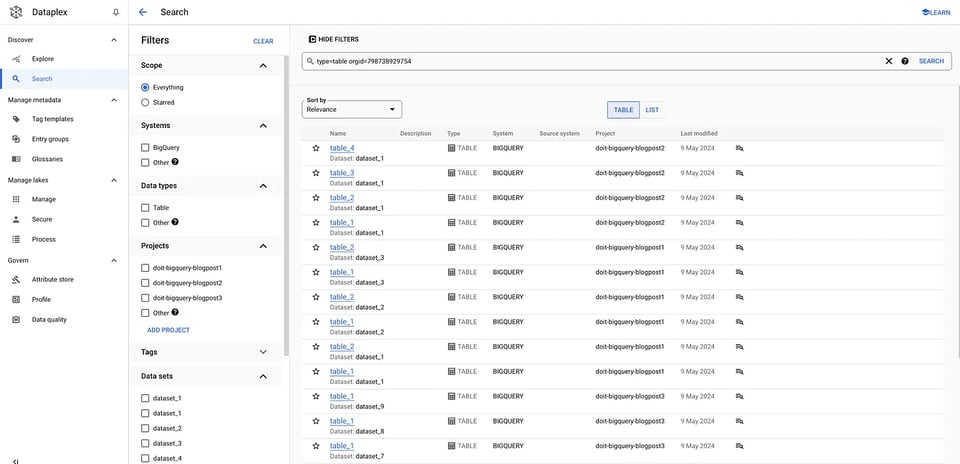 Tablas en Dataplex
Tablas en Dataplex
Pros:
- Busca entre organizaciones Y va más allá de buscar solo en BigQuery.
Contras:
- Data Catalog almacena distintos tipos de metadatos (tanto de negocio como técnicos), pero le faltan algunos detalles como el tamaño de la tabla o el total de bytes almacenados.
- Ni Dataplex ni Data Catalog son gratuitos, aunque los precios deberían ser manejables para la mayoría de los casos de uso. Consulta la página de Precios para más detalles.
Los aficionados a BigQuery seguro que ya conocen INFORMATION_SCHEMA. Las vistas INFORMATION_SCHEMA de BigQuery son vistas de solo lectura definidas por el sistema que aportan información de metadatos sobre tus objetos de BigQuery. Existe una gran cantidad de vistas distintas; consulta la documentación para una visión general completa.
Para nuestro caso de uso nos interesan particularmente la vista SCHEMATA y la vista TABLES:
Podemos usar la vista SCHEMATA para listar todos los datasets dentro de una región, por ejemplo, para us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.SCHEMATA;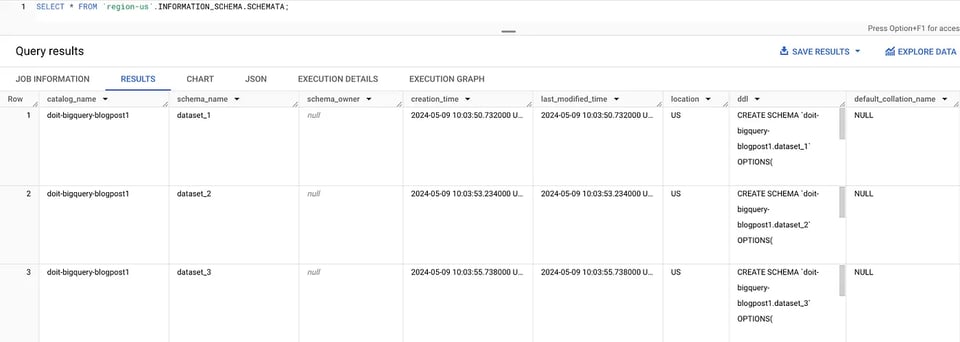 Datasets en INFORMATION_SCHEMA
Datasets en INFORMATION_SCHEMA
O podemos usar la vista TABLES para listar todas las tablas dentro de una región, por ejemplo, para us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.TABLES;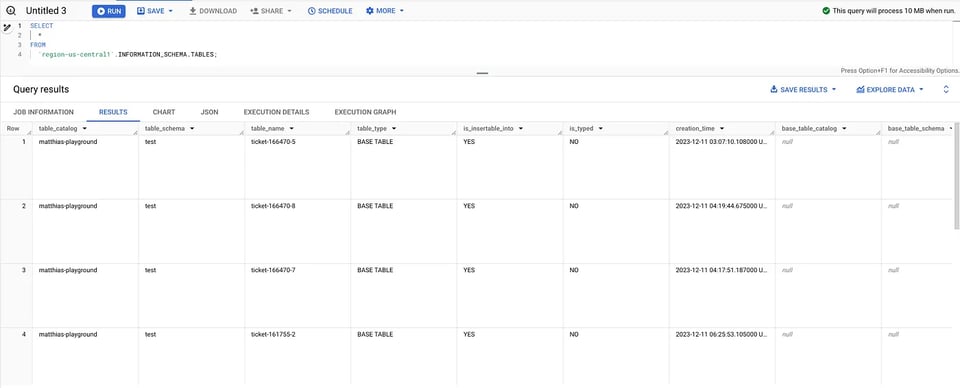 Tablas en INFORMATION_SCHEMA
Tablas en INFORMATION_SCHEMA
Pros:
- Acceso fácil y programático usando SQL directamente en BigQuery.
- Información muy detallada; por ejemplo, la
[TABLES](https://cloud.google.com/bigquery/docs/information-schema-tables#schema) [view](https://cloud.google.com/bigquery/docs/information-schema-tables#schema) incluye `creation_time`, `ddl`,la vista TABLE_STORAGE view trae información sobretotal_rows, así como del tamaño de la tabla (tanto en almacenamiento físico como lógico).
Contras:
- La información se limita, en el mejor de los casos, a una región (incluso para la vista a nivel de organización). Como la lista de regiones ya es bastante larga y puede cambiar de forma dinámica, montar scripting alrededor de eso puede no ser lo ideal.
- No es gratuito, aunque los precios deberían ser manejables para la mayoría de los casos de uso.
Como suele pasar, nuestros clientes con perfil técnico nos retaron y llegaron pidiéndonos visibilidad sobre toda la organización, además de un detalle considerable sobre las tablas a lo largo de los proyectos.
Terminamos escribiendo un pequeño script que hace exactamente eso, y también lo puedes encontrar en nuestro GitHub. Implica configurar algunas variables de entorno que aprovisionarán una service account a nivel de organización y luego recorrer todos los proyectos y datasets de esa organización, recuperando las tablas dentro de esos datasets junto con los detalles relevantes (en este caso: el tamaño de la tabla). Aunque se requieren conocimientos básicos de Python y algo de familiaridad con la API de BigQuery, este enfoque nos da la mayor flexibilidad (podemos recuperar otros atributos de tabla revisando la documentación de la API), y los datos se pueden escribir en el formato que prefieras para su consumo downstream.
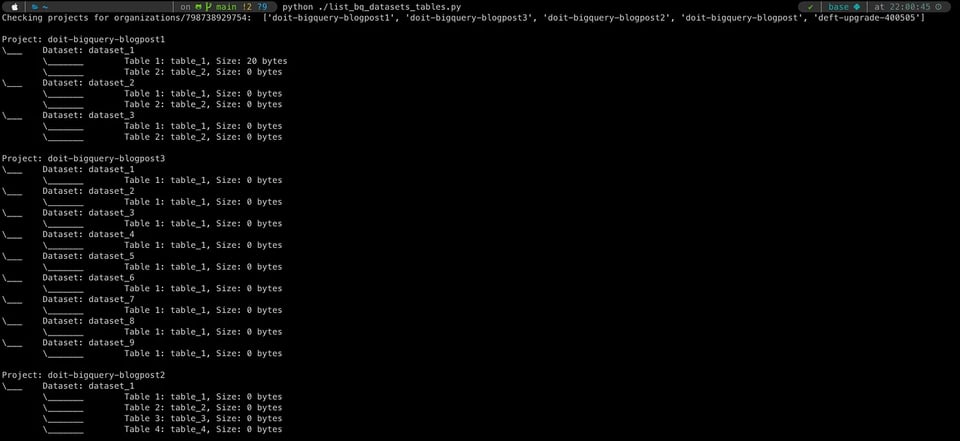
Pros:
- Máxima flexibilidad:
- Extrae todos los datos que quieras de la API.
- Los resultados se pueden generar en el formato que prefieras.
- Agrega filtros o extiende el script tanto como quieras.
- Gratis, de DoiT para ti.
Contras:
- Requiere tiempo y esfuerzo adicional para escribir el script… ¡aunque ya hicimos buena parte del trabajo por ti!
Moverse en BigQuery puede ser complejo, y cada método ofrece ventajas únicas pensadas para distintas necesidades organizacionales. Mientras las herramientas estándar aportan simplicidad y accesibilidad, un script personalizado abre la puerta a una flexibilidad y un nivel de detalle incomparables, aunque requiera algo de esfuerzo inicial.
¿Has probado otro enfoque antes? ¡Comparte tu manera favorita o extiende el script básico para adaptarlo a tus necesidades!