リソース整理や統制・ポリシー設計で企業が陥りがちな7つのアンチパターンを解説します。

クラウドランディングゾーンは、クラウドインフラの土台です。リソースの整理方法や統制・ポリシーの設計次第で、その後のクラウド運用が順調に進むか、苦労続きになるかが大きく変わります。
たとえば、リソース階層をきちんと設計しておけば、クラウドコストの配賦やアクセス制御の設定が格段に楽になります。逆に階層設計が甘いと、どのコストをどのチームに紐づけるべきかで頭を悩ませることになり、本来見えてはいけないデータが他者の目に触れるリスクも高まります。
各クラウドプロバイダーはランディングゾーン構築のベストプラクティスを公開していますが、それでも現場では同じようなアンチパターンが繰り返されています。
3,000社を超えるデジタルネイティブ企業のクラウド課題を支援してきた経験をもとに、特によく見かけるランディングゾーンのアンチパターン7つと、本来_取るべき_対応をまとめました。
さっそく見ていきましょう。
アンチパターン #1:組織単位(OU)やフォルダを使っていない
フォルダ(Google Cloud)や組織単位(OU)(AWS)の構造をきちんと整備していないと、リソースが散在し、アクセス権や権限の管理が一気に難しくなります。
クラウドリソースは、実際の組織構造に沿って整理するのが理想です。フォルダ/OUは、まさにそのための仕組みです。
フォルダ/OUは、組織内の部門やチームごとにリソースを分離・分類するために使います。その配下にプロジェクト(Google Cloud)またはアカウント(AWS)を配置し、各workloadは1つのプロジェクト/アカウントに収めるのが基本です(これについては次のアンチパターンで詳しく取り上げます)。
フォルダやOUは、ポリシーや権限設定によるガードレールの実装にも有効です。たとえば特定部門のユーザーが利用しないリージョンへアクセスできないようブロックしたり、開発チームがGoogle CloudのT2DやAWSのX1といった特定インスタンスを使えないように制限したりできます。
とはいえ、フォルダ/OUはネスト可能だからといって、必要もないのに複雑にしすぎるのは禁物です。階層を増やすほど、全体を管理する手間も比例して増えていきます。

アンチパターン #2:すべてのリソースを単一のAWSアカウントやGoogle Cloudプロジェクトに詰め込む
すべてのworkloadを1つのアカウントやプロジェクトにまとめてしまうと、コスト管理、利用状況の把握、セキュリティ統制のいずれもが難しくなります。
たとえば、まったく別の2つのアプリケーションのリソースが、同じGoogle Cloudプロジェクト内に同居しているケースを想像してみてください。プロジェクト/アカウントでリソースを分離していないと、完璧なタグ付けポリシー(これは次のアンチパターンで解説します)に過度に依存することになります。支出の追跡や、特定のチーム・アプリケーション・環境へのコスト配賦が複雑化し、コスト削減の機会や効率的なリソース配分の特定が難しくなります。組織の成長とともに、この問題はさらに深刻化していきます。
さらに、すべてのリソースが単一のアカウントやプロジェクトに集中していると、セキュリティ侵害や設定ミスがすべてのサービスとworkloadに波及するおそれがあります(「ブラストレディウス(影響範囲)を小さくする」という観点で考えると、被害の抑制につながります)。
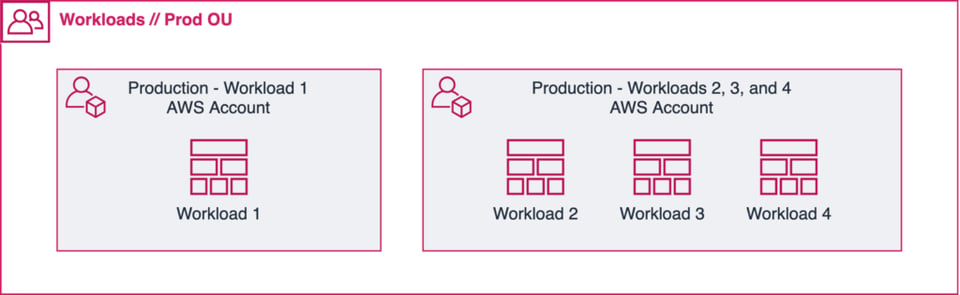
可能な限り、1アカウント/プロジェクトに1workloadを基本としましょう。ただし、規模が小さくスコープが似通ったworkloadが複数あるような場合は、まとめて同じアカウントに配置することもあります(上図参照)。
確かにアカウント数が少ないほど運用管理の負担は軽くなりますが、workloadを分離することで、権限構造やレート制限といった組み込みの運用セキュリティ機能の恩恵を受けられます(1アカウントに100個以上のバケットを作ろうとしたことがある方なら、こうした上限の存在をご存じでしょう)。
アンチパターン #3:タグ/ラベルを十分に使いこなしていない(またはまったく使っていない)
タグ(AWS)やラベル(Google Cloud)は、クラウドリソースに細かな情報を付与するための仕組みです。
主なユースケースは次のとおりです。
- 請求情報の補強(例:リソースにコストセンター情報を付与する)
- 環境/アプリケーションの分類(例:データセキュリティレベルの指定)
- 自動化(例:再起動スケジュールの判定)
…ここでは特に1つ目に絞って、タグがなぜそれほど重要なのかを見ていきましょう。
タグとラベルは、コスト配賦と追跡に欠かせない役割を担います。そして適切なコスト配賦は、クラウド支出を上手く管理するための土台となります。
タグ付けが甘いと、特定のプロジェクト・部門・チームに支出を紐づけることが難しくなります。タグやラベルを使いこなせていないということは、詳細なインサイトの抽出、利用傾向の追跡、意思決定に役立つ実のあるレポート作成といった機会を逃しているということです。粒度の不足は、コストの非効率、過剰支出、最適化ポイントの特定の難しさにつながります。
タグ設計では、すべてのリソースに適用すべき多種多様なタグを盛り込んだ詳細な体系を最初から作り込みたくなるかもしれません。志は立派ですが、最初からそれをやろうとするのは現実的ではありません。まずは小さく始めて、2〜3個のタグに絞り、その運用を厳格に徹底することをおすすめします。
絶対に外せないタグは、次の3つだと考えています。
- アプリケーション名
- チーム
- ステージ/環境
タグは大文字・小文字を区別するため、スネークケースなどの命名規則を採用し、表記ゆれによる重複を防ぐことをおすすめします。名称は会社の文化に合わせて変えても構いませんが、わかりやすく明確であることが大切です。ここでの「app_name」はマイクロサービス名やworkload名を、「env」は「development」「testing」「production」といった開発ステージを指します。
両フィールドの値は、できる限り標準化されたリストから選ぶようにしましょう。たとえばユーザーが「Website - Frontend」のような表記揺れを混在させてしまうと、後でデータを分析する際に支障が出ます。
タグがクラウド利用状況の理解に役立つ一例として、組織内に「共有リソース」アカウントがあり、複数チームで使うデータベースリソースがすべてそこに集まっているケースが挙げられます。各データベースに、利用料を負担すべきチームを示すタグやラベルを割り当てることで、コストを適切に振り分けられます。
詳しくはリソースラベリングのベストプラクティスのブログ記事をご覧ください。
アンチパターン #4:複数チームでGoogle CloudプロジェクトやAWSアカウントを共用する
アンチパターン#2と同じ理由で、チーム間でプロジェクト/アカウントを共用するとリソースガバナンスが効きにくくなり、アクセス権・権限・コストをめぐる衝突の火種になります。
性格の異なるチームを同じ部屋に押し込める様子を想像してみてください。誰も自分のスペースを確保できず、プライバシーもありません。クラウド上の共用プロジェクト/アカウントもこれに似ています。しかも全員が全員の部屋の鍵を持っている状態なので、立ち入るべきでない場所にうっかり踏み込んでしまうことも起こりがちです。チームごとに守るべきルールが違う場合もあり、リソースが入り混じった状態で全員に規律を守らせるのは至難の業です。さらに、セキュリティ侵害やインシデントが発生すると、アカウントを共有しているぶんだけ「ブラストレディウス(影響範囲)」が広がります。
リソースが一緒くたになっていれば、コストも当然混在してしまい、完璧なタグ付けでもしていない限りコスト配賦は困難になります。誰が何を頼んだか覚えていないまま、友人同士で割り勘するレストランの会計のようなものです。
さらに共用環境では、チーム間でリソースの取り合いが起こり、パフォーマンス低下やダウンタイムにつながる事態も発生します。
こうした事態を避けるには、アンチパターン#2と同じく「1workloadにつき1プロジェクト/アカウント」を基本ポリシーにしましょう。所有権が明確になり、管理もしやすく、他チームのリソースに意図せず干渉してしまうリスクも減らせます。
アンチパターン #5:AWS管理アカウント内でworkloadを動かす
たまに、すべてのリソースを管理アカウントに置いている顧客に出会うことがあります。会社をMVP(Minimum Viable Product)として立ち上げたときに、深く考えずにこのアカウントを使い始め、その後も会社が成長・進化するなかでそのまま開発を続けてきた、というパターンです。
AWS管理アカウントは管理機能専用にしておくべきで、ここにworkloadを載せてしまうと、設定ミスやセキュリティ脆弱性のリスクが高まります。
リソースを別アカウントに分けるべき重要な理由のひとつは、AWS Organizationsのサービスコントロールポリシー(SCP)が、管理アカウント内のユーザーやロールには適用されないためです。
管理アカウントとそのユーザー・ロールは、そのアカウントで_のみ_実行できるタスクに限定して使うことをおすすめします。例外として、AWS CloudTrailを有効化し、関連する証跡やログを管理アカウントに保管することは推奨されます。主な目的はセキュリティで、AWSアカウント内で誰がいつ何を変更したかを把握できるようにするためです。また、イベント用途にも使えるので、新しいEC2インスタンスが起動された際に対応するといったことも可能です。
前述のとおり、workloadはAWSの_メンバー_アカウントに分離するのが望ましいです。これによりセキュリティが高まり、管理がシンプルになり、リスクも抑えられます。
セキュリティポリシーの自動化不足
アンチパターン #6:セキュリティポリシーの自動化が不十分
セキュリティポリシーを手作業で適用していると、ミスが起きやすく時間もかかり、結果として侵害や過剰支出、リソースの非効率利用を招きます。
ポリシーを常時、人手で適用・検証・調整し続ける——そんな状況を想像してみてください。
目指したいのは、ベースラインのセキュリティ態勢を自動的に確立することです。理想を言えば、クラウド上に新しく作られるリソースには、関連するセキュリティポリシーが自動で適用される状態が望ましいでしょう。自動化の対象は、異種混在環境におけるセキュリティポリシーの統合だけではなく、(おそらくそれ以上に重要な)イベントの評価と是正にも及びます。安定したシステムであれば、ポリシーに基づいて人手を介さずにイベントへ対処でき、チームは価値創出に集中できます。AWS Config、Amazon EventBridge、Amazon GuardDutyといったサービスは、こうしたワークフローの構築に大いに役立ちます。
先ほど触れたように、特定のインスタンス(例:T2D)をチームに使わせたくない、あるいは現在運用していないリージョンで誰もインスタンスを起動できないようにしたい(暗号資産マイニング絡みの侵害でよく使われる手口です)、といったケースもあるでしょう。自動化されたセキュリティポリシーであれば、クラウド環境を継続的に監視し、検証済みの一貫した対応でこうしたチェックを実行できます。
アンチパターン #7:組織レベルのポリシーやベストプラクティスを軽視する
前述のとおり、安定した組織は自動化を通じてセキュリティポリシーや構成を統合し、リソースをより効率的に活用しています。そのためには、クラウド上のworkloadとデータを保護するうえでの主要な推進要因、責任を担うチーム、使用するツールを明確にしたクラウドガバナンス戦略が必要です。最低限の骨組みすらなければ、組織は規制リスク、リソースの非効率利用、脅威ベクトルへのさらされやすさといった問題を避けられません。
クラウドガバナンスはセキュリティ施策だけにとどまりません。クラウドを運用するチームから得られた知見は、リソースのより効率的な利用や、クラウドリソースを管理する各チームで共有すべきアーキテクチャのベストプラクティス策定にもつながります。より成熟した組織では、利用するリソースの種類(許可するサービスやマシンタイプなど)とセキュリティポリシーを盛り込んだリファレンスアーキテクチャを定義し、継続的にブラッシュアップしています。これにより、新しいプロダクトをデプロイするたびにアーキテクチャをゼロから設計し直す必要がなくなり、プロダクトチームの開発スピードが上がります。
こうしたランディングゾーンの落とし穴を把握して対処すれば、クラウド支出をより正確に把握し、コストを最適化し、セキュリティ態勢を強化する準備が整います。今回紹介したステップの多くは、特にコスト配賦の観点で大きな意味を持ちます。
クラウドコスト配賦をさらに深く知りたい方は、FinOps、コスト配賦、そしてDoiT Cloud Intelligence™を使ったコスト配賦の実践方法を解説したオンデマンドウェビナーをぜひご覧ください。