Les 7 anti-patterns que commettent les entreprises dans l'organisation de leurs ressources et la configuration de leurs contrôles et politiques.

Votre landing zone cloud est le socle de votre infrastructure cloud. La façon dont vous organisez vos ressources et configurez vos contrôles et politiques aura un impact considérable sur la fluidité — ou les remous — de votre parcours cloud.
Par exemple, une hiérarchie de ressources bien structurée vous simplifiera la vie pour allouer les coûts cloud et configurer le contrôle d'accès. À l'inverse, une hiérarchie mal pensée vous fera vous arracher les cheveux pour déterminer quelle équipe est responsable de quel coût, et augmentera le risque que des données soient consultées par des personnes non autorisées.
Et même si chaque fournisseur cloud publie un ensemble de bonnes pratiques pour réussir la mise en place de votre landing zone, nous continuons d'observer certains anti-patterns récurrents.
Forts de l'expérience acquise auprès de plus de 3 000 entreprises digital natives sur leurs enjeux cloud, nous avons identifié les 7 principaux anti-patterns de landing zone que nous rencontrons le plus souvent, et ce que vous devriez faire à la place.
Entrons dans le vif du sujet.
Anti-pattern #1 : ne pas utiliser les Organizational Units (OUs) ni les Folders
Ne pas mettre en place de structures appropriées de Folders (Google Cloud) ou d'Organizational Units (AWS) peut conduire à une prolifération des ressources et compliquer la gestion des accès et des permissions.
Idéalement, vos ressources cloud doivent être organisées d'une manière qui reflète la structure réelle de votre organisation, et les Folders/OUs sont un excellent moyen d'y parvenir.
Ils servent à séparer et catégoriser les ressources selon les différents départements et équipes de votre organisation. À l'intérieur, vous trouverez des projects (Google Cloud) ou des accounts (AWS), chacun de vos workloads appartenant à un seul project/account (nous y reviendrons dans le prochain anti-pattern).
Les Folders et OUs sont également parfaits pour poser des garde-fous via des politiques et des permissions. Vous pouvez par exemple bloquer l'accès des utilisateurs d'un département donné à des régions que vous n'utilisez pas. Ou empêcher les équipes de développement d'utiliser certains types d'instances comme les T2D dans Google Cloud ou les X1 dans AWS.
Les Folders/OUs peuvent être imbriqués, mais évitez de complexifier inutilement la structure. Plus vous ajoutez de niveaux à votre hiérarchie de ressources cloud, plus la gestion de l'ensemble devient laborieuse.

Anti-pattern #2 : héberger toutes les ressources dans un seul AWS account ou project Google Cloud
Lorsque vous regroupez tous vos workloads dans un seul account ou project, vous compliquez la gestion des coûts, le suivi de l'utilisation et l'application des contrôles de sécurité.
Imaginez par exemple avoir des ressources liées à deux applications différentes dans le même project Google Cloud. En n'isolant pas les ressources dans des projects/accounts distincts, vous devenez excessivement dépendant d'une politique de tagging parfaite (nous y reviendrons dans le prochain anti-pattern). Suivre les dépenses et attribuer les coûts à des équipes, applications ou environnements précis devient inextricable, ce qui freine votre capacité à identifier des opportunités d'économies et à allouer efficacement les ressources. Et la situation ne fera que s'aggraver à mesure que votre organisation grandira.
De plus, lorsque toutes les ressources sont concentrées dans un seul account ou project, la moindre faille de sécurité ou erreur de configuration peut potentiellement affecter l'ensemble des services et workloads (raisonner en termes de réduction du blast radius aide à atténuer l'impact des événements négatifs).
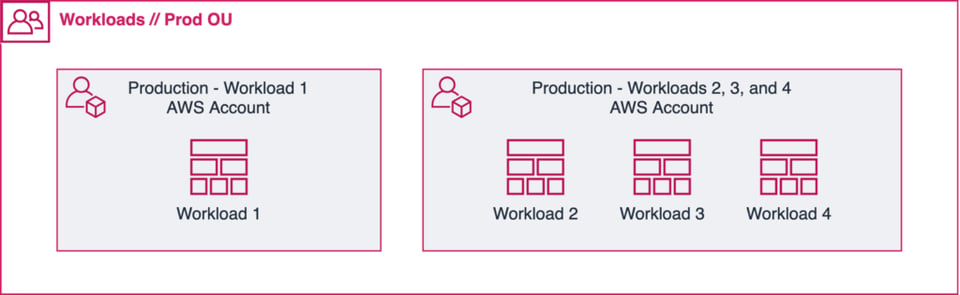
Quand c'est possible, optez pour un seul workload par account/project. Cela dit, lorsque vous avez de petits workloads dont la portée est similaire, il peut être judicieux de les regrouper dans le même account (voir l'illustration ci-dessus).
Enfin, même si moins d'accounts implique moins d'administration, séparer vos workloads vous permet de bénéficier des fonctionnalités de sécurité opérationnelle natives comme les structures de permissions et le rate-limiting (quiconque a déjà tenté de placer plus de 100 buckets dans un account connaît bien ces limites).
Anti-pattern #3 : sous-utiliser les Tags/Labels (ou ne pas les utiliser du tout)
Les Tags (AWS) et Labels (Google Cloud) servent à fournir des informations fines sur vos ressources cloud.
Parmi les cas d'usage :
- Enrichissement de la facturation (ex. ajouter une information de centre de coûts à une ressource)
- Classification des environnements/applications (ex. préciser les niveaux de sécurité des données)
- Automatisation (ex. définir les calendriers de redémarrage)
…mais concentrons-nous sur le premier point et sur l'importance des tags.
Les tags et labels jouent un rôle crucial dans l'allocation et le suivi des coûts. Et une bonne allocation des coûts est la clé d'une gestion réussie de vos dépenses cloud.
Sans tagging adéquat, il devient difficile d'associer les dépenses à des projets, départements ou équipes spécifiques. Renoncer aux tags et labels, c'est passer à côté de l'opportunité de générer des insights détaillés, de suivre les tendances d'utilisation et de produire des rapports exploitables pour décider en connaissance de cause. Ce manque de granularité conduit à des inefficacités, à des dépassements budgétaires et à des difficultés pour repérer les pistes d'optimisation.
En matière de tagging, il peut être tentant de définir une structure très détaillée comportant de nombreux tags à appliquer à chaque ressource. Ce niveau d'exigence est louable, mais irréaliste au démarrage. Nous recommandons de commencer modestement avec 2 ou 3 tags seulement, mais d'être très strict sur leur application.
Les trois tags absolument indispensables (selon nous) sont :
- Nom de l'application
- Équipe
- Stage/Environnement
Les tags étant sensibles à la casse, nous recommandons d'adopter une convention de nommage, comme le snake case, pour éviter les doublons. Les noms peuvent bien sûr être adaptés à la culture de votre entreprise, mais ils doivent rester descriptifs et clairs. Dans cet exemple, app_name désigne le nom d'un microservice ou d'un workload, et env correspond à un stade de développement, comme development, testing ou production.
Les valeurs des deux champs devraient idéalement provenir d'une liste relativement standardisée — là encore, si des utilisateurs taguent leurs ressources avec des variantes de Website - Frontend, l'analyse des données s'en trouvera compliquée.
Un exemple où les tags vous aideront à mieux comprendre votre consommation cloud : un account de ressources partagées au sein d'une organisation, regroupant toutes les ressources de bases de données utilisées par plusieurs équipes. Pour chaque base, vous pouvez attribuer un tag ou label déterminant quelle équipe doit être facturée pour son utilisation.
Nous approfondissons ce sujet dans notre article Resource Labeling Best Practices.
Anti-pattern #4 : partager des projects Google Cloud ou des AWS accounts entre différentes équipes
Pour des raisons similaires à l'anti-pattern #2, le partage de projects/accounts entre équipes nuit à la gouvernance des ressources et crée des conflits potentiels autour des accès, des permissions et des coûts.
Imaginez entasser plusieurs équipes dans la même pièce. Personne n'a son propre espace, ni la moindre intimité. Les projects/accounts partagés dans le cloud, c'est un peu pareil — sauf que chacun a les clés des chambres des autres, ce qui rend bien plus facile l'incursion dans des endroits où l'on ne devrait pas être. Les équipes peuvent avoir des règles différentes à respecter, et il devient difficile de tenir tout le monde dans le rang lorsque les ressources sont mélangées. De plus, en cas de faille ou d'incident de sécurité, le blast radius s'élargit dès lors que des équipes partagent un account.
Avec des ressources regroupées, les coûts se mêlent eux aussi, rendant l'allocation difficile — sauf à disposer d'un tagging parfait. C'est comme partager une addition au restaurant entre amis quand personne ne se souvient de ce qu'il a commandé.
Enfin, dans une configuration partagée, vous verrez des équipes finir par se disputer les ressources, avec à la clé baisses de performance et temps d'arrêt.
À la place, suivez le conseil de l'anti-pattern #2 et adoptez une politique un workload, un project/account. Cela garantit une propriété claire, une gestion plus simple et réduit le risque d'interférences involontaires avec les ressources des autres.
Anti-pattern #5 : exécuter des workloads dans le management account AWS
Il nous arrive de rencontrer un client dont toutes les ressources se trouvent dans le management account, parce qu'il a démarré son entreprise sous forme de Minimum Viable Product (MVP) dans cet account, sans trop y réfléchir. Puis, à mesure que l'entreprise grandissait et évoluait, il a continué à construire dans ce même account.
Le management account AWS doit être réservé aux fonctions administratives ; y héberger des workloads augmente le risque d'erreurs de configuration et d'exposition à des vulnérabilités de sécurité.
Une raison majeure de garder vos ressources dans d'autres accounts : les service control policies (SCPs) d'une AWS Organization ne permettent pas de restreindre les utilisateurs ou rôles du management account.
Nous recommandons d'utiliser le management account ainsi que ses utilisateurs et rôles uniquement pour les tâches qui ne peuvent être effectuées que par cet account. Une exception : nous recommandons d'activer AWS CloudTrail et de conserver les trails et logs CloudTrail pertinents dans le management account. Sa vocation première est la sécurité : savoir qui a modifié quoi et quand dans votre AWS account. Mais il peut aussi servir pour les événements — vous permettant par exemple de réagir au lancement d'une nouvelle EC2 Instance.
Comme évoqué plus haut, vous devriez chercher à isoler vos workloads dans des AWS member accounts distincts. Cette séparation renforce la sécurité, simplifie la gestion et atténue les risques.
Manque d'automatisation des politiques de sécurité
Anti-pattern #6 : manque d'automatisation des politiques de sécurité
L'application manuelle des politiques de sécurité est sujette aux erreurs et chronophage, ouvrant la porte aux failles, aux dépassements budgétaires et à une utilisation inefficace des ressources.
Imaginez appliquer, valider et ajuster manuellement vos politiques — en permanence !
L'objectif doit être d'établir automatiquement une posture de sécurité de référence. Dans un monde idéal, chaque nouvelle ressource configurée dans le cloud se verrait automatiquement appliquer les politiques de sécurité pertinentes. L'automatisation ne se limite pas à consolider les politiques de sécurité dans des environnements hétérogènes : elle s'applique aussi (et peut-être surtout) à l'évaluation et à la remédiation des événements. Des systèmes stables peuvent remédier aux événements en s'appuyant sur des politiques, sans intervention humaine, ce qui permet aux équipes de se concentrer sur la création de valeur. Des services comme AWS Config, Amazon EventBridge et Amazon GuardDuty sont d'une aide précieuse pour mettre en place ces workflows.
Comme évoqué plus tôt, vous ne souhaitez peut-être pas que vos équipes utilisent certaines instances (ex. T2D). Ou empêcher quiconque de lancer des instances dans une région où vous n'opérez pas (tactique courante dans les failles liées au crypto-mining). Des politiques de sécurité automatisées peuvent surveiller en continu votre environnement cloud et effectuer ce type de vérifications avec des réponses validées et cohérentes.
Anti-pattern #7 : négliger les politiques et bonnes pratiques au niveau organisationnel
Comme indiqué plus haut, une organisation stable est capable de consolider ses politiques et configurations de sécurité via l'automatisation, afin d'utiliser les ressources plus efficacement. Cela suppose une stratégie de gouvernance cloud qui définisse les principaux leviers pour sécuriser les workloads et les données dans le cloud, les équipes responsables et les outils utilisés. Sans même un squelette minimal pour une telle stratégie, l'organisation s'expose inévitablement à des risques réglementaires, à une utilisation inefficace des ressources et à divers vecteurs de menace.
La gouvernance cloud ne repose pas uniquement sur les pratiques de sécurité. Les enseignements tirés par les équipes qui opèrent le cloud peuvent aussi conduire à une utilisation plus efficace des ressources et à la création de bonnes pratiques d'architecture, à partager entre les différentes équipes qui gèrent des ressources cloud. Les organisations les plus matures définissent et affinent en continu des architectures de référence précisant les types de ressources autorisés (services ou types de machines admis) et les politiques de sécurité : la vélocité des équipes produit s'en trouve renforcée, puisqu'elles n'ont plus à redévelopper une architecture de zéro pour chaque nouveau produit déployé.
En identifiant et en corrigeant ces écueils courants liés à la landing zone, vous serez bien armé pour mieux comprendre vos dépenses cloud, optimiser vos coûts et renforcer votre posture de sécurité. Beaucoup de ces étapes sont particulièrement déterminantes pour l'allocation des coûts.
Envie d'approfondir l'allocation des coûts cloud ? Visionnez notre webinaire à la demande sur le FinOps, l'allocation des coûts et la façon de la mettre en œuvre avec DoiT Cloud Intelligence™.