Os 7 antipadrões que as empresas cometem ao organizar recursos e configurar controles e políticas.

Sua landing zone na nuvem é a base da sua infraestrutura na nuvem. A forma como você organiza seus recursos e configura controles e políticas vai ter um impacto enorme em definir se a sua jornada na nuvem vai ser tranquila ou turbulenta.
Por exemplo, uma hierarquia de recursos bem estruturada facilita a sua vida na hora de alocar custos de nuvem e configurar o controle de acesso. Já uma hierarquia mal montada deixa você quebrando a cabeça para descobrir qual time é responsável por qual custo, além de aumentar as chances de alguém ver dados que não deveria.
E, embora todo provedor de nuvem descreva um conjunto de boas práticas para configurar a sua landing zone com sucesso, ainda vemos alguns antipadrões comuns acontecendo por aí.
Com base na experiência que acumulamos ajudando mais de 3.000 empresas digital natives nos seus desafios de nuvem, listamos os 7 principais antipadrões de landing zone que mais observamos — e o que você deveria estar fazendo no lugar.
Vamos ao que interessa.
Antipadrão #1: Não usar Organizational Units (OUs) e/ou Folders
Não estabelecer estruturas adequadas de Folder (Google Cloud) ou Organizational Unit (AWS) pode levar à proliferação descontrolada de recursos e dificultar o gerenciamento de acessos e permissões.
O ideal é que seus recursos de nuvem sejam organizados de uma forma que reflita a estrutura real da sua organização — e Folders/OUs são uma ótima maneira de fazer isso.
Eles servem para separar e categorizar recursos de diferentes departamentos/times dentro da sua organização. Dentro deles, você terá projects (Google Cloud) ou accounts (AWS), e cada um dos seus workloads pertence a um único project/account (falamos mais sobre isso no próximo antipadrão).
Folders e OUs também são ótimos para definir guardrails via políticas e permissões. Por exemplo, você pode querer impedir que usuários de um determinado departamento acessem regiões que você não usa. Ou evitar que times de desenvolvimento usem instâncias específicas, como T2Ds no Google Cloud ou X1s na AWS.
Mas, embora Folders/OUs possam ser aninhados, não complique demais sem necessidade. Quanto mais níveis você adicionar à hierarquia de recursos da sua nuvem, mais dor de cabeça vai ter para gerenciar tudo.

Antipadrão #2: Concentrar todos os recursos em uma única conta AWS ou project do Google Cloud.
Quando você junta todos os seus workloads em uma única conta ou project, fica difícil gerenciar custos, acompanhar uso e aplicar controles de segurança.
Por exemplo, imagine que você tem recursos de duas aplicações diferentes no mesmo project do Google Cloud. Ao não isolar recursos em projects/accounts diferentes, você acaba dependendo demais de ter uma política de tagging perfeita (mais sobre isso no próximo antipadrão). Rastrear despesas e atribuir custos a times, aplicações ou ambientes específicos vira uma confusão, o que dificulta identificar oportunidades de economia e fazer uma alocação eficiente de recursos. E isso só piora conforme a sua organização cresce.
Além disso, quando todos os recursos estão concentrados em uma única conta ou project, qualquer brecha de segurança ou má configuração pode afetar todos os serviços e workloads (pensar em redução do blast-radius ajuda a mitigar o impacto de eventos negativos).
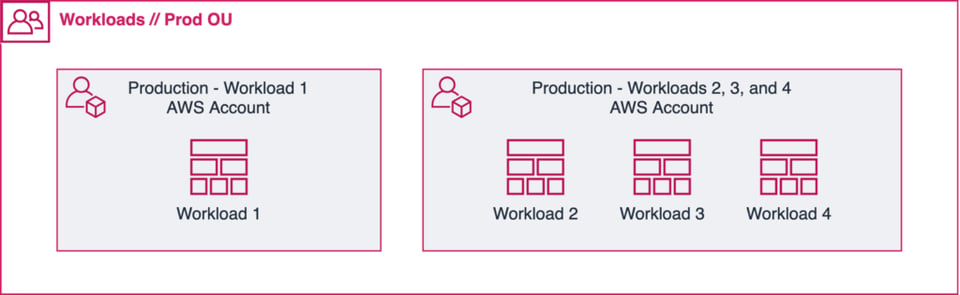
Sempre que possível, opte por um único workload por account/project. Mas, às vezes, quando você tem workloads pequenos e parecidos em escopo, pode fazer sentido colocar todos na mesma conta (veja a ilustração acima).
Por fim, embora menos contas signifiquem menos administração, ao separar seus workloads você ganha recursos operacionais de segurança nativos, como estruturas de permissão e rate-limiting (qualquer um que já tenha tentado colocar mais de 100 buckets em uma conta sabe bem o que são esses limites).
Antipadrão #3: Subutilizar Tags/Labels (ou simplesmente não usar)
Tags (AWS) e Labels (Google Cloud) servem para fornecer informações granulares sobre seus recursos de nuvem.
Os casos de uso incluem:
- Enriquecimento de billing (ex.: adicionar informação de centro de custo a um recurso)
- Classificação de ambiente/aplicação (ex.: especificar níveis de segurança de dados)
- Automação (ex.: definir agendamentos de reboot)
…mas vamos focar no primeiro ponto e em por que as tags são tão importantes.
Tags e labels têm um papel essencial na alocação e no rastreamento de custos. E uma boa alocação de custos é o que prepara você para gerenciar seus gastos com nuvem com sucesso.
Sem um tagging adequado, fica difícil associar despesas a projetos, departamentos ou times específicos. Não usar tags e labels é abrir mão da chance de gerar insights detalhados, acompanhar tendências de uso e produzir relatórios relevantes para tomar decisões embasadas. Essa falta de granularidade pode levar a ineficiências de custo, gastos excessivos e dificuldade em identificar áreas de otimização.
No tagging, pode ser tentador definir uma estrutura altamente detalhada com várias tags diferentes que devem ser aplicadas a cada recurso. Esse nível de tagging é admirável, mas pouco realista logo no início. Recomendamos começar pequeno, com só 2 ou 3 tags, e ser bem rigoroso na aplicação delas.
As três tags absolutamente obrigatórias (na nossa opinião) são:
- Nome da aplicação
- Time
- Estágio/Ambiente
Como tags são case sensitive, recomendamos adotar um padrão de nomenclatura, como snake case, para evitar duplicação de tags. Os nomes podem, claro, ser ajustados à cultura da sua empresa, mas devem ser descritivos e claros. Nesse caso, "app_name" se refere ao nome de um microsserviço ou workload, e "env" é um estágio de desenvolvimento, como "development", "testing" ou "production".
Os valores dos dois campos devem, idealmente, vir de uma lista relativamente padronizada — de novo, se você tiver usuários taggeando recursos com variações de "Website - Frontend", isso pode causar problemas na hora de analisar os dados.
Um exemplo em que as tags ajudam a entender melhor o seu consumo de nuvem é quando há uma conta de "recursos compartilhados" dentro da organização e todos os recursos de banco de dados (usados por vários times) estão lá. Para cada banco de dados, você pode atribuir uma tag ou label que define qual time deve ser cobrado pelo uso daquele recurso.
Falamos mais sobre isso no nosso post Resource Labeling Best Practices.
Antipadrão #4: Compartilhar projects do Google Cloud ou contas AWS entre times diferentes.
Por motivos parecidos com os do Antipadrão #2, compartilhar projects/accounts entre times prejudica a governança de recursos e gera potenciais conflitos de acesso, permissões e custos.
Imagine espremer times diferentes na mesma sala. Ninguém tem o próprio espaço e não existe privacidade. Projects/accounts compartilhados na nuvem são um pouco assim — só que todo mundo tem a chave da sala dos outros, então fica muito mais fácil esbarrar em lugares onde não deveria. Times diferentes podem ter regras diferentes a seguir, e é difícil manter todo mundo na linha quando os recursos estão todos misturados. Sem contar que, se rolar uma brecha/incidente de segurança, o "blast radius" do impacto cresce quando os times compartilham uma conta.
Com recursos agrupados, os custos também se misturam, o que dificulta a alocação — a menos que o seu tagging seja perfeito. É como rachar a conta de um restaurante entre amigos quando ninguém lembra o que pediu.
Por fim, em um setup compartilhado, você vai se deparar com situações em que os times acabam disputando recursos, gerando lentidão e indisponibilidade.
Em vez disso, siga o conselho do Antipadrão #2 e adote a política de um workload por project/account. Isso garante propriedade clara, gerenciamento mais fácil e reduz o risco de interferência involuntária nos recursos dos outros.
Antipadrão #5: Rodar workloads dentro da management account da AWS.
De vez em quando, encontramos um cliente que tem todos os recursos na management account porque a empresa começou como um Minimum Viable Product (MVP) ali, talvez sem pensar duas vezes. Aí, conforme a empresa cresceu e evoluiu, simplesmente continuou construindo dentro dessa conta.
A management account da AWS deve ser reservada para funções administrativas, e hospedar workloads ali aumenta o risco de configurações incorretas acidentais e de exposição a vulnerabilidades de segurança.
Um motivo importante para manter seus recursos em outras contas é que as service control policies (SCPs) de uma AWS Organization não conseguem restringir usuários ou roles dentro da management account.
Recomendamos usar a management account, seus usuários e roles exclusivamente para tarefas que só podem ser executadas por essa conta. A única exceção é o AWS CloudTrail: recomendamos sim habilitá-lo e manter as trilhas e logs relevantes do CloudTrail na management account. O propósito principal é segurança, para você saber quem mudou o quê e quando na sua conta AWS. Mas também dá para usar para eventos — assim, você pode reagir quando uma nova EC2 Instance é lançada.
Como dito acima, busque isolar workloads em member accounts separadas da AWS. Essa separação melhora a segurança, simplifica o gerenciamento e reduz riscos.
Falta de Automação em Políticas de Segurança
Antipadrão #6: Falta de automação nas políticas de segurança
Aplicar políticas de segurança manualmente é propenso a erros e demorado, podendo levar a brechas, gastos excessivos e uso ineficiente de recursos.
Imagine aplicar, validar e ajustar políticas manualmente — o tempo todo!
O ideal é estabelecer uma postura de segurança baseline de forma automática. Em um mundo perfeito, todo novo recurso configurado na nuvem teria as políticas de segurança relevantes aplicadas automaticamente. A automação não serve só para consolidar políticas de segurança em ambientes heterogêneos, mas também (talvez ainda mais importante) para a avaliação e remediação de eventos. Sistemas estáveis conseguem remediar eventos com base em políticas sem intervenção humana, o que permite que os times foquem na criação de valor. Serviços como AWS Config, Amazon EventBridge e Amazon GuardDuty ajudam muito a montar esses workflows.
Como mencionamos antes, talvez você não queira que seus times usem instâncias específicas (ex.: T2D). Ou não queira que ninguém suba instâncias em uma região onde você não opera atualmente (uma tática comum em brechas relacionadas a mineração de cripto). Políticas de segurança automatizadas conseguem monitorar continuamente o seu ambiente de nuvem e fazer esse tipo de checagem com respostas validadas e consistentes.
Antipadrão #7: Negligenciar políticas e boas práticas em nível organizacional.
Como dito acima, uma organização estável consegue consolidar políticas de segurança e configurações via automação, usando recursos de forma mais eficiente. Para isso, é preciso ter uma estratégia de cloud governance em vigor, deixando claros os principais drivers para proteger workloads e dados na nuvem, os times responsáveis e as ferramentas que serão usadas. Não ter pelo menos um esqueleto dessa estratégia inevitavelmente expõe a organização a risco regulatório, uso ineficiente de recursos e exposição a vetores de ameaça.
Cloud Governance não se baseia só em práticas de segurança. As lições aprendidas pelos times que operam a nuvem também podem levar a um uso mais eficiente dos recursos e à criação de boas práticas de arquitetura, que devem ser compartilhadas entre os diferentes times que gerenciam recursos na nuvem. Organizações mais avançadas definem e refinam constantemente arquiteturas de referência que incluem tipos de recursos a usar (pense em serviços ou tipos de máquina permitidos) e políticas de segurança: isso aumenta a velocidade do time de produto, já que ele não precisa redesenvolver uma arquitetura do zero a cada novo produto implantado.
Ao reconhecer e tratar essas armadilhas comuns de landing zone, você fica bem preparado para entender melhor seus gastos com nuvem, otimizar custos e fortalecer a sua postura de segurança. Muitos desses passos são especialmente decisivos para a alocação de custos.
Quer se aprofundar em alocação de custos na nuvem? Assista ao nosso webinar sob demanda sobre FinOps, alocação de custos e como executar a alocação de custos com o DoiT Cloud Intelligence™.