Los 7 antipatrones que cometen las empresas al organizar recursos y configurar controles y políticas.

Tu landing zone en la nube es la base de tu infraestructura cloud. La forma en que organices tus recursos y configures los controles y las políticas marcará una diferencia enorme entre un camino fluido en la nube o uno lleno de baches.
Por ejemplo, una jerarquía de recursos bien estructurada te facilitará la vida al asignar costos de la nube y configurar el control de accesos. En cambio, una jerarquía mal armada te tendrá rompiéndote la cabeza para descifrar qué equipo es responsable de cada costo y aumenta las probabilidades de que alguien vea datos que no debería.
Y aunque cada proveedor de nube describe un conjunto de buenas prácticas para configurar tu landing zone con éxito, seguimos viendo algunos antipatrones bastante comunes.
Con la experiencia que hemos acumulado ayudando a más de 3.000 empresas digital natives con sus retos en la nube, identificamos los 7 antipatrones de landing zone que más vemos y lo que deberías hacer en su lugar.
Vamos al grano.
Antipatrón #1: No utilizar Organizational Units (OUs) ni Folders
No establecer estructuras adecuadas de Folders (Google Cloud) u Organizational Units (AWS) puede derivar en una proliferación descontrolada de recursos y en dificultades para gestionar accesos y permisos.
Lo ideal es que tus recursos en la nube se organicen de forma que reflejen la estructura real de tu empresa, y los Folders/OUs son una excelente manera de lograrlo.
Se usan para separar y categorizar recursos de los distintos departamentos o equipos de tu organización. Dentro de ellos tendrás projects (Google Cloud) o accounts (AWS), y cada uno de tus workloads pertenece a un único project/account (más sobre esto en el siguiente antipatrón).
Los Folders y las OUs también son ideales para definir guardarraíles mediante políticas y permisos. Por ejemplo, quizás quieras impedir que los usuarios de un departamento específico accedan a regiones que no usas. O tal vez prefieras evitar que los equipos de desarrollo usen ciertas instancias, como T2D en Google Cloud o X1 en AWS.
Pero aunque los Folders/OUs pueden anidarse, no conviene complicar las cosas a menos que sea realmente necesario. Cuantos más niveles agregues a la jerarquía de recursos en la nube, más dolores de cabeza tendrás para gestionar todo.

Antipatrón #2: Alojar todos los recursos en una sola cuenta de AWS o un único project de Google Cloud.
Cuando agrupas todos tus workloads en una sola cuenta o project, gestionar costos, hacer seguimiento del uso y aplicar controles de seguridad se vuelve un dolor de cabeza.
Imagina, por ejemplo, que tienes recursos de dos aplicaciones distintas en el mismo project de Google Cloud. Al no aislar los recursos en distintos projects/accounts, terminas dependiendo demasiado de tener una política de tagging perfecta (más sobre esto en el siguiente antipatrón). Hacer seguimiento de los gastos y atribuir costos a equipos, aplicaciones o entornos específicos se vuelve enredado, lo que dificulta detectar oportunidades de ahorro y una asignación eficiente de los recursos. Y esto solo se complicará más a medida que tu organización crezca.
Además, cuando todos los recursos se concentran en una sola cuenta o project, cualquier brecha de seguridad o configuración incorrecta puede llegar a afectar a todos los servicios y workloads (pensar en términos de reducción del "blast radius" ayuda a mitigar el impacto de eventos negativos).
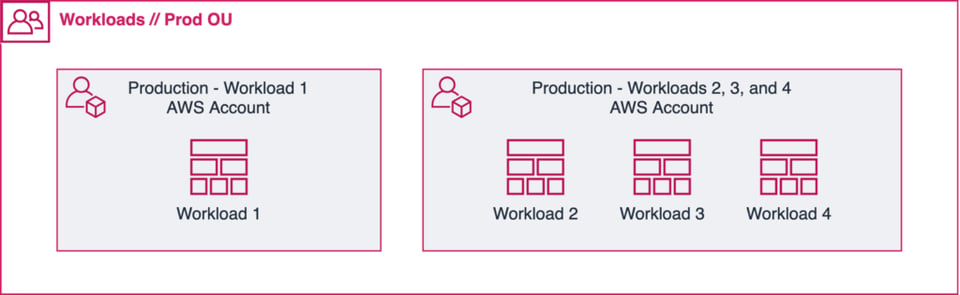
Cuando sea posible, opta por un solo workload por cada account/project. Sin embargo, a veces, cuando tienes workloads pequeños y similares en alcance, puede tener sentido ponerlos todos en la misma cuenta (ver la ilustración de arriba).
Por último, si bien con menos cuentas tienes menos administración, al separar tus workloads aprovechas funciones de seguridad operativa integradas, como las estructuras de permisos y el rate-limiting (cualquiera que haya intentado meter más de 100 buckets en una cuenta sabe bien de esos límites).
Antipatrón #3: Subutilizar Tags/Labels (o no usarlos)
Los Tags (AWS) y los Labels (Google Cloud) sirven para aportar información detallada sobre tus recursos en la nube.
Algunos casos de uso son:
- Enriquecer la facturación (p. ej., agregar información de centro de costo a un recurso)
- Clasificar entornos/aplicaciones (p. ej., especificar niveles de seguridad de los datos)
- Automatización (p. ej., definir horarios de reinicio)
…pero centrémonos en el primer punto y en por qué los tags son tan importantes.
Los tags y labels juegan un papel clave en la asignación y el seguimiento de costos. Y una buena asignación de costos es la base para gestionar bien tu gasto en la nube.
Sin un tagging adecuado, asociar gastos a projects, departamentos o equipos específicos se vuelve complicado. No usar tags y labels significa perder la oportunidad de obtener insights detallados, dar seguimiento a tendencias de uso y generar reportes útiles para tomar decisiones informadas. Esa falta de granularidad puede traducirse en ineficiencias de costos, sobregastos y dificultades para identificar áreas de optimización.
Con el tagging puede ser tentador definir una estructura muy detallada, con muchos tags distintos para aplicar a cada recurso. Aunque ese nivel de detalle es admirable, no es realista al empezar. Recomendamos arrancar con poco —solo 2 o 3 tags— pero siendo muy estrictos en su cumplimiento.
Los tres tags absolutamente imprescindibles (en nuestra opinión) son:
- Nombre de la aplicación
- Equipo
- Etapa/Entorno
Como los tags distinguen mayúsculas de minúsculas, recomendamos adoptar un estándar de nomenclatura, como snake case, para evitar duplicados. Los nombres pueden adaptarse, claro, a la cultura de tu empresa, pero deben ser descriptivos y claros. En este caso, "app_name" se refiere al nombre de un microservicio o workload, y "env" es la etapa de desarrollo, como "development", "testing" o "production".
Lo ideal es que los valores de ambos campos provengan de una lista relativamente estandarizada; de nuevo, si tus usuarios etiquetan sus recursos con variantes de "Website - Frontend", podrías tener problemas al analizar los datos.
Un ejemplo donde los tags te ayudarán a entender mejor tu consumo en la nube es cuando, dentro de una organización, hay una cuenta de "recursos compartidos" donde están todos los recursos de base de datos (usados por varios equipos). A cada base de datos puedes asignarle un tag o label que determine qué equipo debe asumir el costo del uso de ese recurso.
Profundizamos más en esto en nuestro post sobre Buenas prácticas de Resource Labeling.
Antipatrón #4: Compartir projects de Google Cloud o cuentas de AWS entre distintos equipos.
Por razones similares al Antipatrón #2, compartir projects/accounts entre equipos dificulta la gobernanza de recursos y genera posibles conflictos por accesos, permisos y costos.
Imagínate meter a varios equipos en la misma sala. Nadie tiene su propio espacio y no hay privacidad. Compartir projects/accounts en la nube es algo parecido, con el agravante de que todos tienen las llaves de las habitaciones de los demás, así que es mucho más fácil que alguien acabe en lugares donde no debería estar. Distintos equipos pueden tener distintas reglas y resulta complicado mantener a todo el mundo alineado cuando los recursos están mezclados. Además, ante una brecha o incidente de seguridad, el "blast radius" se amplía cuando hay equipos compartiendo una cuenta.
Con los recursos agrupados, los costos también se mezclan, lo que complica la asignación, salvo que tengas un tagging perfecto. Es como dividir la cuenta de un restaurante entre amigos cuando nadie recuerda qué pidió.
Por último, en un esquema compartido, terminarás viendo a equipos peleando por los recursos, lo que se traduce en bajo rendimiento y caídas.
En su lugar, sigue el consejo del Antipatrón #2 y aplica una política de un workload por project/account. Eso garantiza una propiedad clara, una gestión más sencilla y reduce el riesgo de interferencias no intencionales con los recursos de otros.
Antipatrón #5: Ejecutar workloads dentro de la cuenta de management de AWS.
De vez en cuando nos encontramos con un cliente que tiene todos sus recursos en la cuenta de management porque arrancó su empresa como un Minimum Viable Product (MVP) en esa cuenta, quizás sin pensarlo demasiado. Luego, a medida que la empresa creció y evolucionó, simplemente siguió construyendo sobre esa misma cuenta.
La cuenta de management de AWS debe reservarse para funciones administrativas; alojar workloads ahí aumenta el riesgo de configuraciones erróneas accidentales y de exposición a vulnerabilidades de seguridad.
Una razón importante para mantener tus recursos en otras cuentas es que las service control policies (SCPs) de una AWS Organization no sirven para restringir a los usuarios o roles de la cuenta de management.
Recomendamos usar la cuenta de management y sus usuarios y roles únicamente para tareas que solo puedan realizarse desde esa cuenta. La excepción es que sí recomendamos habilitar AWS CloudTrail y mantener los trails y logs relevantes de CloudTrail en la cuenta de management. Su propósito principal es la seguridad, para que sepas quién cambió qué y cuándo en tu cuenta de AWS. Pero también puede usarse para eventos, de modo que puedas reaccionar cuando se lance una nueva instancia EC2.
Como mencionamos arriba, conviene aislar los workloads en cuentas member separadas de AWS. Esa separación refuerza la seguridad, simplifica la gestión y mitiga riesgos.
Falta de automatización en las políticas de seguridad
Antipatrón #6: Falta de automatización en las políticas de seguridad
Aplicar manualmente las políticas de seguridad es propenso a errores y consume mucho tiempo, lo que puede derivar en brechas, sobregastos y un uso ineficiente de los recursos.
Imagina aplicar, validar y ajustar políticas a mano… ¡todo el tiempo!
El objetivo debe ser establecer una postura de seguridad base de forma automática. En un mundo ideal, cada nuevo recurso configurado en la nube tendrá automáticamente las políticas de seguridad correspondientes. La automatización no solo sirve para consolidar políticas de seguridad en entornos heterogéneos, sino también (y quizás más importante aún) para la evaluación y remediación de eventos. Los sistemas estables podrán remediar eventos en función de políticas sin intervención humana, lo que permite a los equipos enfocarse en generar valor. Servicios como AWS Config, Amazon EventBridge y Amazon GuardDuty ayudan muchísimo a crear estos workflows.
Como mencionamos antes, quizás no quieras que tus equipos usen ciertas instancias (p. ej., T2D). O que nadie pueda lanzar instancias en una región donde actualmente no operas (una táctica habitual en brechas relacionadas con minería de criptomonedas). Las políticas de seguridad automatizadas pueden monitorear continuamente tu entorno cloud y realizar este tipo de comprobaciones con respuestas validadas y consistentes.
Antipatrón #7: Pasar por alto las políticas y buenas prácticas a nivel organizacional.
Como mencionamos arriba, una organización estable es capaz de consolidar políticas y configuraciones de seguridad mediante automatización, para usar los recursos de forma más eficiente. Esto exige contar con una estrategia de cloud governance que defina cuáles son los principales objetivos para asegurar workloads y datos en la nube, los equipos responsables y las herramientas que se utilizarán. No tener al menos un esqueleto mínimo de esta estrategia expone inevitablemente a la organización a riesgo regulatorio, uso ineficiente de recursos y exposición a vectores de amenaza.
El Cloud Governance no se basa únicamente en prácticas de seguridad. Las lecciones aprendidas por los equipos que operan la nube también pueden derivar en un uso más eficiente de los recursos y en la creación de buenas prácticas de arquitectura que conviene compartir entre los distintos equipos que gestionan recursos cloud. Las organizaciones más maduras definen y refinan continuamente arquitecturas de referencia que incluyen los tipos de recursos a usar (piensa en servicios o tipos de máquina permitidos) y las políticas de seguridad: esto incrementa la velocidad del equipo de producto, ya que no tendrá que rediseñar una arquitectura desde cero por cada nuevo producto que se despliegue.
Al reconocer y abordar estos errores comunes en las landing zones, estarás mejor preparado para entender tu gasto en la nube, optimizar costos y reforzar tu postura de seguridad. Muchos de estos pasos son especialmente clave para la asignación de costos.
¿Quieres profundizar en la asignación de costos en la nube? Mira nuestro webinar on-demand sobre FinOps, asignación de costos y cómo realizarla con DoiT Cloud Intelligence™.