Die 7 Anti-Patterns, die Unternehmen bei der Strukturierung ihrer Ressourcen sowie beim Aufsetzen von Kontrollen und Richtlinien begehen.

Ihre Cloud Landing Zone ist das Fundament Ihrer Cloud-Infrastruktur. Wie Sie Ihre Ressourcen organisieren und Kontrollen sowie Richtlinien aufsetzen, entscheidet maßgeblich darüber, ob Ihr Weg in die Cloud reibungslos verläuft oder zur Holperpartie wird.
Eine durchdachte Ressourcenhierarchie macht Ihnen das Leben deutlich leichter, wenn es um die Zuordnung von Cloud-Kosten und die Konfiguration von Zugriffsrechten geht. Eine schlecht aufgesetzte Hierarchie hingegen sorgt dafür, dass Sie sich den Kopf darüber zerbrechen, welches Team für welche Kosten verantwortlich ist – und erhöht das Risiko, dass jemand Daten zu Gesicht bekommt, die nicht für ihn bestimmt sind.
Und obwohl jeder Cloud-Anbieter Best Practices für eine erfolgreiche Cloud Landing Zone beschreibt, sehen wir in der Praxis immer wieder dieselben Anti-Patterns.
Auf Basis unserer Erfahrung aus der Begleitung von über 3.000 Digital-Native-Unternehmen bei ihren Cloud-Herausforderungen haben wir die 7 häufigsten Landing-Zone-Anti-Patterns zusammengestellt – und zeigen Ihnen, was Sie stattdessen tun sollten.
Legen wir los.
Anti-Pattern #1: Organizational Units (OUs) und/oder Folders nicht nutzen
Wer keine sauberen Folder- (Google Cloud) oder Organizational-Unit-Strukturen (AWS) etabliert, riskiert Wildwuchs bei Ressourcen und Probleme bei der Verwaltung von Zugriffen und Berechtigungen.
Idealerweise sollten Ihre Cloud-Ressourcen so organisiert sein, dass sie Ihre tatsächliche Unternehmensstruktur abbilden – Folders/OUs sind dafür hervorragend geeignet.
Sie dienen dazu, Ressourcen für unterschiedliche Abteilungen oder Teams Ihres Unternehmens zu trennen und zu kategorisieren. Innerhalb dieser Strukturen liegen Projekte (Google Cloud) bzw. Accounts (AWS), wobei jeder Ihrer workloads zu genau einem Projekt/Account gehören sollte (mehr dazu im nächsten Anti-Pattern).
Folders und OUs eignen sich außerdem hervorragend, um über Richtlinien und Berechtigungen Leitplanken zu setzen. So können Sie etwa Nutzer:innen einer bestimmten Abteilung den Zugriff auf nicht genutzte Regionen verwehren. Oder verhindern, dass Entwicklungsteams bestimmte Instanztypen wie T2Ds in Google Cloud oder X1s in AWS einsetzen.
Folders/OUs lassen sich zwar verschachteln, doch übertreiben Sie es nicht ohne Grund. Je mehr Ebenen Ihre Cloud-Ressourcenhierarchie hat, desto höher der Verwaltungsaufwand.

Anti-Pattern #2: Alle Ressourcen in einem einzigen AWS-Account oder Google-Cloud-Projekt unterbringen
Wenn Sie all Ihre workloads in einem einzigen Account oder Projekt bündeln, wird es schwierig, Kosten zu steuern, die Nutzung nachzuvollziehen und Sicherheitskontrollen durchzusetzen.
Stellen Sie sich vor, Ressourcen für zwei unterschiedliche Anwendungen liegen im selben Google-Cloud-Projekt. Wer Ressourcen nicht in eigene Projekte/Accounts isoliert, ist zwangsläufig auf eine makellose Tagging-Strategie angewiesen (mehr dazu im nächsten Anti-Pattern). Ausgaben nachzuverfolgen und Kosten gezielt Teams, Anwendungen oder Umgebungen zuzuordnen, wird schnell unübersichtlich – und erschwert es, Einsparpotenziale und eine effiziente Ressourcenverteilung zu erkennen. Mit dem Wachstum Ihres Unternehmens wird das nur komplizierter.
Hinzu kommt: Sind alle Ressourcen in einem einzigen Account oder Projekt konzentriert, kann jeder Sicherheitsvorfall oder jede Fehlkonfiguration potenziell sämtliche Services und workloads betreffen (in Begriffen einer reduzierten "Blast Radius" zu denken, hilft, die Auswirkungen negativer Ereignisse einzudämmen).
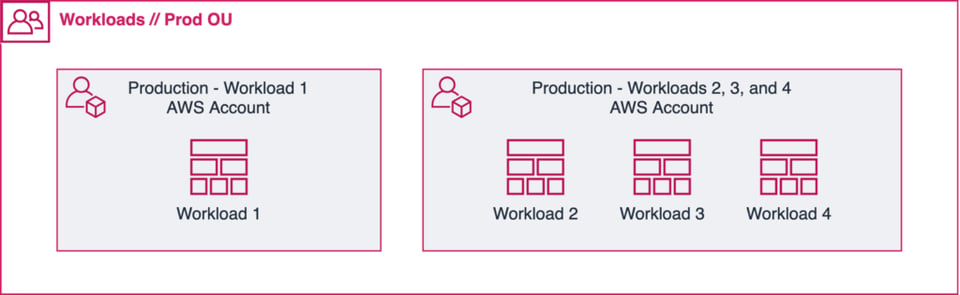
Wenn möglich gilt: ein Workload pro Account/Projekt. Bei kleinen workloads mit ähnlichem Scope kann es jedoch sinnvoll sein, sie gemeinsam in einem Account zu betreiben (siehe Abbildung oben).
Und auch wenn weniger Accounts weniger Verwaltungsaufwand bedeuten: Durch die Trennung Ihrer workloads profitieren Sie von eingebauten operativen Sicherheitsfeatures wie Berechtigungsstrukturen und Rate-Limits (wer schon einmal versucht hat, mehr als 100 Buckets in einen Account zu packen, kennt diese Limits).
Anti-Pattern #3: Tags/Labels zu wenig (oder gar nicht) nutzen
Tags (AWS) und Labels (Google Cloud) liefern feingranulare Informationen zu Ihren Cloud-Ressourcen.
Typische Anwendungsfälle:
- Anreicherung der Abrechnung (z. B. Cost-Center-Information an einer Ressource)
- Klassifizierung von Umgebungen/Anwendungen (z. B. Datensicherheitsstufen)
- Automatisierung (z. B. Reboot-Zeitpläne)
… konzentrieren wir uns aber auf den ersten Punkt und darauf, warum Tags so wichtig sind.
Tags und Labels spielen eine zentrale Rolle bei der Kostenzuordnung und -nachverfolgung. Und eine saubere Kostenzuordnung ist die Grundlage für ein erfolgreiches Cloud-Kostenmanagement.
Ohne sauberes Tagging lassen sich Ausgaben nur schwer bestimmten Projekten, Abteilungen oder Teams zuordnen. Wer auf Tags und Labels verzichtet, verschenkt die Chance auf detaillierte Insights, Trendanalysen und aussagekräftige Reports für fundierte Entscheidungen. Diese fehlende Granularität führt zu ineffizienten Kosten, Mehrausgaben und Schwierigkeiten beim Aufspüren von Optimierungspotenzialen.
Beim Tagging mag es verlockend sein, gleich eine hochdetaillierte Struktur mit vielen Tags zu definieren, die auf jede Ressource angewendet werden sollen. So lobenswert dieser Anspruch ist – zu Beginn ist er unrealistisch. Wir empfehlen, klein anzufangen, nur 2–3 Tags zu nutzen und deren Einhaltung dafür konsequent durchzusetzen.
Die drei aus unserer Sicht absolut unverzichtbaren Tags sind:
- Application Name
- Team
- Stage/Environment
Da Tags case-sensitive sind, empfehlen wir eine einheitliche Namenskonvention wie Snake Case, um Dubletten zu vermeiden. Die Namen lassen sich selbstverständlich an Ihre Unternehmenskultur anpassen, sollten aber aussagekräftig und eindeutig sein. In diesem Beispiel bezeichnet "app_name" einen Microservice oder Workload-Namen, und "env" steht für eine Entwicklungsstufe wie "development", "testing" oder "production".
Werte für beide Felder sollten idealerweise aus einer relativ standardisierten Liste stammen – wenn Nutzer:innen ihre Ressourcen mit Varianten von "Website - Frontend" taggen, wird die Datenanalyse zur Qual.
Ein Beispiel, in dem Tags Ihren Cloud-Verbrauch deutlich transparenter machen: Es gibt im Unternehmen einen "Shared Resource"-Account, in dem alle Datenbankressourcen liegen, die von mehreren Teams genutzt werden. Für jede Datenbank lässt sich ein Tag oder Label vergeben, das festlegt, welchem Team die Nutzung dieser Ressource verrechnet wird.
Mehr dazu lesen Sie in unserem Blogpost zu Resource Labeling Best Practices.
Anti-Pattern #4: Google-Cloud-Projekte oder AWS-Accounts teamübergreifend gemeinsam nutzen
Aus ähnlichen Gründen wie bei Anti-Pattern #2 erschwert das Teilen von Projekten/Accounts zwischen Teams die Ressourcen-Governance und führt zu Konflikten rund um Zugriffe, Berechtigungen und Kosten.
Stellen Sie sich vor, Sie quetschen mehrere Teams in denselben Raum. Niemand hat seinen eigenen Bereich, von Privatsphäre keine Spur. Geteilte Projekte/Accounts in der Cloud sind ein wenig so – nur dass jeder den Schlüssel zum Zimmer aller anderen besitzt. Da landet man schnell mal an Orten, an denen man nichts verloren hat. Unterschiedliche Teams haben womöglich unterschiedliche Regeln zu befolgen, und Ordnung zu halten ist schwierig, wenn alle Ressourcen vermischt sind. Kommt es zu einem Sicherheitsvorfall, wächst der "Blast Radius" schlagartig, sobald sich Teams einen Account teilen.
Auch die Kosten verschwimmen, sobald Ressourcen zusammengelegt werden – die Kostenzuordnung wird zur Herausforderung, sofern das Tagging nicht lückenlos ist. Es ist wie das Aufteilen einer Restaurantrechnung, wenn niemand mehr weiß, was er bestellt hat.
Schließlich kommt es in geteilten Setups schnell zu Situationen, in denen Teams um Ressourcen konkurrieren – mit langsamen Reaktionszeiten und Ausfällen als Folge.
Folgen Sie stattdessen dem Rat aus Anti-Pattern #2 und etablieren Sie eine "One Workload, One Project/Account"-Regel. Das schafft klare Verantwortlichkeiten, vereinfacht die Verwaltung und reduziert das Risiko ungewollter Eingriffe in fremde Ressourcen.
Anti-Pattern #5: Workloads im AWS-Management-Account betreiben
Hin und wieder begegnen wir Kunden, die sämtliche Ressourcen im Management-Account betreiben, weil sie ihr Unternehmen einst als Minimum Viable Product (MVP) in genau diesem Account gestartet haben – ohne lange darüber nachzudenken. Mit dem Wachstum des Unternehmens wurde dann einfach immer weiter im selben Account aufgebaut.
Der AWS-Management-Account sollte administrativen Funktionen vorbehalten bleiben. workloads dort zu betreiben, erhöht das Risiko unbeabsichtigter Fehlkonfigurationen und Sicherheitslücken.
Ein wichtiger Grund, Ressourcen in andere Accounts auszulagern: Service Control Policies (SCPs) einer AWS Organization können Nutzer oder Rollen im Management-Account nicht einschränken.
Wir empfehlen, den Management-Account und seine Nutzer/Rollen ausschließlich für Aufgaben zu verwenden, die nur dieser Account erledigen kann. Eine Ausnahme machen wir bei AWS CloudTrail: Aktivieren Sie CloudTrail und behalten Sie relevante Trails und Logs im Management-Account. Primär dient das der Sicherheit – Sie sehen, wer wann was in Ihrem AWS-Account verändert hat. Es lässt sich aber auch für Events nutzen, etwa um zu reagieren, wenn eine neue EC2-Instance gestartet wird.
Wie bereits erwähnt, sollten Sie workloads in separate AWS-Member-Accounts isolieren. Diese Trennung erhöht die Sicherheit, vereinfacht das Management und reduziert Risiken.
Fehlende Automatisierung in Sicherheitsrichtlinien
Anti-Pattern #6: Fehlende Automatisierung bei Sicherheitsrichtlinien
Sicherheitsrichtlinien manuell durchzusetzen ist fehleranfällig und zeitraubend – mögliche Sicherheitsvorfälle, Mehrausgaben und ineffiziente Ressourcennutzung sind die Folge.
Stellen Sie sich vor, Sie müssten Richtlinien fortlaufend manuell anwenden, prüfen und anpassen!
Stattdessen sollten Sie eine Sicherheits-Baseline automatisch etablieren. Im Idealfall werden auf jede neu in der Cloud bereitgestellte Ressource automatisch die passenden Sicherheitsrichtlinien angewandt. Automatisierung hilft nicht nur dabei, Sicherheitsrichtlinien über heterogene Umgebungen hinweg zu vereinheitlichen, sondern (vielleicht sogar wichtiger) auch bei der Bewertung und Behebung von Events. Stabile Systeme reagieren auf Events richtlinienbasiert ohne menschliches Eingreifen, sodass sich Teams auf Wertschöpfung konzentrieren können. Dienste wie AWS Config, Amazon EventBridge und Amazon GuardDuty sind hier eine enorme Hilfe.
Wie eingangs erwähnt: Vielleicht möchten Sie Ihren Teams die Nutzung bestimmter Instanzen (z. B. T2D) untersagen. Oder verhindern, dass Instanzen in Regionen gestartet werden, in denen Sie aktuell nicht aktiv sind (eine gängige Taktik bei Sicherheitsvorfällen rund um Krypto-Mining). Automatisierte Sicherheitsrichtlinien überwachen Ihre Cloud-Umgebung kontinuierlich und führen solche Prüfungen mit validierten, konsistenten Reaktionen durch.
Anti-Pattern #7: Richtlinien und Best Practices auf Organisationsebene vernachlässigen
Wie zuvor erwähnt, kann eine stabile Organisation Sicherheitsrichtlinien und Konfigurationen per Automatisierung konsolidieren und Ressourcen so effizienter nutzen. Voraussetzung ist eine Cloud-Governance-Strategie, die klar benennt, was die zentralen Treiber zur Absicherung von workloads und Daten in der Cloud sind, welche Teams die Verantwortung tragen und welche Tools eingesetzt werden. Fehlt auch nur ein minimales Grundgerüst dafür, öffnet sich die Organisation zwangsläufig regulatorischen Risiken, ineffizienter Ressourcennutzung und neuen Bedrohungsvektoren.
Cloud Governance basiert nicht ausschließlich auf Sicherheitsaspekten. Auch die Erfahrungen der Teams im operativen Cloud-Betrieb können zu einer effizienteren Ressourcennutzung und zur Entwicklung architektonischer Best Practices führen, die teamübergreifend geteilt werden sollten. Reifere Organisationen definieren und verfeinern kontinuierlich Referenzarchitekturen, die zugelassene Ressourcentypen (etwa erlaubte Services oder Maschinentypen) und Sicherheitsrichtlinien umfassen. Das beschleunigt die Velocity der Produktteams enorm, da sie nicht für jedes neue Produkt-Deployment eine Architektur von Grund auf neu entwickeln müssen.
Wer diese typischen Stolperfallen rund um die Landing Zone erkennt und angeht, ist bestens aufgestellt, um Cloud-Ausgaben besser zu verstehen, Kosten zu optimieren und die Sicherheitslage zu stärken. Viele dieser Schritte sind besonders entscheidend für die Kostenzuordnung.
Sie möchten tiefer in die Cloud-Kostenzuordnung eintauchen? Sehen Sie sich unser On-Demand-Webinar an – rund um FinOps, Kostenzuordnung und wie Sie diese mit DoiT Cloud Intelligence™ umsetzen.