I 7 anti-pattern più diffusi nelle aziende quando si tratta di organizzare le risorse e impostare controlli e policy.

La landing zone cloud è la base della Sua infrastruttura cloud. Il modo in cui organizza le risorse e imposta controlli e policy farà la differenza tra un percorso cloud lineare e uno pieno di ostacoli.
Una gerarchia delle risorse ben strutturata, ad esempio, Le semplifica la vita quando deve allocare i costi cloud e configurare il controllo degli accessi. Una gerarchia mal impostata, al contrario, La porterà a chiedersi quale team sia responsabile di quale costo, aumentando il rischio che qualcuno acceda a dati che non dovrebbe vedere.
Ogni cloud provider pubblica le proprie best practice per impostare con successo una landing zone, eppure continuiamo a osservare alcuni anti-pattern ricorrenti.
Forti dell'esperienza maturata supportando oltre 3.000 aziende digital native nelle loro sfide cloud, abbiamo individuato i 7 anti-pattern di landing zone più frequenti, indicando cosa dovrebbe fare invece.
Entriamo nel dettaglio.
Anti-pattern #1: non sfruttare Organizational Unit (OU) e/o Folder
Non definire una struttura adeguata di Folder (Google Cloud) o di Organizational Unit (AWS) può portare a una proliferazione incontrollata delle risorse e a difficoltà nella gestione di accessi e permessi.
L'ideale è organizzare le risorse cloud in modo che rispecchino la reale struttura aziendale, e Folder e OU sono lo strumento perfetto per farlo.
Servono a separare e classificare le risorse dei diversi reparti o team all'interno dell'organizzazione. Al loro interno trovano spazio i progetti (Google Cloud) o gli account (AWS), con ciascuno dei Suoi workloads associato a un singolo progetto/account (ne riparleremo nel prossimo anti-pattern).
Folder e OU sono utilissime anche per definire guardrail tramite policy e permessi. Ad esempio, può impedire agli utenti di un determinato reparto di accedere alle region che non utilizza. Oppure bloccare i team di sviluppo nell'uso di istanze specifiche, come le T2D di Google Cloud o le X1 di AWS.
Folder e OU possono essere annidate, ma le sconsigliamo di complicare troppo la struttura se non è strettamente necessario. Più livelli aggiunge alla gerarchia delle risorse cloud, più complessa diventa la gestione.

Anti-pattern #2: concentrare tutte le risorse in un solo account AWS o progetto Google Cloud
Raggruppare tutti i workloads in un unico account o progetto rende difficile gestire i costi, monitorare l'utilizzo e applicare i controlli di sicurezza.
Immagini, ad esempio, di avere risorse di due applicazioni diverse all'interno dello stesso progetto Google Cloud. Senza isolare le risorse in progetti/account distinti, finisce per dipendere in modo eccessivo da una tagging policy impeccabile (ne parliamo nel prossimo anti-pattern). Tracciare le spese e attribuire i costi a team, applicazioni o ambienti specifici diventa contorto, ostacolando la capacità di individuare opportunità di risparmio e di allocare le risorse in modo efficiente. E la complessità non potrà che aumentare con la crescita dell'azienda.
Inoltre, quando tutte le risorse convivono in un unico account o progetto, qualsiasi violazione di sicurezza o errore di configurazione può potenzialmente compromettere tutti i servizi e i workloads (ragionare in ottica di riduzione del blast-radius aiuta a contenere l'impatto degli eventi negativi).
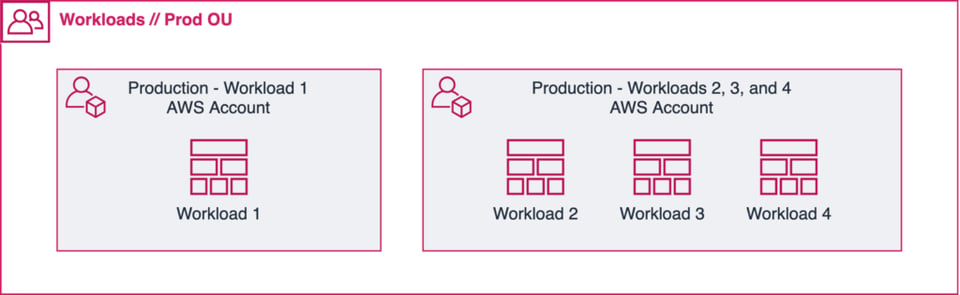
Quando possibile, opti per un singolo workload in un singolo account/progetto. Tuttavia, se ha workloads di piccole dimensioni e affini per ambito, può valutare di raccoglierli nello stesso account (vedi illustrazione sopra).
Infine, anche se un numero ridotto di account significa meno carico amministrativo, separando i workloads beneficia di funzionalità di sicurezza operativa native, come strutture di permessi e rate-limiting (chi ha provato a inserire più di 100 bucket in un account conosce bene questi limiti).
Anti-pattern #3: sottoutilizzare tag/label (o ignorarli del tutto)
I tag (AWS) e le label (Google Cloud) servono a fornire informazioni di dettaglio sulle Sue risorse cloud.
Tra i casi d'uso troviamo:
- Arricchimento del billing (es. associare un cost center a una risorsa)
- Classificazione di ambiente/applicazione (es. specificare i livelli di sicurezza dei dati)
- Automazione (es. definire le pianificazioni di reboot)
…ma concentriamoci sul primo punto e sul perché i tag siano così importanti.
Tag e label hanno un ruolo cruciale nell'allocazione e nel tracciamento dei costi. E una buona allocazione dei costi è il presupposto per gestire al meglio la spesa cloud.
Senza un tagging adeguato diventa difficile associare le spese a progetti, reparti o team specifici. Rinunciare a tag e label significa rinunciare anche a insight dettagliati, all'analisi dei trend di utilizzo e a report significativi su cui basare le decisioni. Questa mancanza di granularità si traduce in inefficienze di costo, sovraspesa e difficoltà nell'individuare aree di ottimizzazione.
Con il tagging la tentazione è quella di definire una struttura molto dettagliata, con numerosi tag da applicare a ogni risorsa. Per quanto sia un approccio ammirevole, in fase iniziale è poco realistico. Consigliamo di partire in piccolo, con soli 2-3 tag, ma di applicarli con il massimo rigore.
I tre tag che riteniamo assolutamente irrinunciabili sono:
- Nome dell'applicazione
- Team
- Stage/Ambiente
Poiché i tag sono case sensitive, consigliamo di adottare uno standard di denominazione, come lo snake case, per evitare duplicazioni. I nomi possono naturalmente essere adattati alla cultura aziendale, purché restino descrittivi e chiari. In questo caso, "app_name" indica il nome di un microservizio o di un workload, mentre "env" rappresenta una fase di sviluppo, come "development", "testing" o "production".
I valori di entrambi i campi dovrebbero idealmente attingere a un elenco relativamente standard: anche qui, se gli utenti taggano le risorse con varianti come "Website - Frontend", l'analisi dei dati ne risente.
Un esempio concreto in cui i tag aiutano a capire meglio i consumi cloud è quello di un account di "risorse condivise" all'interno di un'organizzazione, in cui sono raccolte tutte le risorse di database (utilizzate da più team). A ciascun database può assegnare un tag o una label che indica quale team debba farsi carico dei costi di utilizzo.
Approfondiamo l'argomento nel nostro articolo sulle Resource Labeling Best Practices.
Anti-pattern #4: condividere progetti Google Cloud o account AWS tra team diversi
Per ragioni analoghe a quelle dell'anti-pattern #2, condividere progetti/account tra team ostacola la governance delle risorse e crea potenziali conflitti su accessi, permessi e costi.
Immagini di stipare team diversi nella stessa stanza. Nessuno ha il proprio spazio, niente privacy. I progetti/account condivisi nel cloud funzionano un po' così, con l'aggravante che tutti hanno le chiavi delle stanze altrui: è quindi molto facile finire dove non si dovrebbe. Team diversi possono dover seguire regole diverse, ed è difficile mantenere l'ordine quando le risorse di tutti sono mescolate. In più, in caso di violazione o incidente di sicurezza, il "blast radius" si amplia non appena più team condividono lo stesso account.
Quando le risorse sono raggruppate, anche i costi si confondono e l'allocazione diventa difficile, a meno di un tagging perfetto. Un po' come dividere il conto del ristorante tra amici quando nessuno ricorda cosa ha ordinato.
Infine, in una configurazione condivisa capita spesso che i team finiscano per contendersi le risorse, con conseguenti rallentamenti e downtime.
Segua piuttosto il consiglio dell'anti-pattern #2 e adotti la regola "un workload, un progetto/account". Garantisce ownership chiara, gestione più semplice e riduce il rischio di interferenze involontarie con le risorse altrui.
Anti-pattern #5: eseguire workloads nell'AWS management account
Capita di incontrare clienti che hanno tutte le risorse nel management account perché hanno avviato l'azienda come Minimum Viable Product (MVP) proprio in quell'account, magari senza pensarci troppo. Poi, con la crescita e l'evoluzione dell'azienda, hanno semplicemente continuato a costruirci sopra.
L'AWS management account dovrebbe essere riservato alle funzioni amministrative; ospitarvi workloads aumenta il rischio di errori di configurazione accidentali e l'esposizione a vulnerabilità di sicurezza.
Un motivo importante per tenere le risorse in altri account è che le service control policy (SCP) di un'AWS Organization non hanno effetto sugli utenti o sui ruoli del management account.
Consigliamo di usare il management account, e i relativi utenti e ruoli, esclusivamente per le attività che solo quell'account può svolgere. L'unica eccezione: raccomandiamo di abilitare AWS CloudTrail e di mantenere i relativi trail e log nel management account. Lo scopo principale è la sicurezza: sapere chi ha modificato cosa e quando nel Suo account AWS. Ma è utile anche per gli eventi, ad esempio per reagire all'avvio di una nuova istanza EC2.
Come anticipato, è bene isolare i workloads in account member AWS separati. Questa separazione rafforza la sicurezza, semplifica la gestione e riduce i rischi.
Mancanza di automazione nelle policy di sicurezza
Anti-pattern #6: mancanza di automazione nelle policy di sicurezza
L'applicazione manuale delle policy di sicurezza è soggetta a errori e dispendiosa in termini di tempo, con il rischio concreto di violazioni, sovraspesa e utilizzo inefficiente delle risorse.
Immagini di applicare, validare e correggere policy a mano, di continuo!
L'obiettivo dovrebbe essere stabilire automaticamente una baseline di sicurezza. In un mondo ideale, ogni nuova risorsa configurata nel cloud riceve in automatico le policy di sicurezza pertinenti. L'automazione non riguarda solo il consolidamento delle policy in ambienti eterogenei, ma anche (forse ancora di più) la valutazione e la remediation degli eventi. I sistemi stabili sono in grado di gestire la remediation degli eventi in base alle policy senza intervento umano, lasciando ai team il tempo di concentrarsi sulla creazione di valore. Servizi come AWS Config, Amazon EventBridge e Amazon GuardDuty sono di grande aiuto nel costruire questi workflow.
Come accennato in precedenza, magari non vuole che i Suoi team utilizzino determinate istanze (es. T2D). Oppure non vuole che qualcuno avvii istanze in una region in cui non opera attualmente (una tattica ricorrente nelle violazioni legate al crypto mining). Le policy di sicurezza automatizzate possono monitorare costantemente l'ambiente cloud ed eseguire questo tipo di controlli con risposte validate e coerenti.
Anti-pattern #7: trascurare policy e best practice a livello organizzativo
Come abbiamo visto, un'organizzazione matura sa consolidare policy e configurazioni di sicurezza tramite l'automazione, per usare le risorse in modo più efficiente. Tutto questo richiede una strategia di cloud governance ben definita, che chiarisca i driver principali per la protezione di workloads e dati nel cloud, i team responsabili e gli strumenti da utilizzare. Senza nemmeno uno scheletro minimo di strategia, l'organizzazione si espone inevitabilmente a rischi normativi, a un uso inefficiente delle risorse e a vettori di minaccia.
La cloud governance non si esaurisce nelle pratiche di sicurezza. Le lezioni apprese dai team che operano nel cloud possono portare anche a un utilizzo più efficiente delle risorse e alla creazione di best practice architetturali da condividere tra i diversi team che gestiscono risorse cloud. Le organizzazioni più mature definiscono e affinano costantemente reference architecture che includono i tipi di risorse da utilizzare (si pensi ai servizi o ai machine type ammessi) e le policy di sicurezza: in questo modo aumenta la velocity dei team di prodotto, che non devono riprogettare un'architettura da zero per ogni nuovo prodotto rilasciato.
Riconoscendo e affrontando queste insidie ricorrenti delle landing zone, avrà tutti gli strumenti per comprendere meglio la spesa cloud, ottimizzare i costi e rafforzare la postura di sicurezza. Molti di questi passaggi sono particolarmente determinanti per l'allocazione dei costi.
Vuole approfondire la cost allocation in cloud? Guardi il nostro webinar on-demand dedicato a FinOps, cost allocation e a come gestirla con DoiT Cloud Intelligence™.