AWS MSK(Managed Service Kafka)は、リアルタイムストリーミングデータパイプラインを構築するためのオープンソースプラットフォームであるApache Kafkaを利用し、ストリーミングデータを処理するアプリケーションを手軽に構築・運用できるフルマネージドサービスです。
AWS MSK Connectorは、Kafkaクラスターとデータベース、検索インデックス、ファイルシステムなどの外部システムを連携させるオープンソースフレームワーク「Kafka Connect」向けに設計されたフルマネージド型コネクタを通じて、Kafkaクラスターとの間でデータを簡単にストリーミングできるAWS MSKの機能です。
これまで当社では、障害が発生しやすいリージョンである米国北部バージニア(us-east-1)でMSKクラスターを運用中に本番障害に直面したお客様を数多く支援してきました。その中でよく寄せられるのが、「障害発生時にMSKをどう活用するのが最適か」という質問です。一般的に提案される対策は、次の2つです。
1. ホットスタンバイのDR(Disaster Recovery)用MSKクラスターを、DRリージョンで常時稼働させておく。
2. 必要になった時点でDRリージョンに新しいクラスターを起動する(約30分のダウンタイムが発生する)。
1つ目の対策はコストが非常に高く、採用する場合はインフラ費用としてあらかじめ予算化しておく必要があります。MSKクラスターのダウンタイムによる業務損失が、別リージョンで24時間365日稼働する重複インフラの高コストを上回る場合に限って推奨される選択肢です。
2つ目はコスト面で大きく有利ですが、AWSが新しいMSKクラスターをプロビジョニングするのに時間がかかるため、約30分のダウンタイムを伴うのが一般的です。
いずれの戦略を選んだ場合でも、クラスターが利用可能になった段階で、DRクラスターまたは新規に起動したクラスター用に最新のKafkaトピックデータが必要になります。ここで活躍するのがAWS MSK Connectorです。基本的な進め方は、KafkaトピックデータをS3バケットへバックアップし、それを代替クラスターへ復元するという流れです。本記事で解説する詳細な手順をまとめた図を以下に示します。なお、ここではConfluent Amazon S3 Sink Connectorを利用してMSKトピックデータをS3バケットに転送します。
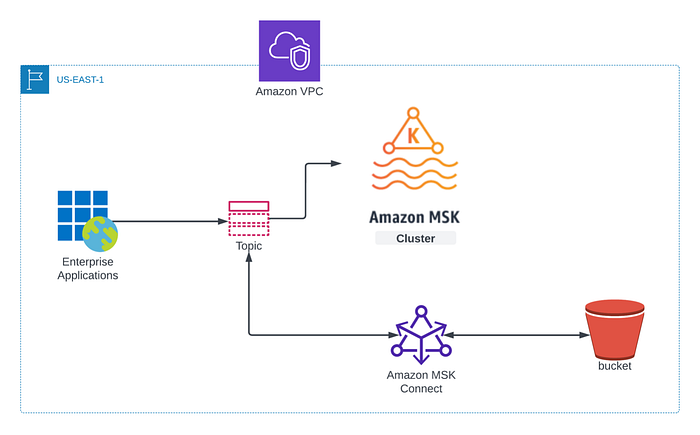
**前提条件**
1. S3バケット2つ(1つは現行のMSKクラスターと同じリージョン、もう1つはDRリージョン)
2. S3 VPCゲートウェイエンドポイント
3. 2つのS3バケット間のレプリケーション
4. Confluent Amazon S3 Sink ConnectorのZipファイル
5. AWS MSK Connectorのログを監視するためのAWS CloudWatchロググループ
6. 後述するS3ポリシーを付与したKafka Connector用ロール
ステップ1: S3バケットの作成
本番リージョンとDRリージョンに、それぞれS3バケットを1つずつ作成します。本記事では本番リージョンとして米国北部バージニア(us-east-1)、DRリージョンとして米国オレゴン(us-west-2)を使用します。

**ステップ2: MSKクラスターの起動**
新しいMSKクラスターを起動します(すでに稼働中のMSKクラスターがある場合は、本ステップをスキップしても構いません)。
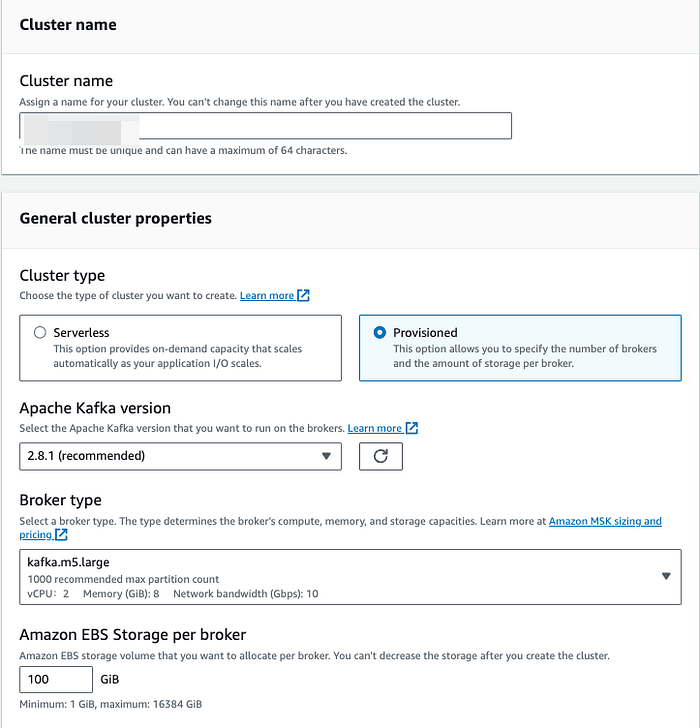
セキュリティ設定では、赤くハイライトされた以下の2つのチェックボックスのみを選択してください。この2つを選んでいる理由は、暗号化を有効にする場合にプロデューサー側とコンシューマー側で暗号化証明書を作成する必要があり、その内容は本記事の対象外であるためです。
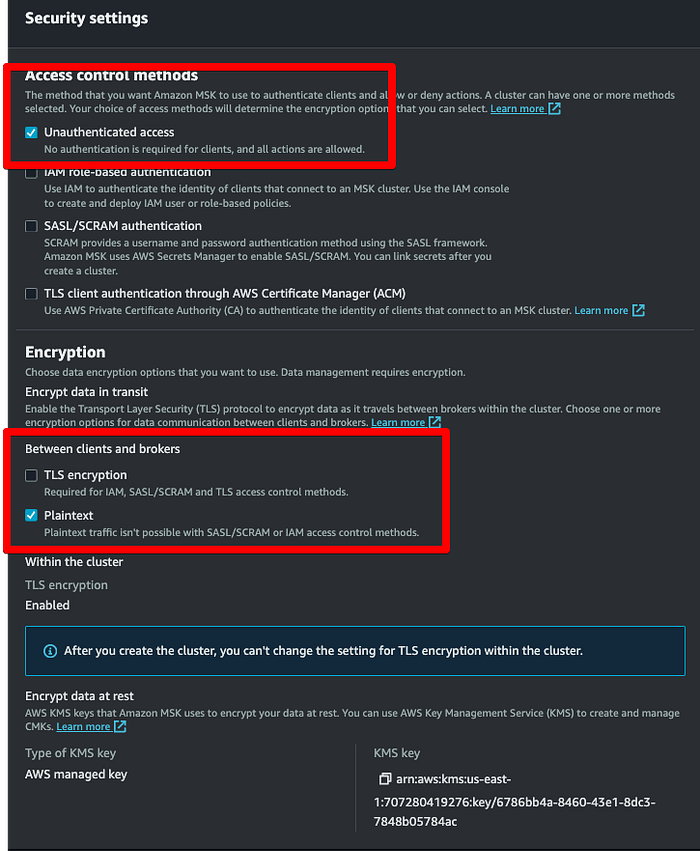
**ステップ3: 宛先バケットへ書き込み可能なMSK Connector用IAMロールを作成**
続いて、MSKがトピックデータを宛先バケットに書き込むために使うロールを用意します。IAMコンソールで「Roles」>「Create Roles」をクリックし、以下のオプションを選択します。本記事では「msk-blog-role」という名前でロールを作成しました。
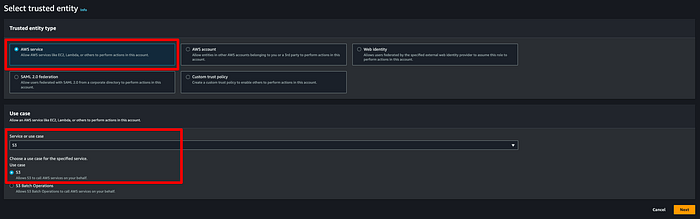
本番クラスターで使用するS3バケットへアクセスできるように、MSK IAMロール用のカスタムポリシーを作成します。IAMロールにアタッチするIAMポリシーのJSONは以下のとおりです。本記事ではポリシー名を「msk-blog-s3-policy」としました。
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListAllMyBuckets"\
],\
"Resource": "arn:aws:s3:::*"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListBucket",\
"s3:GetBucketLocation",\
"s3:DeleteObject"\
],\
"Resource": "arn:aws:s3:::<name-of-your-bucket>"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:PutObject",\
"s3:GetObject",\
"s3:AbortMultipartUpload",\
"s3:ListMultipartUploadParts",\
"s3:ListBucketMultipartUploads"\
],\
"Resource": "*"\
}\
]
}
ポリシーを作成したら、ロールにアタッチします。
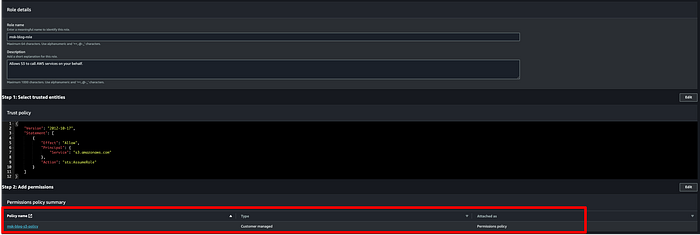
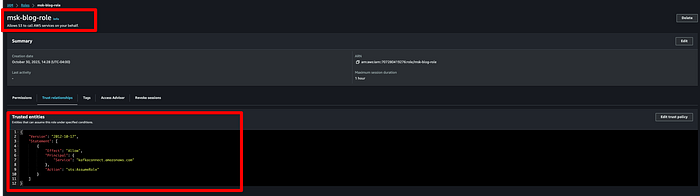
アタッチが完了したらロールを保存し、「Trust relationships」をクリックして以下のJSONに置き換えます。
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "kafkaconnect.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
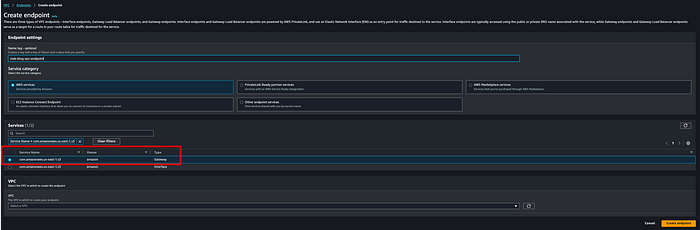
**ステップ4: MSKクラスターのVPCからAmazon S3へのVPCエンドポイントを作成**
MSK Connectorがインターネットを経由せずに宛先S3バケットへデータを書き込むには、VPCエンドポイントが必要です。本記事では、ゲートウェイエンドポイントmsk-blog-vpc-endpointを作成しました。
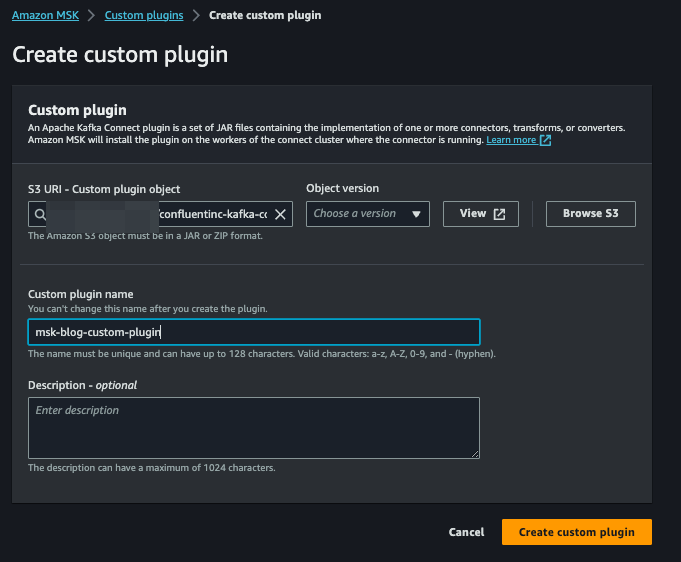
**ステップ5: Confluent S3 Sink ConnectorでAWS MSK Connector用カスタムプラグインを作成**
Confluent S3 Sink Connector [LINK] をダウンロードし、S3バケットにアップロードします。次にAWS MSKコンソールへ移動し、左側の「Custom plugins」を選択して「Create custom plugin」をクリックします。Confluent S3 Sink ConnectorのZipファイルをアップロードしたS3バケットを参照してファイルを選び、プラグイン名を入力したうえで「Create custom plugin」をクリックします。
**ステップ6: テスト用クライアントマシンとApache Kafkaトピックの作成**
Amazon Linux 2 AMIのEC2インスタンスを起動します。次に、新規作成したEC2インスタンスからMSKクラスターへデータを送信できるよう、MSKクラスターに紐づいたセキュリティグループを、新規EC2インスタンスのインバウンドルールに「All Traffic」で追加します(下図参照)。

Kafkaトピックを作成するには、EC2インスタンス上で以下のコマンドを実行します。
#Javaのインストール
sudo yum install java-1.8.0
#Apache Kafkaのダウンロード
wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
#ファイルの展開
tar -xzf kafka_2.12-2.2.1.tgz
続いて、Apache ZooKeeper接続用のクライアント情報を取得します。MSKクラスターでの確認場所は下図のとおりです。
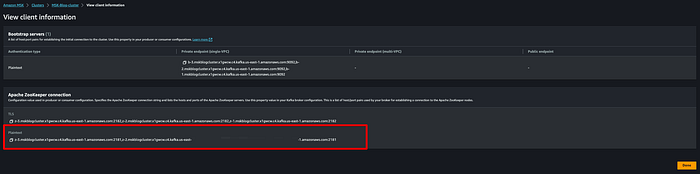
取得したプレーンテキストの接続文字列を、以下のコマンド実行時に使用します。
#コマンドのサンプル
<path-to-your-kafka-installation>/bin/kafka-topics.sh --create --bootstrap-server bootstrapServerString --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
#実際のコマンドは以下のような形になります。
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-topics.sh --create --bootstrap-server z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
**ステップ7: MSK Connectorの作成**
先ほど作成したカスタムConfluentプラグインを使ってMSK Connectorを作成します。
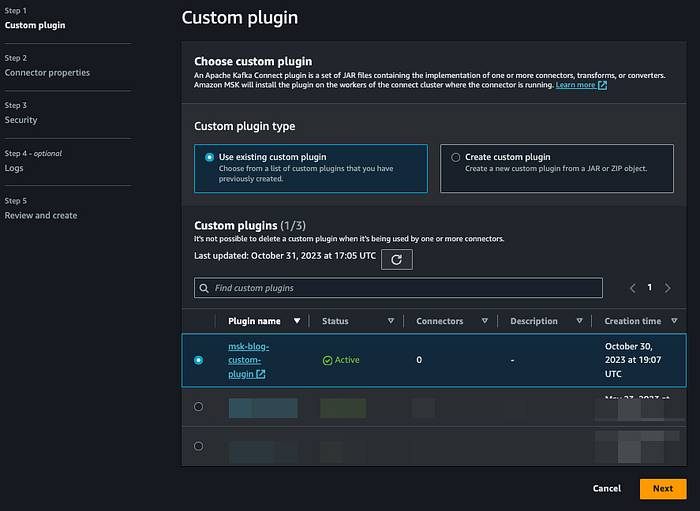
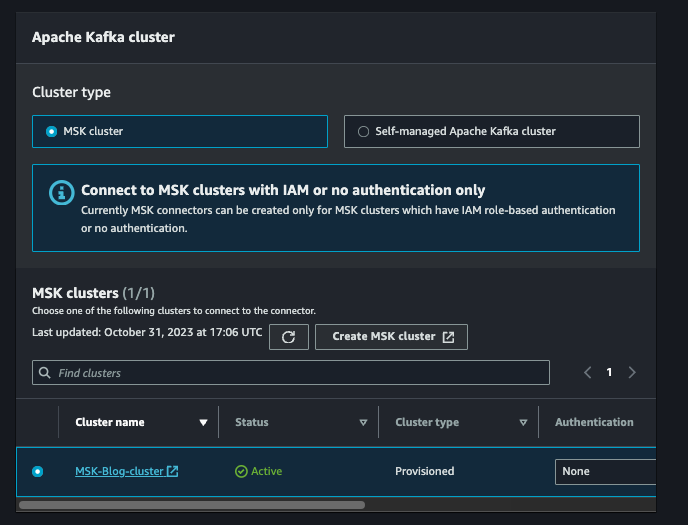
「Next」をクリックし、命名規則に沿ってコネクタ名を入力します。続いてMSKクラスターを選択します。
コネクタ設定フィールドに、以下のコードスニペットを追加します。S3バケット名を実際の宛先バケット名に置き換えるのを忘れないでください。
connector.class=io.confluent.connect.s3.S3SinkConnector
s3.region=us-east-1
format.class=io.confluent.connect.s3.format.json.JsonFormat
flush.size=1
schema.compatibility=NONE
tasks.max=2
topics.regex=name.(.*)
partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
storage.class=io.confluent.connect.s3.storage.S3Storage
s3.bucket.name=<my-destination-bucket>
topics.dir=tutorial
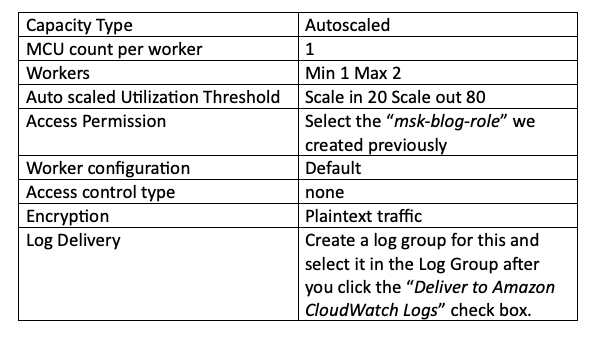
その他に必要な設定は以下のとおりです。本記事はPOCのためcapacityとworkersはデフォルトのままとしていますが、実運用ではMSKクラスターが扱うトピック数に応じてcapacityを調整してください。
最後に「Create connector」をクリックします。上記のとおり設定が正しければ、コネクタのステータス欄に緑色の「Running」が表示されます。「Failed」と表示された場合は、上記の手順のいずれかで抜けや誤りがある可能性が高いです。原因を特定するには、本コネクタ用に作成したCloudWatchロググループの作成ログを確認するとよいでしょう。

Connectorの連携が正しく動作しているかを確認するため、プロデューサー用EC2サーバーでテストメッセージを作成してみましょう。
プロデューサー用EC2サーバーで、以下のコマンドを実行します。
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-console-producer.sh --broker-list z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
EC2のコマンドラインで任意のメッセージを入力します。1〜2分待ってから宛先バケットを開き、メッセージがバケット内にバックアップされているかを確認します。
これで、トピックデータが先ほど作成した宛先バケットへバックアップされる状態になりました。ただし、AWSリージョン障害が発生するとそのデータにはアクセスできなくなるため、本番側の宛先バケット(例: us-east-1)からDRリージョン(us-west-2)のバケットへデータレプリケーションを設定しておく必要があります。設定方法は、こちらのAWS公式ドキュメントをご参照ください。