AWS MSK (Managed Service Kafka) est un service entièrement géré qui facilite la création et l'exécution d'applications de traitement de données en streaming reposant sur Apache Kafka, une plateforme open source dédiée aux pipelines de données en temps réel.
AWS MSK Connector est une fonctionnalité d'AWS MSK qui simplifie la circulation des données entrantes et sortantes de vos clusters Kafka, grâce à des connecteurs entièrement gérés et conçus pour Kafka Connect — un framework open source permettant de relier les clusters Kafka à des systèmes externes tels que des bases de données, des index de recherche ou des systèmes de fichiers.
Nous avons accompagné plusieurs clients confrontés à des interruptions de production lors de l'exploitation de clusters MSK dans la région US Northern Virginia (us-east-1), particulièrement sujette aux pannes. Au fil de ces échanges, une question revient souvent : comment tirer le meilleur parti de MSK durant ces incidents ? Deux solutions sont généralement proposées :
1. Maintenir en permanence un cluster MSK de Disaster Recovery (DR) actif dans une région de secours.
2. Lancer un nouveau cluster en cas de besoin dans une région de DR, malgré les ~30 minutes d'indisponibilité que cela implique.
La première solution est très coûteuse et doit être intégrée au budget de l'infrastructure si elle est retenue. Elle n'est recommandée que si la perte opérationnelle liée à l'indisponibilité du cluster MSK dépasse le coût élevé d'une infrastructure dupliquée et active 24/7 dans une autre région.
La deuxième option, nettement plus économique, entraîne généralement une trentaine de minutes d'indisponibilité, le temps qu'AWS provisionne un nouveau cluster MSK.
Quelle que soit la stratégie retenue, une fois le cluster disponible, il faudra disposer des données les plus récentes des topics Kafka pour le cluster de DR ou le cluster nouvellement lancé. C'est précisément là qu'AWS MSK Connector entre en jeu. L'approche générale consiste à sauvegarder les données des topics Kafka dans un bucket S3, puis à les restaurer sur le cluster de remplacement. Le schéma ci-dessous résume la démarche détaillée que je présente dans cet article : nous nous appuierons sur le Confluent Amazon S3 Sink Connector pour transférer les données des topics MSK vers un bucket S3.
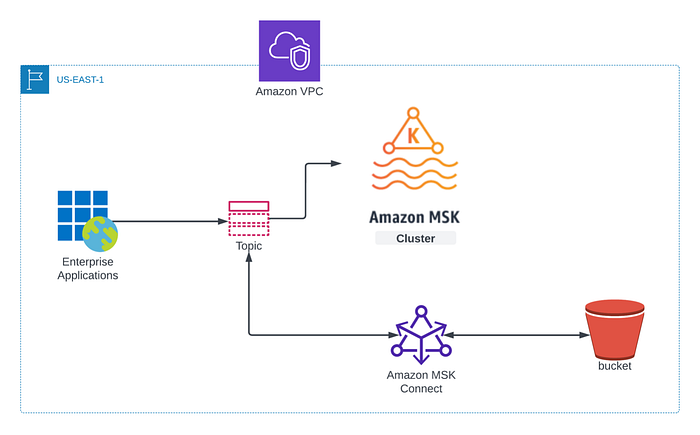
**Prérequis :**
1. Deux buckets S3 : l'un dans la même région que le cluster MSK actuel, l'autre dans la région de DR
2. Un VPC Gateway Endpoint S3
3. La réplication entre les deux buckets S3
4. Le fichier zip du Confluent Amazon S3 Sink Connector
5. Un Log Group AWS CloudWatch pour suivre les logs d'AWS MSK Connector
6. Un rôle Kafka Connector associé à la politique S3 décrite ci-dessous
Étape 1 : créer les buckets S3
Créez deux buckets S3 distincts : l'un dans la région de production, l'autre dans la région de DR. J'utilise ici US N. Virginia (us-east-1) comme région de production et US Oregon (us-west-2) comme région de DR.

**Étape 2 : lancer le cluster MSK**
Lancez un nouveau cluster MSK (dans bien des cas, vous disposez déjà d'un cluster MSK en fonctionnement et pouvez ignorer cette étape).
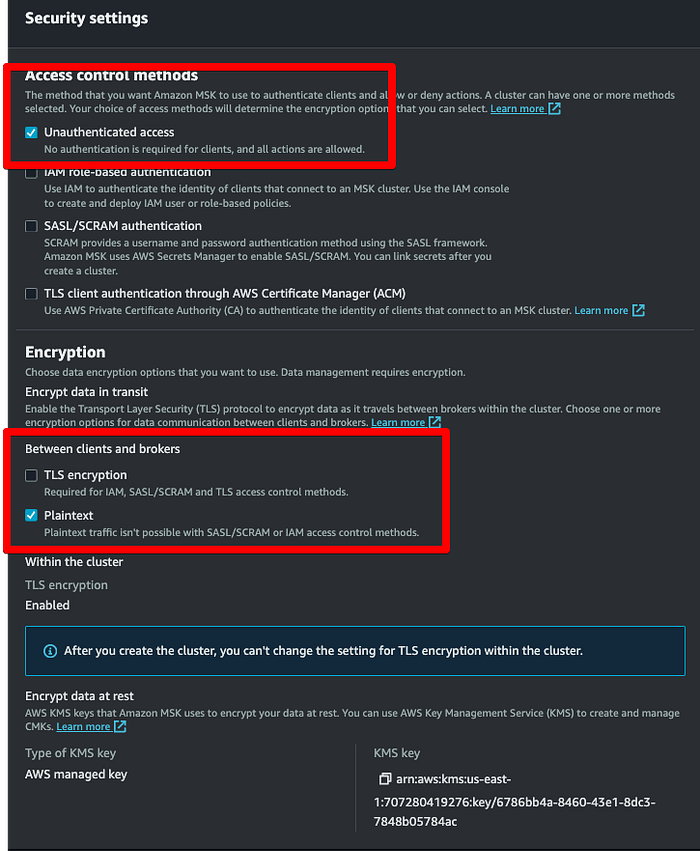
Dans les paramètres de sécurité, assurez-vous que seules les deux cases surlignées en rouge sont cochées. Ces deux options sont retenues car activer le chiffrement imposerait de créer des certificats au niveau du producteur et du consommateur, ce qui dépasse le cadre de cet article.
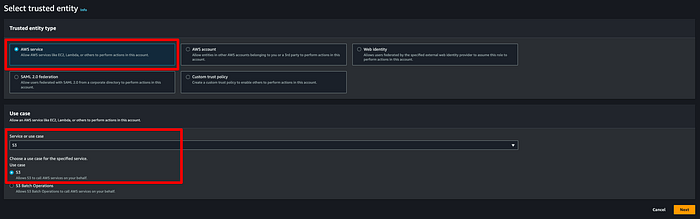
**Étape 3 : créer un rôle IAM pour MSK Connector autorisé à écrire dans le bucket de destination**
Il nous faut maintenant un rôle que MSK pourra utiliser pour écrire les données des topics dans notre bucket de destination. Rendez-vous dans la console IAM, cliquez sur Roles > Create Roles et sélectionnez les options ci-dessous. J'ai créé un rôle nommé msk-blog-role.
Créez une politique personnalisée pour votre rôle IAM MSK afin de lui donner accès au bucket S3 destiné au cluster de production. Voici le JSON de la politique IAM à attacher au rôle. J'ai nommé ma politique msk-blog-s3-policy :
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListAllMyBuckets"\
],\
"Resource": "arn:aws:s3:::*"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListBucket",\
"s3:GetBucketLocation",\
"s3:DeleteObject"\
],\
"Resource": "arn:aws:s3:::<name-of-your-bucket>"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:PutObject",\
"s3:GetObject",\
"s3:AbortMultipartUpload",\
"s3:ListMultipartUploadParts",\
"s3:ListBucketMultipartUploads"\
],\
"Resource": "*"\
}\
]
}
Une fois la politique créée, attachez-la à votre rôle :
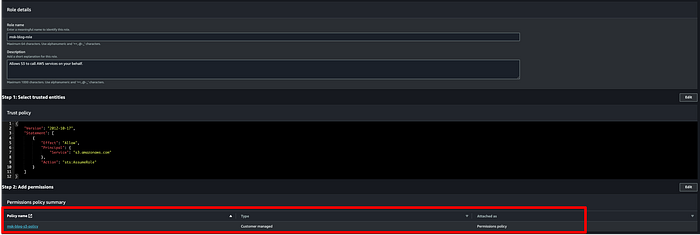
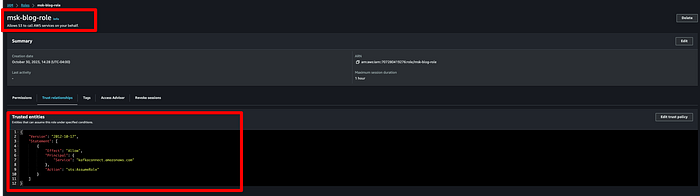
Une fois la politique attachée, enregistrez le rôle, cliquez sur Trust relationships et remplacez son contenu par le JSON ci-dessous :
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "kafkaconnect.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
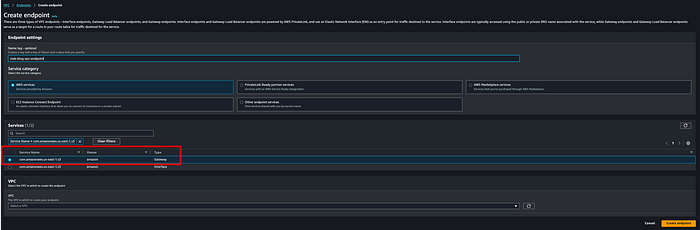
**Étape 4 : créer un VPC endpoint Amazon entre le VPC du cluster MSK et Amazon S3**
Un VPC endpoint est nécessaire pour que MSK Connector puisse écrire dans le bucket S3 de destination sans passer par l'internet public. J'ai créé le gateway endpoint msk-blog-vpc-endpoint :
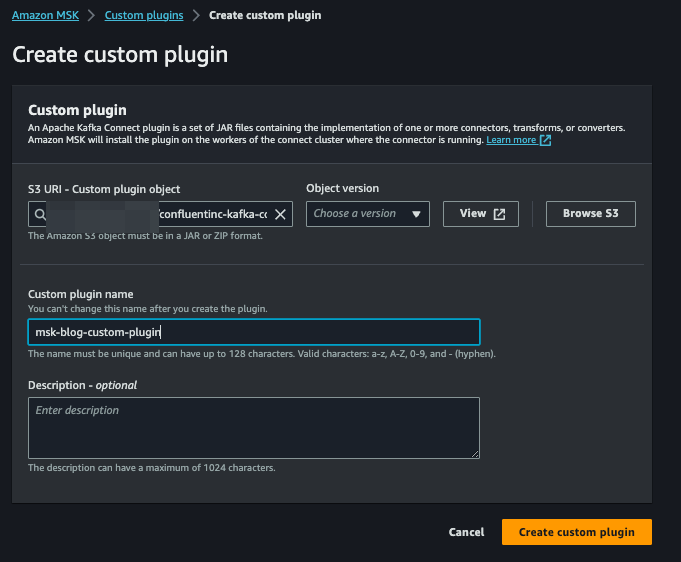
**Étape 5 : créer un plugin personnalisé pour AWS MSK Connector à l'aide du Confluent S3 Sink Connector**
Téléchargez le Confluent S3 Sink Connector [LIEN] et téléversez-le dans un bucket S3. Rendez-vous ensuite sur la console AWS MSK, cliquez sur Custom plugins dans le menu de gauche, puis sur Create custom plugin. Sélectionnez le fichier zip en parcourant le bucket S3 où vous l'avez téléversé, nommez le plugin et cliquez sur Create custom plugin :
**Étape 6 : créer une machine cliente et un topic Apache Kafka pour les tests**
Lancez une instance EC2 sous Amazon Linux 2 AMI. Autorisez ensuite cette nouvelle instance EC2 à envoyer des données au cluster MSK en ajoutant le security group associé au cluster MSK aux règles entrantes de la nouvelle instance EC2 pour All Traffic, comme indiqué ci-dessous :

Pour créer un topic Kafka, exécutez la commande suivante sur l'instance EC2 :
#Installer Java
sudo yum install java-1.8.0
#Télécharger Apache Kafka
wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
#Décompresser le fichier
tar -xzf kafka_2.12-2.2.1.tgz
Récupérez ensuite les informations client pour la connexion à Apache ZooKeeper. Voici où les trouver pour votre cluster MSK.
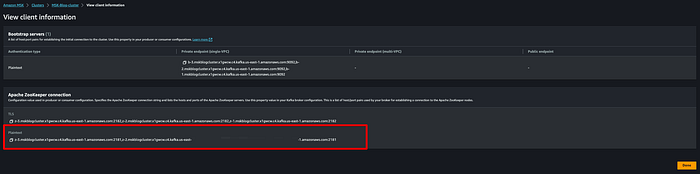
Utilisez cette chaîne de connexion en clair pour exécuter la commande suivante :
#Exemple de commande
<path-to-your-kafka-installation>/bin/kafka-topics.sh --create --bootstrap-server bootstrapServerString --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
#La commande réelle ressemblera à ceci.
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-topics.sh --create --bootstrap-server z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
**Étape 7 : créer le MSK Connector**
Créez un MSK Connector à partir du plugin Confluent personnalisé créé précédemment :
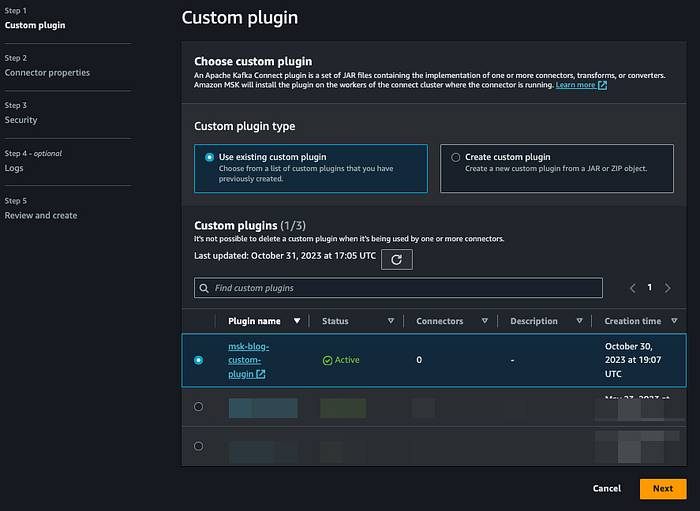
Cliquez sur Suivant, puis nommez le connecteur selon votre convention. Sélectionnez votre cluster MSK.
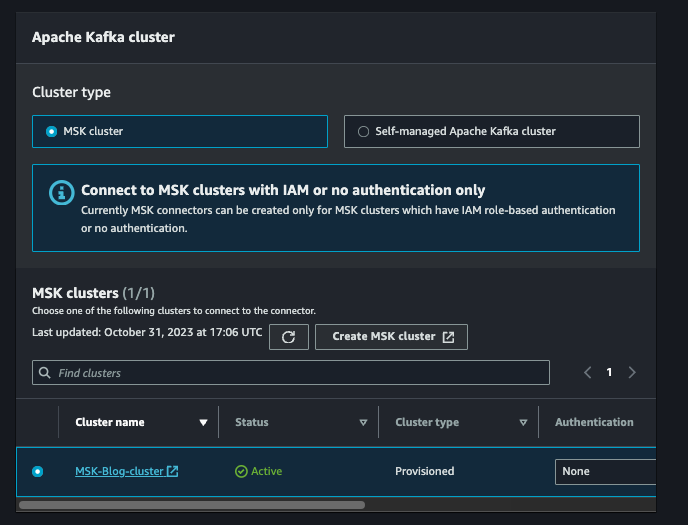
Dans le champ de configuration du connecteur, ajoutez l'extrait de code ci-dessous. N'oubliez pas de remplacer le bucket S3 par le nom réel de votre bucket de destination.
connector.class=io.confluent.connect.s3.S3SinkConnector
s3.region=us-east-1
format.class=io.confluent.connect.s3.format.json.JsonFormat
flush.size=1
schema.compatibility=NONE
tasks.max=2
topics.regex=name.(.*)
partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
storage.class=io.confluent.connect.s3.storage.S3Storage
s3.bucket.name=<my-destination-bucket>
topics.dir=tutorial
Les autres réglages nécessaires sont indiqués ci-dessous. Je conserve les valeurs par défaut pour la capacité et les workers, car il s'agit d'un POC ; à vous d'ajuster la capacité en fonction du nombre de topics gérés par votre cluster MSK.
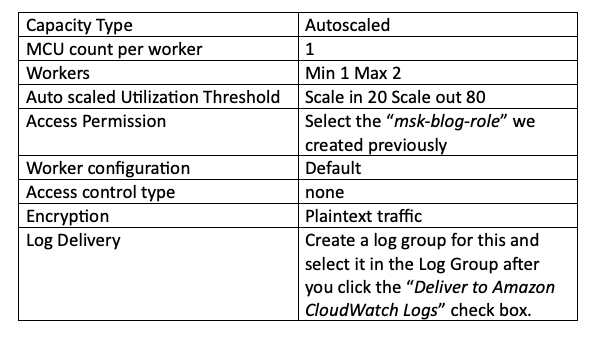
Enfin, cliquez sur Create connector. Si tous vos paramètres sont correctement définis, le statut de votre connecteur affichera Running en vert. S'il indique Failed, vous avez probablement omis une étape ou commis une erreur dans les étapes précédentes. Vous pouvez consulter les logs de création dans le Log Group créé pour ce connecteur dans CloudWatch Logs afin d'identifier l'origine du problème :

Pour vérifier le bon fonctionnement de l'intégration du connecteur, créons des messages de test sur le serveur EC2 producteur.
Exécutez la commande ci-dessous sur le serveur EC2 producteur :
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-console-producer.sh --broker-list z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
Saisissez n'importe quel message dans la ligne de commande de l'EC2. Patientez une à deux minutes, puis vérifiez le bucket de destination pour confirmer que le message y a bien été sauvegardé :
Les données de votre topic sont désormais sauvegardées dans le bucket de destination que nous avons créé. Toutefois, en cas de panne d'une région AWS, ces données ne seront pas accessibles. Vous devez donc mettre en place une réplication des données depuis le bucket de production de destination (par ex. us-east-1) vers le bucket de votre région de DR (us-west-2) en suivant la documentation AWS indiquée ici.