AWS MSK (Managed Service Kafka) es un servicio totalmente administrado que facilita crear y ejecutar aplicaciones para procesar datos en streaming con Apache Kafka, una plataforma open-source para construir pipelines de datos en streaming en tiempo real.
AWS MSK Connector es una funcionalidad de AWS MSK que simplifica el envío de datos hacia y desde tus clústeres de Kafka mediante conectores totalmente administrados creados para Kafka Connect, un framework open-source que conecta clústeres de Kafka con sistemas externos como bases de datos, índices de búsqueda y sistemas de archivos.
Hemos acompañado a varios clientes que sufrieron interrupciones en producción al ejecutar clústeres de MSK en US Northern Virginia (us-east-1), una región propensa a outages. En esas conversaciones, una de las preguntas más frecuentes es cómo aprovechar mejor MSK durante este tipo de incidentes. Las dos soluciones que se suelen plantear son:
1. Mantener un clúster MSK de Disaster Recovery (DR) siempre activo (hot) en una región de DR.
2. Lanzar un clúster nuevo en una región de DR cuando haga falta, asumiendo los ~30 minutos de downtime que esto implica.
La primera opción es muy costosa y, si se elige, hay que contemplarla dentro del presupuesto de infraestructura. Solo se recomienda cuando la pérdida operativa por el downtime del clúster MSK supera el alto costo de mantener una infraestructura duplicada 24/7 en otra región.
La segunda opción, mucho más eficiente en costos, suele implicar unos 30 minutos de downtime por el tiempo que tarda AWS en aprovisionar un nuevo clúster MSK.
Sea cual sea la estrategia elegida, una vez que el clúster esté disponible vamos a necesitar los datos más recientes de los topics de Kafka, ya sea para el clúster de DR o para el clúster recién lanzado. Ahí es donde el AWS MSK Connector resulta muy útil. La idea general es respaldar los datos de los topics de Kafka en un bucket de S3 y luego restaurarlos en el clúster de reemplazo. La siguiente figura resume el enfoque que describiré en este blog post, en el que usaremos el Confluent Amazon S3 Sink Connector para mover los datos de los topics de MSK a un bucket de S3.
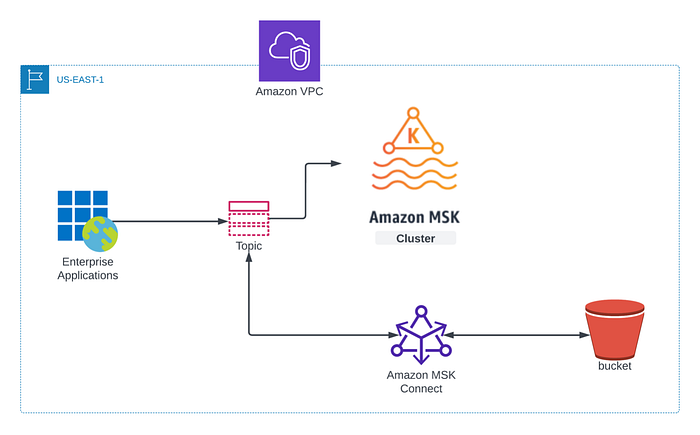
**Requisitos previos:**
1. Dos buckets de S3: uno en la misma región que el clúster MSK actual y otro en la región de DR
2. Un VPC Gateway Endpoint para S3
3. Replicación entre los dos buckets de S3
4. El archivo Zip del Confluent Amazon S3 Sink Connector
5. Un Log Group de AWS CloudWatch para monitorear los logs del AWS MSK Connector
6. Un rol para el Kafka Connector con la política de S3 que se describe a continuación
Paso 1: Crear los buckets de S3
Crea dos buckets de S3 distintos: uno en la región de producción y otro en la región de DR. En este ejemplo uso US N. Virginia (us-east-1) como región de producción y US Oregon (us-west-2) como región de DR.

**Paso 2: Lanzar el clúster MSK**
Lanza un nuevo clúster MSK (en muchos casos ya tendrás uno en ejecución, así que puedes saltarte este paso).
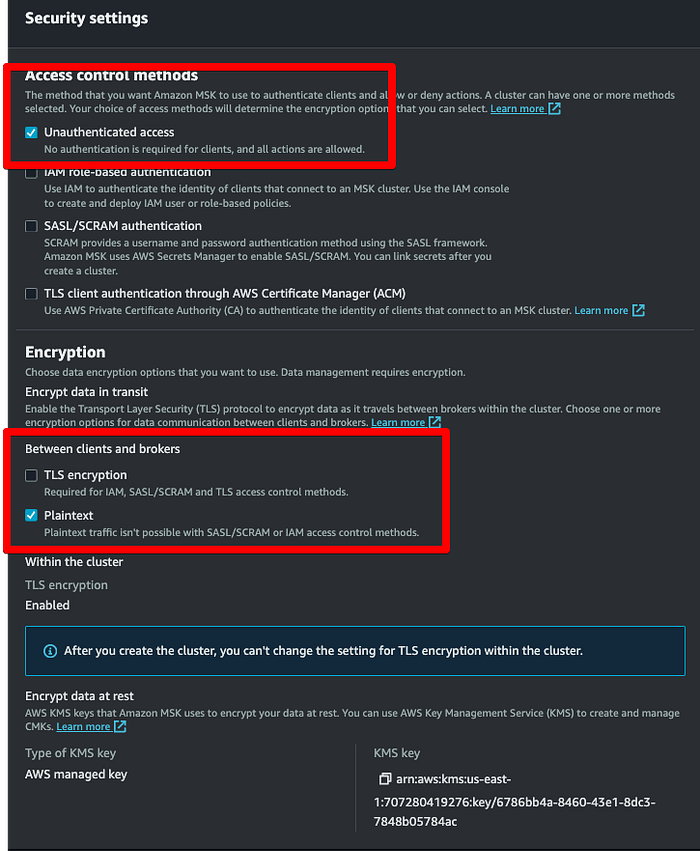
En la configuración de seguridad, asegúrate de que las dos casillas resaltadas en rojo sean las únicas seleccionadas. Estas 2 opciones se eligen porque, si quisiéramos cifrado, habría que crear certificados de cifrado a nivel de productor y consumidor, algo que queda fuera del alcance de este blog post.
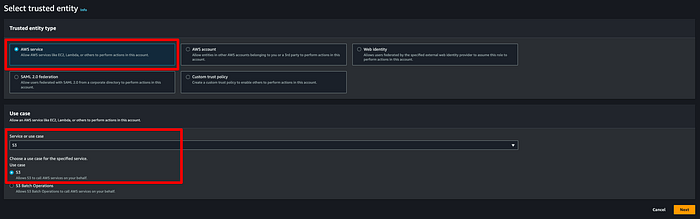
**Paso 3: Crear un rol de IAM para el MSK Connector con permisos de escritura sobre el bucket de destino**
Ahora necesitamos un rol que MSK pueda usar para escribir los datos de los topics en nuestro bucket de destino. Ve a la consola de IAM, haz clic en Roles > Create Roles y selecciona las opciones que se muestran a continuación. Yo creé un rol con el nombre " msk-blog-role".
Crea una política personalizada para tu rol de IAM de MSK que le dé acceso al bucket de S3 que vas a usar con el clúster de producción. A continuación está el JSON de la política de IAM que vas a adjuntar al rol. Yo nombré mi política " msk-blog-s3-policy":
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListAllMyBuckets"\
],\
"Resource": "arn:aws:s3:::*"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListBucket",\
"s3:GetBucketLocation",\
"s3:DeleteObject"\
],\
"Resource": "arn:aws:s3:::<name-of-your-bucket>"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:PutObject",\
"s3:GetObject",\
"s3:AbortMultipartUpload",\
"s3:ListMultipartUploadParts",\
"s3:ListBucketMultipartUploads"\
],\
"Resource": "*"\
}\
]
}
Una vez creada la política, adjúntala a tu rol:
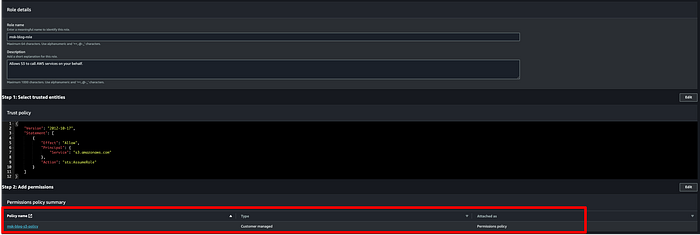
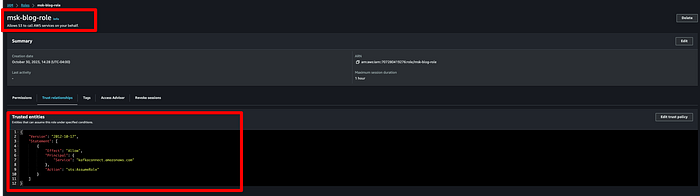
Ya con la política adjuntada, guarda el rol, haz clic en " Trust relationships" y reemplaza el contenido por el JSON siguiente:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "kafkaconnect.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
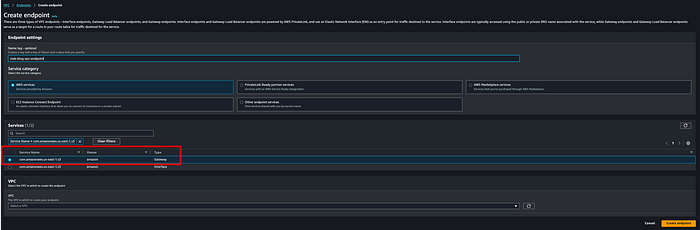
**Paso 4: Crear un endpoint de Amazon VPC desde el VPC del clúster MSK hacia Amazon S3**
Vas a necesitar un VPC endpoint para que el MSK Connector pueda escribir datos en el bucket de S3 de destino sin salir por el internet público. Yo creé el gateway endpoint msk-blog-vpc-endpoint:
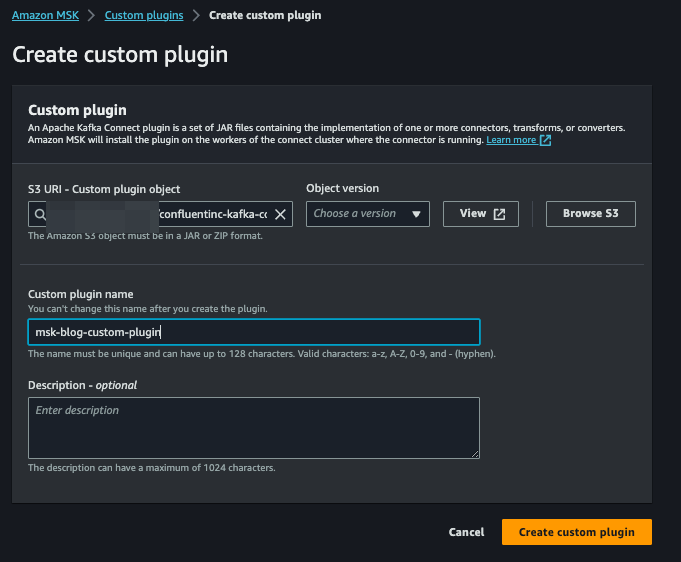
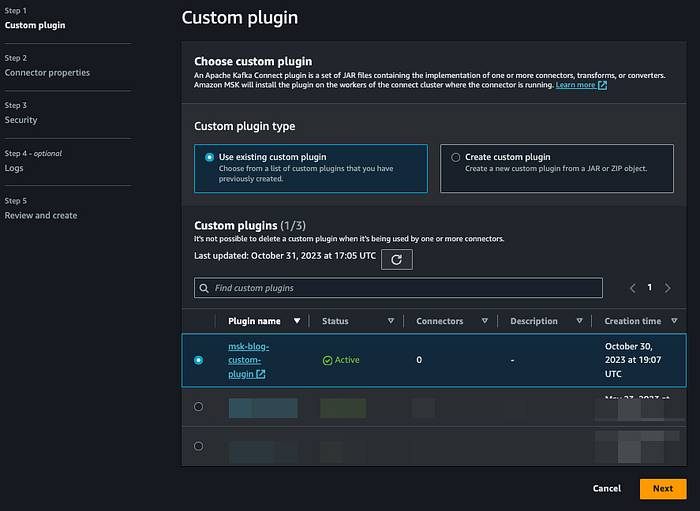
**Paso 5: Crear un plugin personalizado para el AWS MSK Connector usando el Confluent S3 Sink Connector**
Descarga el Confluent S3 Sink Connector [ LINK] y súbelo a un bucket de S3. Después, ve a la consola de AWS MSK, haz clic en "Custom plugins" en el menú lateral izquierdo y luego en "Create custom plugin". Selecciona el archivo zip navegando hasta el bucket de S3 donde lo subiste, asígnale un nombre al plugin y haz clic en "Create custom plugin":
**Paso 6: Crear una máquina cliente y un topic de Apache Kafka para pruebas.**
Lanza una instancia EC2 con la AMI de Amazon Linux 2. Luego, habilita esa instancia para que pueda enviar datos al clúster MSK: agrega el security group asociado al clúster MSK a las reglas de entrada de la nueva instancia EC2 para All Traffic, como se muestra a continuación:

Para crear un topic de Kafka, ejecuta el siguiente comando en la instancia EC2:
#Install Java
sudo yum install java-1.8.0
#Download Apache Kafka
wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
#Unzip the file
tar -xzf kafka_2.12-2.2.1.tgz
A continuación, obtén la información del cliente para una conexión a Apache ZooKeeper. Abajo se muestra dónde encontrarla en tu clúster MSK.
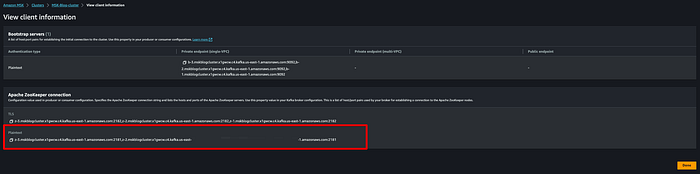
Usa esa cadena de conexión en texto plano al ejecutar el siguiente comando:
#Sample Command
<path-to-your-kafka-installation>/bin/kafka-topics.sh --create --bootstrap-server bootstrapServerString --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
#Actual Command will look like below.
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-topics.sh --create --bootstrap-server z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
**Paso 7: Crear el MSK Connector**
Crea un MSK Connector usando el plugin personalizado de Confluent que armamos antes:
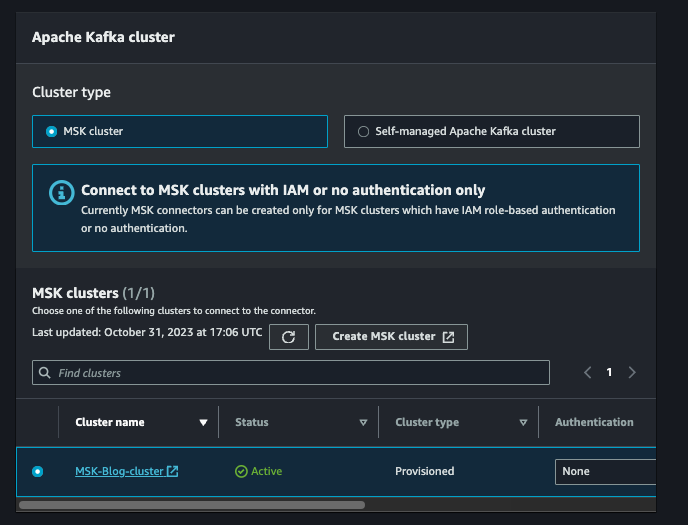
Haz clic en siguiente y nombra el connector según tu convención. Selecciona tu clúster MSK.
En el campo de configuración del connector, agrega el siguiente snippet de código. No olvides reemplazar el bucket de S3 por el nombre real de tu bucket de destino.
connector.class=io.confluent.connect.s3.S3SinkConnector
s3.region=us-east-1
format.class=io.confluent.connect.s3.format.json.JsonFormat
flush.size=1
schema.compatibility=NONE
tasks.max=2
topics.regex=name.(.*)
partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
storage.class=io.confluent.connect.s3.storage.S3Storage
s3.bucket.name=<my-destination-bucket>
topics.dir=tutorial
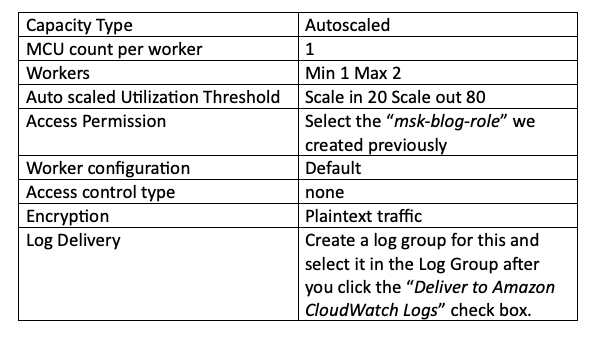
El resto de las configuraciones que vas a necesitar se listan a continuación. Estoy dejando capacity y workers en sus valores por defecto porque esto es un POC, pero tú deberás ajustar la capacidad según la cantidad de topics que maneje tu clúster MSK.
Por último, haz clic en "Create connector". Si todas las configuraciones quedaron correctas, como se mostró arriba, verás el texto verde " Running" en el campo de estado del connector. Si aparece "Failed", lo más probable es que se te haya pasado algún paso o que haya un error en alguno de los anteriores. Puedes revisar los logs de creación en el log group que creaste para este connector en CloudWatch Logs y así identificar qué falló:

Para comprobar si la integración del Connector funciona, vamos a generar mensajes de prueba en el servidor EC2 que actúa como productor.
Ejecuta el siguiente comando en el servidor EC2 productor:
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-console-producer.sh --broker-list z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
Escribe el mensaje que quieras en la línea de comandos del EC2. Espera uno o dos minutos y revisa el bucket de destino para ver si el mensaje quedó respaldado:
Listo: los datos de tu topic ya se están respaldando en el bucket de destino que creamos. Sin embargo, durante un outage de una región de AWS esos datos no estarán accesibles, así que debes asegurarte de configurar la replicación de datos desde el bucket de destino de producción (por ejemplo, us-east-1) hacia el bucket en tu región de DR (us-west-2), siguiendo la documentación de AWS enlazada aquí.