AWS MSK (Managed Service Kafka) è un servizio completamente gestito che semplifica lo sviluppo e l'esecuzione di applicazioni per elaborare dati in streaming con Apache Kafka, la piattaforma open-source per costruire pipeline di dati in streaming in tempo reale.
AWS MSK Connector è una funzionalità di AWS MSK che semplifica lo streaming di dati da e verso i cluster Kafka tramite connettori completamente gestiti, sviluppati per Kafka Connect, il framework open-source che collega i cluster Kafka a sistemi esterni come database, indici di ricerca e file system.
Abbiamo affiancato diversi clienti alle prese con interruzioni in produzione mentre eseguivano cluster MSK nella regione US Northern Virginia (us-east-1), nota per essere soggetta a outage; durante questi confronti ci viene spesso chiesto come gestire al meglio MSK in scenari di questo tipo. Le due soluzioni più frequenti sono:
1. Tenere sempre attivo un cluster MSK di Disaster Recovery (DR) hot in una regione DR.
2. Avviare un nuovo cluster all'occorrenza in una regione DR, accettando i circa 30 minuti di downtime che ne conseguono.
La prima soluzione è molto onerosa e, se adottata, va prevista nel budget dei costi infrastrutturali. È consigliata solo quando la perdita operativa generata dal downtime del cluster MSK supera l'elevato costo di un'infrastruttura duplicata 24/7 in un'altra regione.
La seconda opzione, decisamente più conveniente, comporta in genere circa 30 minuti di downtime, dovuti al tempo necessario ad AWS per il provisioning di un nuovo cluster MSK.
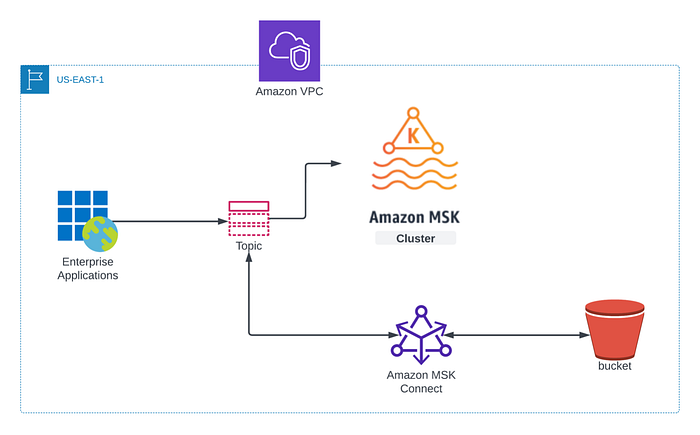
Indipendentemente dalla strategia adottata, una volta che il cluster è disponibile servono i dati più recenti dei topic Kafka da caricare sul cluster DR o sul cluster appena avviato. È qui che entra in gioco AWS MSK Connector. L'approccio generale prevede di eseguire il backup dei dati dei topic Kafka su un bucket S3 e di ripristinarli poi sul cluster sostitutivo. La figura seguente riassume l'approccio dettagliato che illustrerò in questo blog post: useremo il Confluent Amazon S3 Sink Connector per spostare i dati dei topic MSK in un bucket S3.
**Prerequisiti:**
1. Due bucket S3: uno nella stessa regione del cluster MSK attuale e l'altro nella regione DR
2. Un VPC Gateway Endpoint per S3
3. Replica tra i due bucket S3
4. File ZIP del Confluent Amazon S3 Sink Connector
5. Un AWS CloudWatch Log Group per monitorare i log di AWS MSK Connector
6. Un ruolo per il Kafka Connector con la policy S3 descritta più avanti
Step 1: creare i bucket S3
Creare due bucket S3 distinti, uno nella regione di produzione e l'altro nella regione DR. Nel mio caso uso US N. Virginia (us-east-1) come regione di produzione e US Oregon (us-west-2) come regione DR.

**Step 2: avviare il cluster MSK**
Avviare un nuovo cluster MSK (spesso si dispone già di un cluster MSK in esecuzione, quindi è possibile saltare questo passaggio).
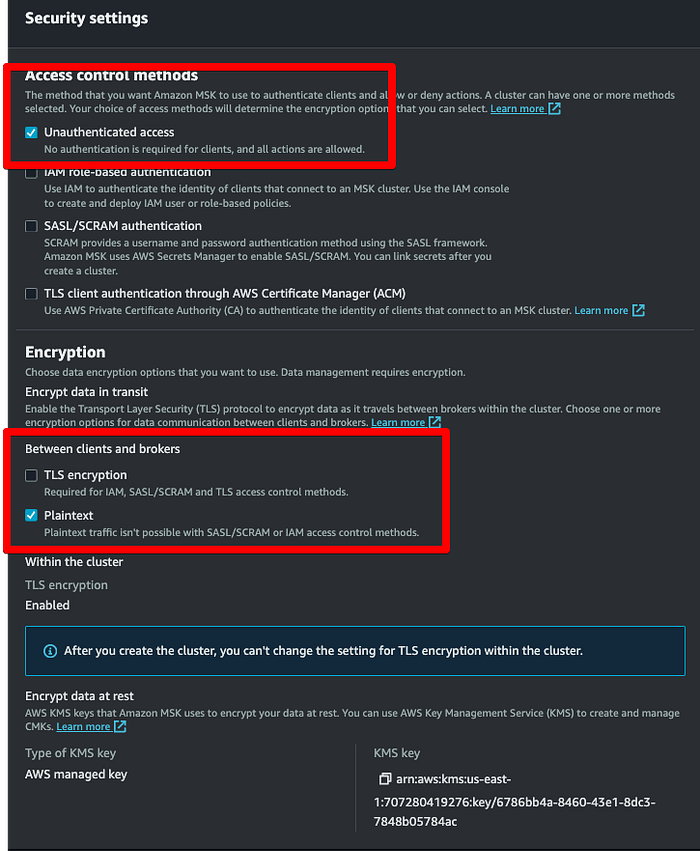
Nelle impostazioni di sicurezza, verificare che le uniche caselle selezionate siano le due evidenziate in rosso. Il motivo è semplice: per abilitare la crittografia occorrerebbe creare certificati a livello di producer e consumer, argomento che esula da questo blog post.
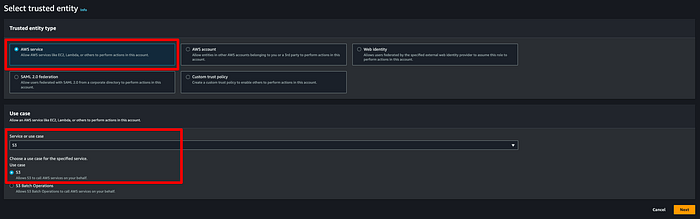
**Step 3: creare un ruolo IAM per MSK Connector con i permessi di scrittura sul bucket di destinazione**
Serve ora un ruolo che MSK possa assumere per scrivere i dati dei topic sul bucket di destinazione. Aprire la console IAM, fare clic su Roles > Create Roles e selezionare le opzioni indicate sotto. Ho creato un ruolo chiamato "msk-blog-role".
Creare una policy personalizzata per il ruolo IAM di MSK, in modo che possa accedere al bucket S3 destinato al cluster di produzione. Di seguito il JSON della policy IAM da associare al ruolo. Ho chiamato la mia policy "msk-blog-s3-policy":
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListAllMyBuckets"\
],\
"Resource": "arn:aws:s3:::*"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListBucket",\
"s3:GetBucketLocation",\
"s3:DeleteObject"\
],\
"Resource": "arn:aws:s3:::<name-of-your-bucket>"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:PutObject",\
"s3:GetObject",\
"s3:AbortMultipartUpload",\
"s3:ListMultipartUploadParts",\
"s3:ListBucketMultipartUploads"\
],\
"Resource": "*"\
}\
]
}
Una volta creata la policy, associarla al ruolo:
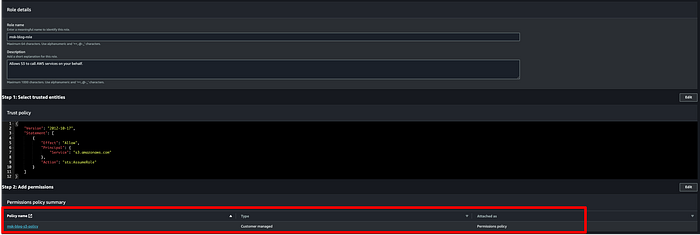
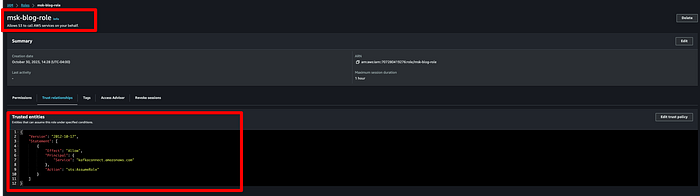
Dopo aver associato la policy, salvare il ruolo, fare clic su "Trust relationships" e sostituirne il contenuto con il JSON seguente:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "kafkaconnect.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
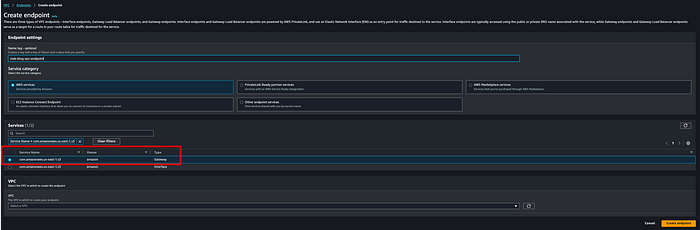
**Step 4: creare un endpoint Amazon VPC dalla VPC del cluster MSK ad Amazon S3**
Per consentire a MSK Connector di scrivere sul bucket S3 di destinazione senza passare dalla rete internet pubblica serve un endpoint VPC. Ho creato il gateway endpoint msk-blog-vpc-endpoint:
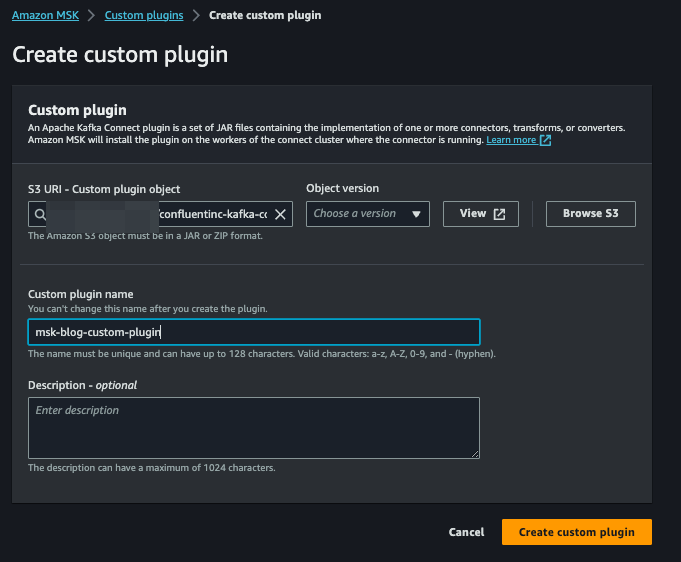
**Step 5: creare un plugin personalizzato per AWS MSK Connector con il Confluent S3 Sink Connector**
Scaricare il Confluent S3 Sink Connector [LINK] e caricarlo su un bucket S3. Aprire poi la console di AWS MSK, fare clic su "Custom plugins" nel menu a sinistra e quindi su "Create custom plugin". Selezionare il file ZIP nel bucket S3 in cui è stato caricato il Confluent S3 Sink Connector, assegnare un nome al plugin e fare clic su "Create custom plugin":
**Step 6: creare una macchina client e un topic Apache Kafka per i test**
Avviare un'istanza EC2 con AMI Amazon Linux 2. Abilitare la nuova istanza EC2 a inviare dati al cluster MSK aggiungendo il security group del cluster MSK alle regole inbound della nuova istanza EC2 per All Traffic, come mostrato di seguito:

Per creare un topic Kafka, eseguire il comando seguente sull'istanza EC2:
#Install Java
sudo yum install java-1.8.0
#Download Apache Kafka
wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
#Unzip the file
tar -xzf kafka_2.12-2.2.1.tgz
Recuperare poi le informazioni del client per la connessione ad Apache ZooKeeper. L'immagine sotto indica dove trovarle nel proprio cluster MSK.
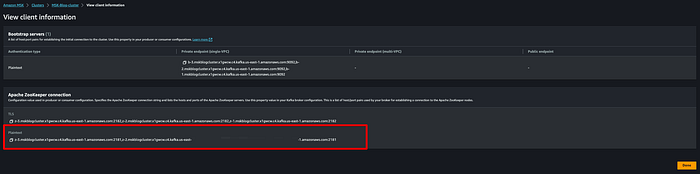
Usare la stringa di connessione in plain text quando si esegue il comando seguente:
#Sample Command
<path-to-your-kafka-installation>/bin/kafka-topics.sh --create --bootstrap-server bootstrapServerString --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
#Actual Command will look like below.
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-topics.sh --create --bootstrap-server z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
**Step 7: creare l'MSK Connector**
Creare un MSK Connector utilizzando il plugin Confluent personalizzato realizzato in precedenza:
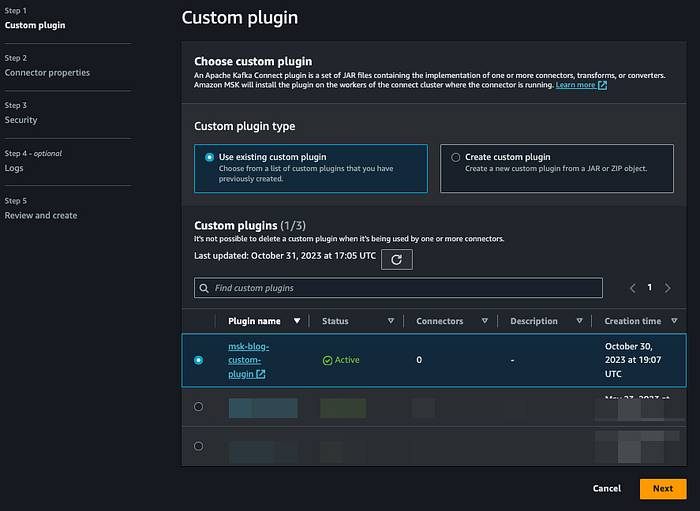
Fare clic su Avanti e dare al connettore un nome conforme alle proprie convenzioni. Selezionare quindi il cluster MSK.
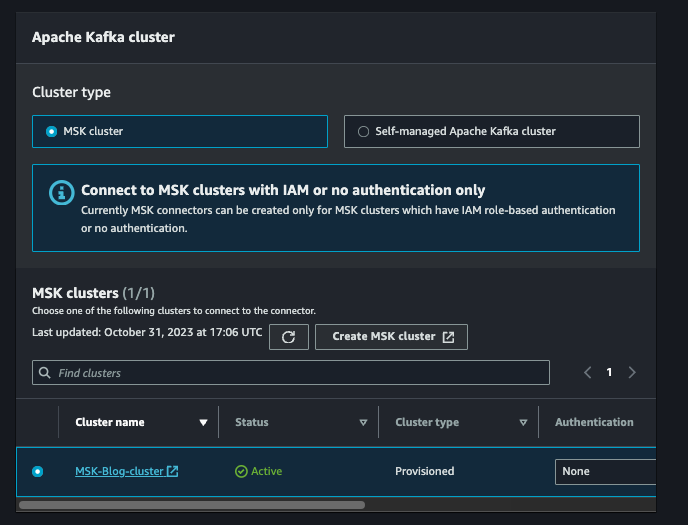
Nel campo di configurazione del connettore, incollare lo snippet di codice qui sotto. Ricordarsi di sostituire il bucket S3 con il nome effettivo del bucket di destinazione.
connector.class=io.confluent.connect.s3.S3SinkConnector
s3.region=us-east-1
format.class=io.confluent.connect.s3.format.json.JsonFormat
flush.size=1
schema.compatibility=NONE
tasks.max=2
topics.regex=name.(.*)
partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
storage.class=io.confluent.connect.s3.storage.S3Storage
s3.bucket.name=<my-destination-bucket>
topics.dir=tutorial
Le restanti configurazioni necessarie sono elencate qui sotto. Lascio capacity e workers ai valori predefiniti trattandosi di una POC, ma è bene calibrare la capacity in base al numero di topic gestiti dal cluster MSK.
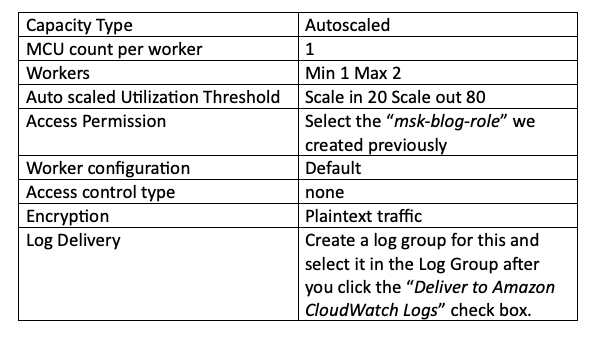
Infine, fare clic su "Create connector". Se le impostazioni sono corrette come indicato sopra, nel campo dello stato del connettore comparirà la scritta verde "Running". Se invece compare "Failed", probabilmente è stato saltato un passaggio o commesso un errore in uno dei precedenti. Per individuare la causa è possibile consultare i log di creazione nel log group creato per questo connettore in CloudWatch Logs:

Per verificare il funzionamento dell'integrazione del connettore, generiamo alcuni messaggi di test sul server EC2 che fa da producer.
Eseguire il comando seguente sul server EC2 producer:
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-console-producer.sh --broker-list z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
Digitare un messaggio qualsiasi dalla riga di comando dell'EC2. Attendere uno o due minuti, quindi controllare il bucket di destinazione per verificare che il messaggio sia stato salvato:
Ora i dati del topic vengono salvati nel bucket di destinazione che abbiamo creato. Tuttavia, in caso di outage di una regione AWS, quei dati non saranno raggiungibili: occorre quindi configurare la replica dal bucket di produzione di destinazione (es. us-east-1) al bucket nella regione DR (us-west-2), seguendo la documentazione AWS qui collegata.