AWS MSK (Managed Service Kafka) ist ein vollständig verwalteter Service, mit dem sich Anwendungen zur Verarbeitung von Streaming-Daten auf Basis von Apache Kafka komfortabel erstellen und betreiben lassen. Apache Kafka ist eine Open-Source-Plattform für Datenpipelines im Echtzeit-Streaming.
AWS MSK Connector ist ein Feature von AWS MSK, mit dem sich Daten über vollständig verwaltete Connectors für Kafka Connect bequem in und aus Ihren Kafka-Clustern streamen lassen. Kafka Connect ist ein Open-Source-Framework, das Kafka-Cluster mit externen Systemen wie Datenbanken, Suchindizes oder Dateisystemen verbindet.
Wir haben bereits mehrere Kunden bei Produktionsausfällen unterstützt, deren MSK-Cluster in der ausfallanfälligen Region US Northern Virginia (us-east-1) liefen. Dabei werden wir häufig gefragt, wie sich MSK bei solchen Ausfällen am besten nutzen lässt. In der Regel werden zwei Lösungen vorgeschlagen:
1. Einen heißen Disaster-Recovery-(DR-)MSK-Cluster dauerhaft in einer DR-Region betreiben.
2. Im Bedarfsfall einen neuen Cluster in einer DR-Region starten – trotz der dabei anfallenden ca. 30 Minuten Ausfallzeit.
Lösung eins ist sehr kostspielig und muss in diesem Fall fest in die Infrastrukturkosten eingeplant werden. Sie lohnt sich nur, wenn der betriebliche Schaden durch einen MSK-Cluster-Ausfall die hohen Kosten einer rund um die Uhr betriebenen, duplizierten Infrastruktur in einer weiteren Region übersteigt.
Option zwei ist deutlich günstiger, bringt aber meist rund 30 Minuten Ausfallzeit mit sich, weil AWS für die Bereitstellung eines neuen MSK-Clusters entsprechend Zeit benötigt.
Unabhängig davon, für welche Strategie Sie sich entscheiden: Sobald ein Cluster verfügbar ist, brauchen wir die aktuellen Kafka-Topic-Daten – sei es für den DR-Cluster oder den neu gestarteten Cluster. Genau hier kommt der AWS MSK Connector ins Spiel. Der grundsätzliche Ansatz: die Kafka-Topic-Daten in einen S3-Bucket sichern und anschließend im Ersatz-Cluster wiederherstellen. Die folgende Abbildung fasst das Vorgehen zusammen, das ich in diesem Blogpost im Detail beschreibe. Dabei nutzen wir den Confluent Amazon S3 Sink Connector, um MSK-Topic-Daten in einen S3-Bucket zu übertragen.
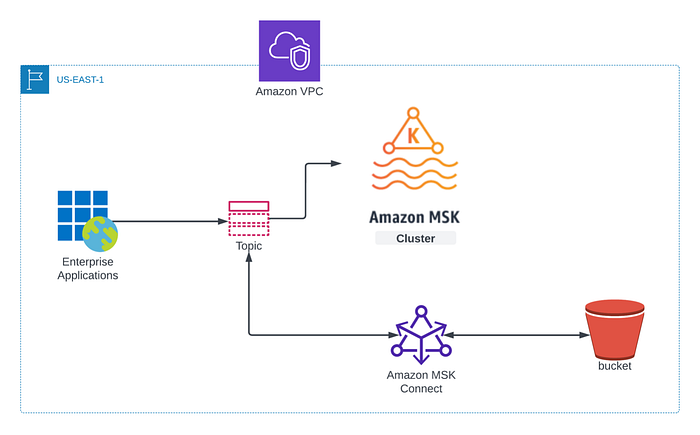
**Voraussetzungen:**
1. Zwei S3-Buckets – einer in derselben Region wie der aktuelle MSK-Cluster, der zweite in der DR-Region
2. S3 VPC Gateway Endpoint
3. Replikation zwischen den beiden S3-Buckets
4. ZIP-Datei des Confluent Amazon S3 Sink Connectors
5. AWS CloudWatch Log Group zum Monitoring der AWS-MSK-Connector-Logs
6. Kafka-Connector-Rolle mit der unten beschriebenen S3-Policy
Schritt 1: S3-Buckets anlegen
Legen Sie zwei separate S3-Buckets an – einen in der Produktionsregion und einen in der DR-Region. Ich verwende US N. Virginia (us-east-1) als Produktionsregion und US Oregon (us-west-2) als DR-Region.

**Schritt 2: MSK-Cluster starten**
Starten Sie einen neuen MSK-Cluster (in vielen Fällen läuft bereits ein MSK-Cluster, sodass Sie diesen Schritt überspringen können).
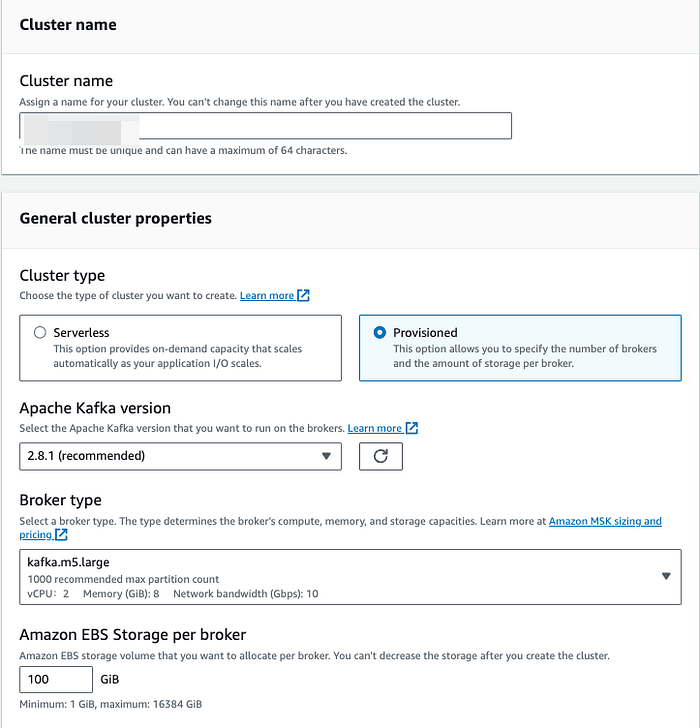
Achten Sie in den Sicherheitseinstellungen darauf, dass nur die beiden rot markierten Checkboxen aktiviert sind. Diese beiden Optionen sind deshalb gewählt, weil bei aktivierter Verschlüsselung Verschlüsselungszertifikate auf Producer- und Consumer-Ebene erstellt werden müssten – das würde den Rahmen dieses Blogposts sprengen.
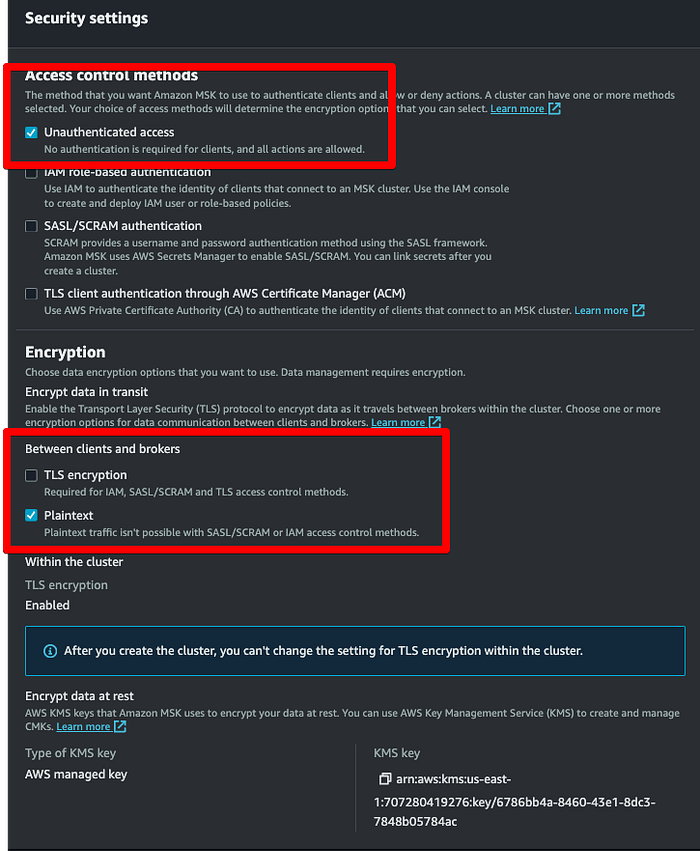
**Schritt 3: IAM-Rolle für den MSK Connector mit Schreibzugriff auf den Ziel-Bucket erstellen**
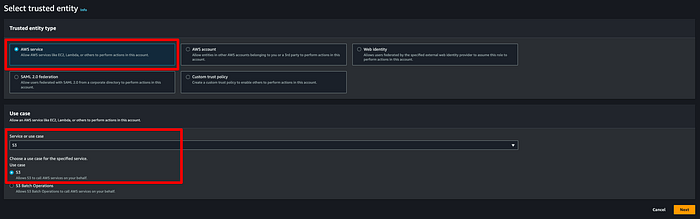
Als Nächstes brauchen wir eine Rolle, mit der MSK Topic-Daten in den Ziel-Bucket schreiben kann. Öffnen Sie die IAM-Konsole, klicken Sie auf Roles > Create Roles und wählen Sie die unten gezeigten Optionen. Ich habe eine Rolle mit dem Namen "msk-blog-role" angelegt.
Erstellen Sie eine eigene Policy für Ihre MSK-IAM-Rolle, damit diese auf den S3-Bucket des Produktions-Clusters zugreifen kann. Unten sehen Sie das JSON für die IAM-Policy, die Sie an die IAM-Rolle anhängen. Ich habe meine Policy "msk-blog-s3-policy" genannt:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListAllMyBuckets"\
],\
"Resource": "arn:aws:s3:::*"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListBucket",\
"s3:GetBucketLocation",\
"s3:DeleteObject"\
],\
"Resource": "arn:aws:s3:::<name-of-your-bucket>"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:PutObject",\
"s3:GetObject",\
"s3:AbortMultipartUpload",\
"s3:ListMultipartUploadParts",\
"s3:ListBucketMultipartUploads"\
],\
"Resource": "*"\
}\
]
}
Hängen Sie die Policy nach der Erstellung an Ihre Rolle an:
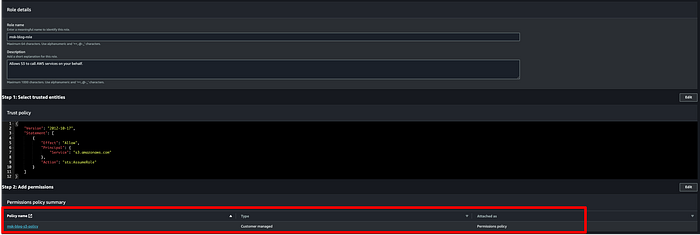
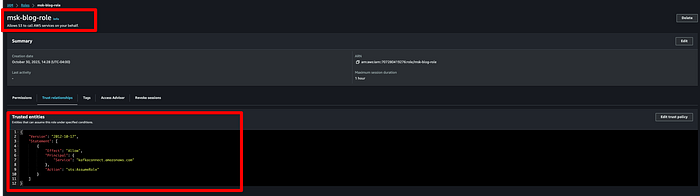
Speichern Sie die Rolle nach dem Anhängen der Policy, klicken Sie anschließend auf "Trust relationships" und ersetzen Sie den Inhalt durch das folgende JSON:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "kafkaconnect.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
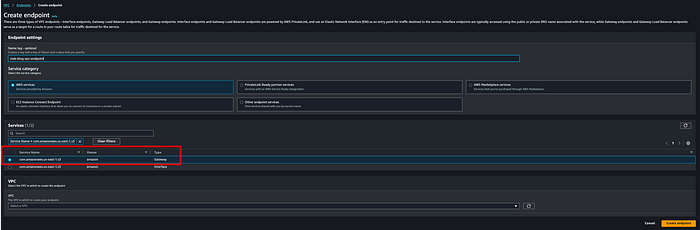
**Schritt 4: Amazon-VPC-Endpoint vom MSK-Cluster-VPC zu Amazon S3 anlegen**
Damit der MSK Connector Daten in den Ziel-S3-Bucket schreiben kann, ohne den Datenverkehr über das offene Internet zu leiten, benötigen Sie einen VPC-Endpoint. Ich habe den Gateway-Endpoint msk-blog-vpc-endpoint angelegt:
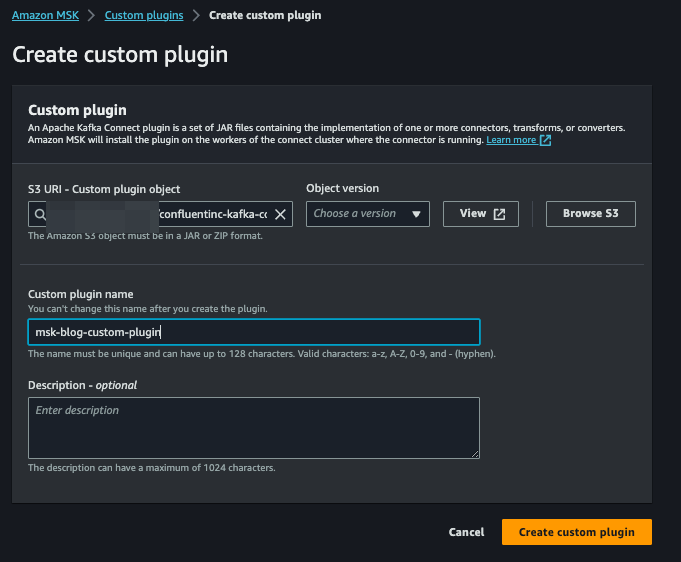
**Schritt 5: Custom Plugin für den AWS MSK Connector mit dem Confluent S3 Sink Connector erstellen**
Laden Sie den Confluent S3 Sink Connector [LINK] herunter und in einen S3-Bucket hoch. Wechseln Sie anschließend in die AWS-MSK-Konsole, klicken Sie links auf "Custom plugins" und dann auf "Create custom plugin". Wählen Sie die ZIP-Datei in dem S3-Bucket aus, in den Sie zuvor die Confluent-S3-Sink-Connector-ZIP geladen haben, vergeben Sie einen Namen für das Plugin und klicken Sie auf "Create custom plugin":
**Schritt 6: Client-Maschine und Apache-Kafka-Topic für Tests anlegen**
Starten Sie eine EC2-Instanz mit dem Amazon Linux 2 AMI. Erlauben Sie dieser neuen EC2-Instanz anschließend, Daten an den MSK-Cluster zu senden. Fügen Sie dazu die Security Group des MSK-Clusters in den Inbound-Regeln der neuen EC2-Instanz für den gesamten Datenverkehr (All Traffic) hinzu, wie unten gezeigt:

Führen Sie zum Anlegen eines Kafka-Topics folgenden Befehl auf der EC2-Instanz aus:
#Java installieren
sudo yum install java-1.8.0
#Apache Kafka herunterladen
wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
#Datei entpacken
tar -xzf kafka_2.12-2.2.1.tgz
Holen Sie sich anschließend die Client-Informationen für eine Apache-ZooKeeper-Verbindung. Unten sehen Sie, wo Sie diese für Ihren MSK-Cluster finden.
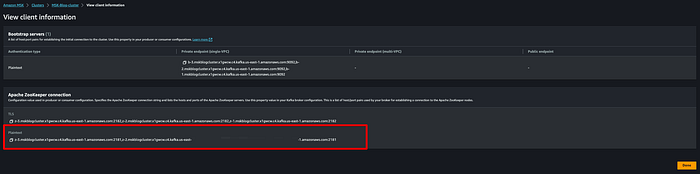
Verwenden Sie diesen Plain-Text-Verbindungs-String beim Ausführen des folgenden Befehls:
#Beispielbefehl
<path-to-your-kafka-installation>/bin/kafka-topics.sh --create --bootstrap-server bootstrapServerString --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
#Der tatsächliche Befehl sieht in etwa so aus:
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-topics.sh --create --bootstrap-server z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
**Schritt 7: MSK Connector erstellen**
Erstellen Sie einen MSK Connector auf Basis des zuvor angelegten Custom-Confluent-Plugins:
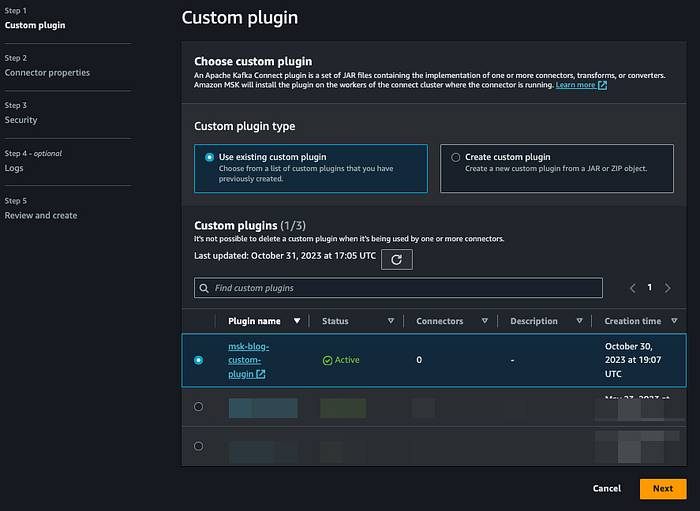
Klicken Sie auf "Next" und vergeben Sie einen Namen für den Connector entsprechend Ihrer Konvention. Wählen Sie Ihren MSK-Cluster aus.
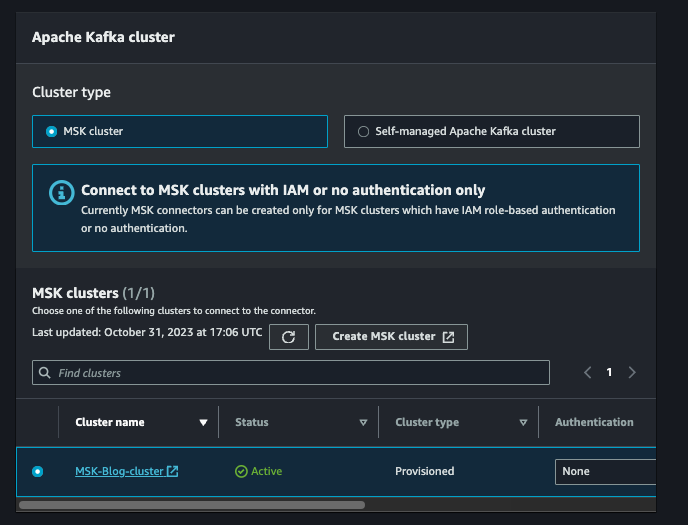
Tragen Sie im Feld "Connector configuration" das folgende Code-Snippet ein. Vergessen Sie nicht, den S3-Bucket-Namen durch den tatsächlichen Namen Ihres Ziel-Buckets zu ersetzen.
connector.class=io.confluent.connect.s3.S3SinkConnector
s3.region=us-east-1
format.class=io.confluent.connect.s3.format.json.JsonFormat
flush.size=1
schema.compatibility=NONE
tasks.max=2
topics.regex=name.(.*)
partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
storage.class=io.confluent.connect.s3.storage.S3Storage
s3.bucket.name=<my-destination-bucket>
topics.dir=tutorial
Die übrigen erforderlichen Konfigurationen finden Sie unten. Capacity und Workers belasse ich auf den Standardwerten, da es sich um einen POC handelt – in der Praxis sollten Sie die Capacity an die Anzahl der Topics anpassen, die Ihr MSK-Cluster verarbeitet.
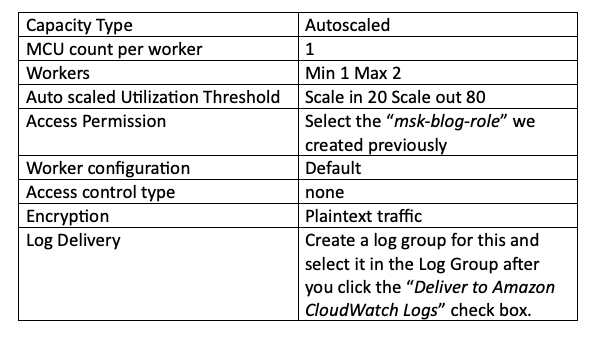
Klicken Sie zum Schluss auf "Create connector". Wenn alle Einstellungen wie oben gezeigt korrekt vorgenommen sind, erscheint im Statusfeld Ihres Connectors der grüne Text "Running". Wird stattdessen "Failed" angezeigt, wurde wahrscheinlich ein Schritt übersehen oder bei der Konfiguration ein Fehler gemacht. In der für diesen Connector angelegten Log Group in CloudWatch Logs können Sie die Erstellungs-Logs einsehen, um die Ursache einzugrenzen:

Um zu prüfen, ob die Connector-Integration funktioniert, erstellen wir auf dem EC2-Server für unseren Producer ein paar Testnachrichten.
Führen Sie dazu den folgenden Befehl auf dem Producer-EC2-Server aus:
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-console-producer.sh --broker-list z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
Geben Sie auf der EC2-Kommandozeile eine beliebige Nachricht ein. Warten Sie ein bis zwei Minuten und prüfen Sie dann im Ziel-Bucket, ob die Nachricht dort gesichert wurde:
Ihre Topic-Daten werden nun in den von uns angelegten Ziel-Bucket gesichert. Bei einem Ausfall einer AWS-Region sind diese Daten allerdings nicht erreichbar. Richten Sie daher unbedingt eine Datenreplikation vom Produktions-Ziel-Bucket (z. B. us-east-1) auf den Bucket in Ihrer DR-Region (us-west-2) ein – folgen Sie dazu der hier verlinkten AWS-Dokumentation.