O AWS MSK (Managed Service Kafka) é um serviço totalmente gerenciado que facilita a criação e a execução de aplicações para processar dados em streaming com o Apache Kafka, uma plataforma open source para construir pipelines de dados em streaming em tempo real.
O AWS MSK Connector é um recurso do AWS MSK que simplifica o streaming de dados de e para seus clusters Kafka usando conectores totalmente gerenciados, criados sobre o Kafka Connect — um framework open source para conectar clusters Kafka a sistemas externos, como bancos de dados, índices de busca e sistemas de arquivos.
Já ajudamos vários clientes que enfrentaram interrupções em produção rodando clusters MSK na região US Northern Virginia (us-east-1), conhecida pelo histórico de instabilidades, e nessas conversas é comum nos perguntarem qual é a melhor forma de usar o MSK durante esses incidentes. As duas soluções mais sugeridas são:
1. Manter um cluster MSK de Disaster Recovery (DR) em modo hot, sempre rodando em uma região de DR.
2. Subir um novo cluster sob demanda em uma região de DR, mesmo arcando com cerca de 30 minutos de downtime.
A primeira solução é bem cara e, se for a escolhida, precisa entrar no orçamento de infraestrutura. Ela só faz sentido quando a perda operacional do negócio causada pelo downtime do cluster MSK supera o custo elevado de manter uma infraestrutura duplicada 24/7 em outra região.
Já a segunda opção, bem mais econômica, costuma envolver cerca de 30 minutos de downtime por causa do tempo que a AWS leva para provisionar um novo cluster MSK.
Independentemente da estratégia escolhida, assim que houver um cluster disponível, vamos precisar dos dados mais recentes dos tópicos Kafka no cluster de DR ou no cluster recém-criado. É aí que o AWS MSK connector entra em cena. A ideia geral é fazer backup dos dados dos tópicos Kafka em um bucket S3 e depois restaurá-los no cluster substituto. A figura abaixo resume a abordagem detalhada que vou descrever neste post, na qual usaremos o Confluent Amazon S3 Sink Connector para mover os dados dos tópicos do MSK para um bucket S3.
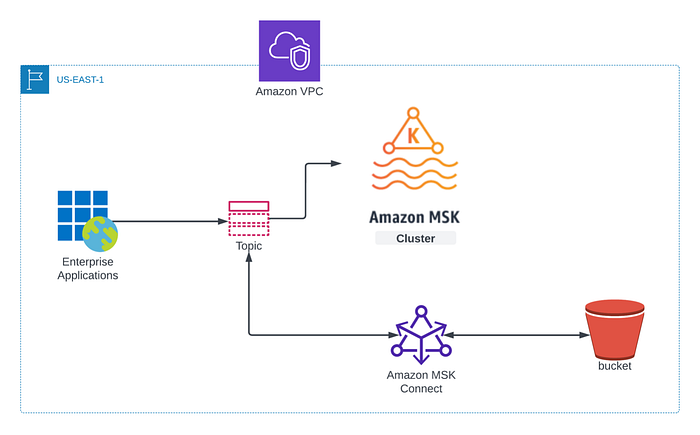
**Pré-requisitos:**
1. Dois buckets S3, um na mesma região do cluster MSK atual e outro na região de DR
2. S3 VPC Gateway Endpoint
3. Replicação entre os dois buckets S3
4. Arquivo zip do Confluent Amazon S3 Sink Connector
5. AWS CloudWatch Log Group para monitorar os logs do AWS MSK connector
6. Role do Kafka Connector com a policy de S3 descrita abaixo
Passo 1: criar os buckets S3
Crie dois buckets S3 separados: um na região de produção e outro na região de DR. Estou usando US N. Virginia (us-east-1) como região de produção e US Oregon (us-west-2) como região de DR.

**Passo 2: subir o cluster MSK**
Suba um novo cluster MSK (na maioria dos casos você já terá um cluster MSK em execução, então pode pular esta etapa).
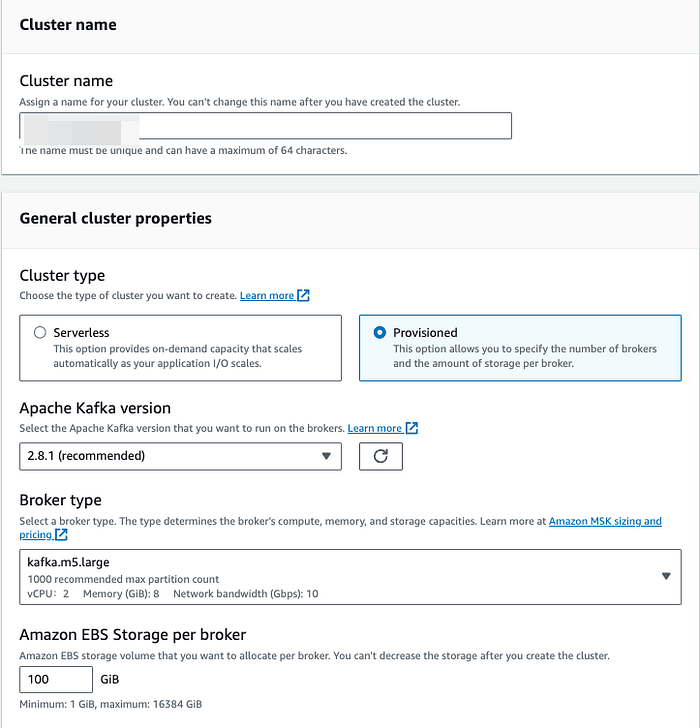
Nas configurações de segurança, deixe marcadas apenas as duas caixas destacadas em vermelho. Selecionamos só essas 2 opções porque, para usar criptografia, seria preciso criar certificados nos níveis de producer e consumer, o que está fora do escopo deste post.
**Passo 3: criar uma role IAM para o MSK connector com permissão de escrita no bucket de destino**
Agora precisamos de uma role que o MSK possa assumir para gravar dados de tópicos no bucket de destino. Acesse o console do IAM, clique em Roles > Create Roles e selecione as opções abaixo. Criei uma role chamada " msk-blog-role".
Crie uma policy customizada para a sua role IAM do MSK, dando acesso ao bucket S3 que será usado com o cluster de produção. Abaixo está o JSON da policy IAM a ser anexada à role. Nomeei a minha como " msk-blog-s3-policy":
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListAllMyBuckets"\
],\
"Resource": "arn:aws:s3:::*"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:ListBucket",\
"s3:GetBucketLocation",\
"s3:DeleteObject"\
],\
"Resource": "arn:aws:s3:::<name-of-your-bucket>"\
},\
{\
"Effect": "Allow",\
"Action": [\
"s3:PutObject",\
"s3:GetObject",\
"s3:AbortMultipartUpload",\
"s3:ListMultipartUploadParts",\
"s3:ListBucketMultipartUploads"\
],\
"Resource": "*"\
}\
]
}
Depois de criada, anexe a policy à sua role:
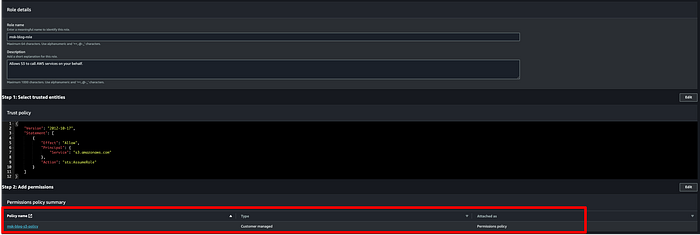
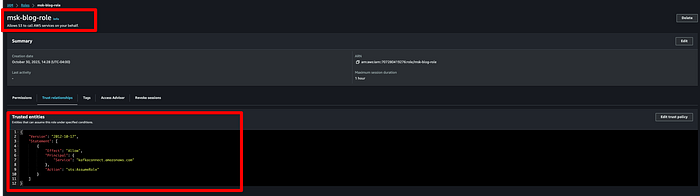
Com a policy anexada, salve a role, clique em " Trust relationships" e substitua o conteúdo pelo JSON abaixo:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "kafkaconnect.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
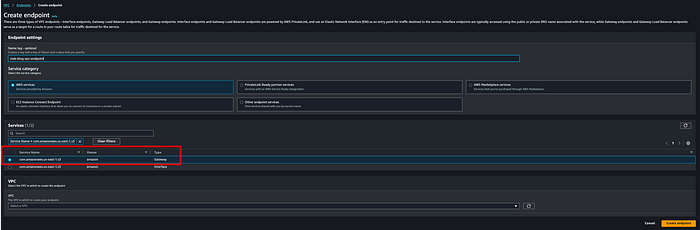
**Passo 4: criar um Amazon VPC endpoint da VPC do cluster MSK até o Amazon S3**
Você vai precisar de um VPC endpoint para que o MSK connector grave dados no bucket S3 de destino sem trafegar pela internet pública. Criei o gateway endpoint msk-blog-vpc-endpoint:
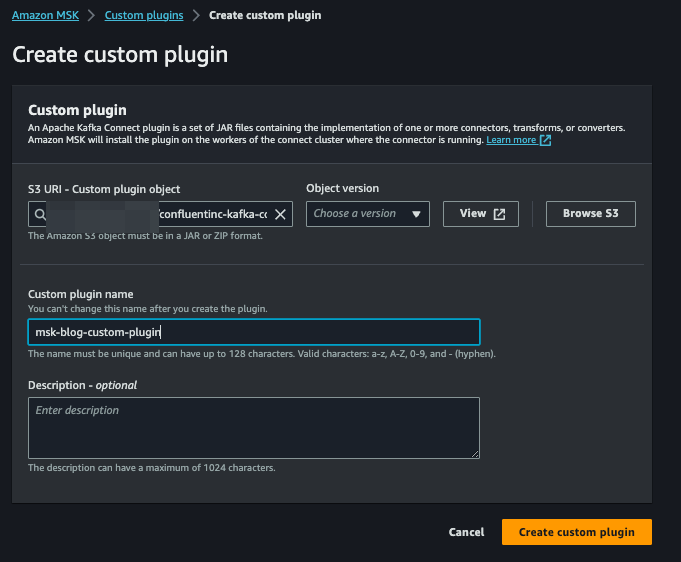
**Passo 5: criar um custom plugin para o AWS MSK connector usando o Confluent S3 Sink Connector**
Baixe o Confluent S3 Sink Connector [ LINK] e faça upload em um bucket S3. Em seguida, vá até o console do AWS MSK, clique em "Custom plugins" no menu lateral esquerdo e depois em "Create custom plugin". Selecione o arquivo zip navegando até o bucket S3 onde você fez o upload, dê um nome ao plugin e clique em "Create custom plugin":
**Passo 6: criar uma máquina cliente e um tópico Apache Kafka para teste**
Suba uma instância EC2 com a AMI do Amazon Linux 2. Em seguida, libere essa nova instância EC2 para enviar dados ao cluster MSK adicionando o security group do cluster MSK às regras de inbound da nova instância EC2 para All Traffic, como mostrado abaixo:

Para criar um tópico Kafka, execute os comandos a seguir na instância EC2:
#Install Java
sudo yum install java-1.8.0
#Download Apache Kafka
wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
#Unzip the file
tar -xzf kafka_2.12-2.2.1.tgz
Agora obtenha as informações de cliente para a conexão com o Apache ZooKeeper. A imagem abaixo mostra onde encontrar isso para o seu cluster MSK.
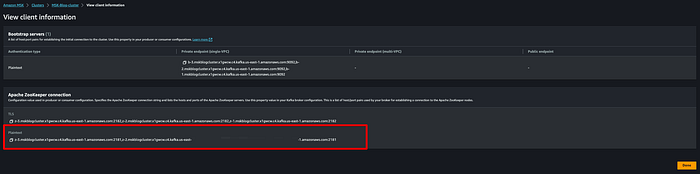
Use essa string de conexão em texto puro ao executar o comando abaixo:
#Sample Command
<path-to-your-kafka-installation>/bin/kafka-topics.sh --create --bootstrap-server bootstrapServerString --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
#Actual Command will look like below.
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-topics.sh --create --bootstrap-server z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
**Passo 7: criar o MSK connector**
Crie um MSK connector usando o custom plugin do Confluent que criamos antes:
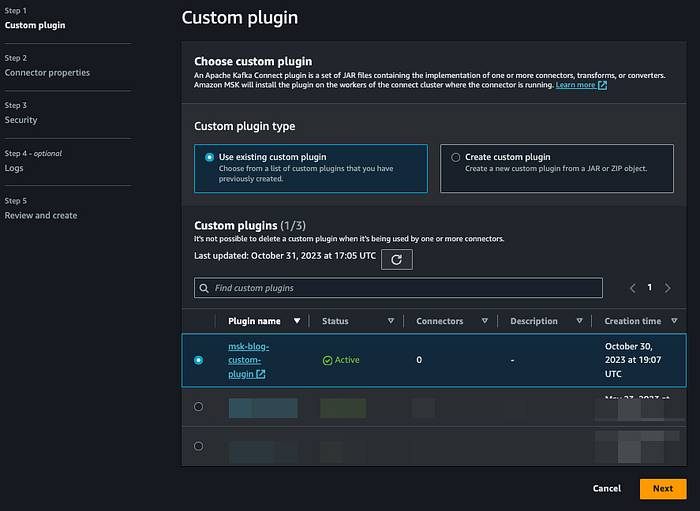
Clique em next e dê um nome ao connector seguindo a sua convenção. Selecione o seu cluster MSK.
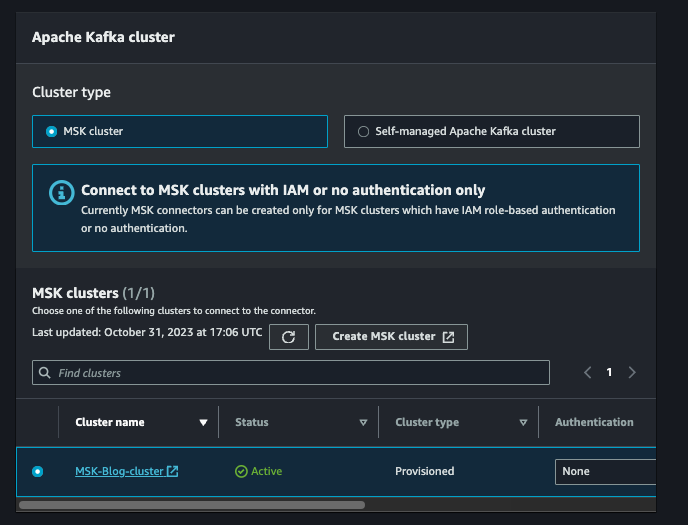
No campo de configuração do connector, adicione o snippet abaixo. Não esqueça de trocar o S3 bucket pelo nome real do seu bucket de destino.
connector.class=io.confluent.connect.s3.S3SinkConnector
s3.region=us-east-1
format.class=io.confluent.connect.s3.format.json.JsonFormat
flush.size=1
schema.compatibility=NONE
tasks.max=2
topics.regex=name.(.*)
partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
storage.class=io.confluent.connect.s3.storage.S3Storage
s3.bucket.name=<my-destination-bucket>
topics.dir=tutorial
As demais configurações necessárias estão listadas abaixo. Mantive capacity e workers nos valores padrão por se tratar de uma POC, mas você precisa ajustar a capacity de acordo com a quantidade de tópicos que o seu cluster MSK processa.
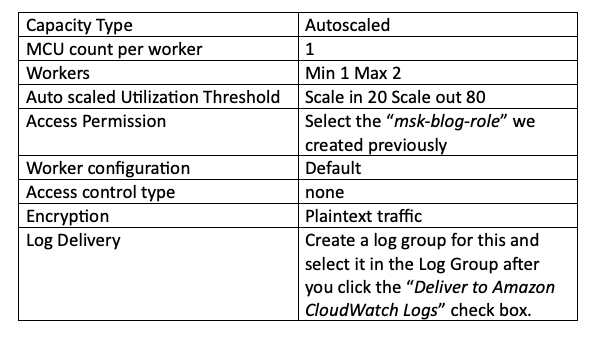
Por fim, clique em "Create connector". Se tudo estiver configurado corretamente, como mostrado acima, você verá o texto verde " Running" no campo de status do connector. Se aparecer "Failed", provavelmente alguma etapa foi pulada ou algo saiu errado nos passos anteriores. Confira os logs de criação no log group que você criou para esse connector no Cloud Watch logs para identificar o que aconteceu:

Para testar se a integração do Connector está funcionando, vamos criar mensagens de teste no servidor EC2 do nosso producer.
Execute o comando abaixo no servidor EC2 do producer:
/home/ec2-user/kafka_2.12-2.2.1/bin/kafka-console-producer.sh --broker-list z-3.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-2.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181,z-1.xxxxxxxxxxxxxxx.xxxxxxxx.c4.kafka.us-east-1.amazonaws.com:2181 --replication-factor 2 --partitions 1 --topic mkc-tutorial-topic
Digite qualquer mensagem na linha de comando do EC2. Aguarde um ou dois minutos e confira o bucket de destino para ver se a mensagem foi salva nele:
Pronto: agora os dados do seu tópico estão sendo copiados para o bucket de destino que criamos. Mas, durante uma indisponibilidade de uma região da AWS, esses dados não vão estar acessíveis. Por isso, é fundamental configurar a replicação do bucket de produção de destino (por exemplo, us-east-1) para o bucket na sua região de DR (us-west-2), seguindo a documentação da AWS no link acima.