クエリ処理を高速化し、コストを抑えたいなら、ここで紹介する8つのよくあるミスを避けましょう。

BigQueryクエリの処理時間とコストを抑えるには
BigQueryで「より少ないコストでより多くの成果を出す」ためには、クエリを書くときにありがちなミスを把握しておくことが欠かせません。処理時間を短縮し、コストを抑えるには、次の8つのよくあるミスを避けましょう。
1. SELECT *
SELECT *は、BigQueryのクエリで不要なコストを発生させる最大の要因と言ってもよいでしょう。
テーブルやビューの全列を選択するということは、たいていの場合、必要のないデータまでスキャンしているということです。SELECT \*を使ってもよいケースもいくつかあります。たとえば、すでにビューでフィルタ済みの場合、Common-Table-Expression (CTE) で必要なデータに絞り込んでいる場合、あるいはすべての列が必要となる小規模なテーブル(ファクトテーブルなど)を扱う場合です。
それ以外の場面で_SELECT_ \*を実行すると、BigQueryの請求額がふくらむだけです。オンデマンド料金モデルでは、BigQueryの料金はクエリでスキャンしたデータ量に応じて課金されるためです。
たとえば、5列に均等にデータが格納された5TBのテーブルに対して_SELECT_ *を実行し、全列をスキャンしなければならない場合、そのクエリのコストは$25になります。一方、必要な2列だけに対して_SELECT_ \*を実行するクエリならわずか$10で済みます。1日に何度も実行するクエリなら、コストはあっという間に積み上がります。
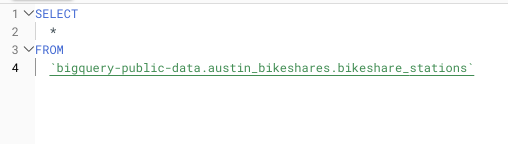
非常に大規模な公開データセットに対してSELECT *を実行した例
2. 不要な結合や大きすぎる結合
OLAP指向のデータウェアハウス(BigQueryなど)では、データベースのスキーマを非正規化してデータ構造をフラットにし、従来のリレーショナルデータベースに比べて結合の回数を最小限に抑えることが推奨されています。基盤となるシステムでのデータの格納方式の都合上、BigQueryでの結合処理は従来型データベースに比べてはるかに低速だからです。大きなテーブル同士を結合すれば、必要なデータ(またはそのコピー)を同じテーブルに持っておく場合に比べて当然ながら時間がかかり、スキャンするデータ量も増えます。
「自己結合」も避けるべきです。自己結合は、テーブルのデータを時間ウィンドウに分割したり、重複行に内部的な順序付け(多くのデータベースシステムで「ランキング」と呼ばれる処理)を行ったりする際に必要になることがあります。これは非常に低速なので、代わりにBigQueryが提供するウィンドウ関数や分析関数を使いましょう。
以下は、INFORMATION_SCHEMAビューで重複するジョブIDをランキングする例です。
SELECT query, job_id AS jobId, COALESCE(total_bytes_billed, 0) AS totalBytesBilled, ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnkFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT3. クロス結合
クロス結合は、ソフトウェアエンジニアリング出身でRDBMSを扱ってきた人なら通常は使わないものですが、BigQueryではいくつかの場面で必要になります。代表的な用途は、配列を行に展開する(unnestする)処理で、分析データを扱う際にはかなり一般的な操作です。
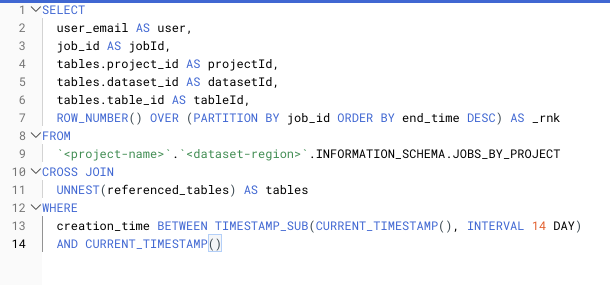
CROSS JOINでRECORD型の列をunnestする例
ただし、クロス結合をクエリの最も内側の処理として使うと、最終的に出力されるデータより_はるかに_多くのデータが取り込まれてしまい、後続の処理で破棄される可能性のある大量のデータをスキャン・読み込みするコストまでBigQueryから請求されることになります。クロス結合は、可能な限りクエリの外側で行い、その前に読み込むデータ量を最小限にしましょう。スロット消費量と課金対象データ量の両方を削減できます。
4. Common Table Expressions (CTEs) の誤った使い方
Common Table Expressions (CTEs) は、サブクエリが何階層にも入れ子になったSQLコードを整理するのに非常に便利です。一般にはパフォーマンスではなく可読性のために使われ、データを実体化(マテリアライズ)せず、複数回参照するとそのつど再実行されます。私がよく目にする最大のコスト・パフォーマンス問題は、1つのクエリの中でCTEを定義し、それを何度も参照しているケースです。CTEのクエリが参照のたびに実行されるため、データの読み取りに対して何度も課金されてしまいます。
5. WHERE句でパーティションを使わない
パーティションは、コスト削減と読み取り性能の最適化において、BigQueryでも特に重要な機能の一つです。それにもかかわらず指定漏れが多く、無駄なクエリコストの発生源になっています。パーティションは、特定の列の整数値またはtimestamp/datetime/date値に基づいて、テーブルをディスク上で物理的に分割するしくみです。パーティション化されたテーブルからその列で範囲を指定して読み取れば、テーブル全体ではなく、その範囲のデータが含まれるパーティションだけをスキャンすれば済みます。
以下のクエリは、過去14日間のすべてのクエリの請求対象バイト数の合計を取得します。_JOBS_BY_PROJECT_は_creation_time_列でパーティション化されており(スキーマのドキュメントはこちら)、合計サイズ約17GBのサンプルテーブルに対して実行すると、処理されるデータ量は884 MBになります。
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()次のクエリは_start_time_列を使っています。これはパーティション化されていない列ですが、通常は_creation_time_とほぼ同じ時刻(コンマ数秒以内)になります。同じサンプルデータセットに対して実行すると、処理されるデータ量は15 GBになります。テーブル全体をスキャンして該当する値を取り出しているためです。
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()小規模なデータセットでも差は歴然です。1つ目のクエリのコストは約$0.004、2つ目は約$0.75。パーティション列を正しく使わないだけで、コストはおよそ21倍にふくらむ計算になります。
パフォーマンスにも影響があり、1つ目のクエリは約2秒で完了するのに対し、2つ目は約5秒かかります。数TB規模のテーブルに拡大すれば、クエリ1回あたり数分単位の差が出ることも珍しくありません。
6. 複雑すぎるビューの使用
多くの擬似リレーショナル/リレーショナルデータベースと同じく、BigQueryにもビューという構文があります。ビューとは、要するに「結果をテーブルのように見せてクエリしやすくするクエリ」です。ビューに非常に重い計算処理が含まれていて、ビューを参照するたびにそれが実行される場合、クエリのパフォーマンスは大きく低下しかねません。ビュー内のロジックが過度に複雑な場合は、別テーブルに事前計算した結果を持たせるか、マテリアライズドビューに移行してパフォーマンスを高める方が適していることもあります。
7. 小さなインサート
BigQueryはまとまった量のデータを一度に処理することに向いていますが、ストリーミング系のアプリケーションなどでは、少数のレコードをテーブルに挿入したい場面もあります。
小さなインサートの場合、1KBの挿入でも10MBの挿入でも、所要時間やスロット使用量はそれほど変わりません。1KBの行を1,000回挿入すると、10MB分の行を1回で挿入する場合に比べてスロット消費時間が最大1,000倍に達することもあります。小さなインサートを何度も行うのではなく、データをまとめてバッチで挿入しましょう。ストリーミング処理でも同様で、Streaming insertsを使うのではなく、到着期限を設けてデータをバッチ化してから挿入するのがおすすめです。
8. DMLステートメントの使いすぎ
これは、BigQueryを従来型のRDBMSと同じ感覚で扱い、データを気軽に作り直そうとする際によく起こる大きな問題です。
比較的よく見かける例を3つ挙げます。
DELETE TABLE <table-name> IF EXISTS;CREATE TABLE <table-name> ...;INSERT INTO <table-name> (<columns>) VALUES (<values>);TRUNCATE TABLE <table-name>;INSERT INTO <table-name> (<columns>) VALUES (<values>);DELETE FROM TABLE <table-name> WHERE <condition>;INSERT INTO <table-name> (<columns>) VALUES (<values>);これらはSQL ServerやMySQLなどのRDBMSで実行すれば比較的軽い処理ですが、BigQueryではパフォーマンスが大きく低下します。BigQueryは従来型RDBMSのようにDMLステートメント向けに最適化されていないため、代わりに「追加型モデル」の採用を検討しましょう。このモデルでは、最新であることを示すタイムスタンプを付けて新しい行を追加し、履歴が不要であれば古い行を定期的に削除します。
BigQueryは分析向けにチューニングされたデータウェアハウスであり、トランザクション的にデータを書き換えるのではなく、すでにあるデータを扱うことを前提に設計されています。
次のステップ
本記事は、筆者のBigQueryクエリ最適化に関する連載記事を凝縮したものです。
DoiTは、BigQueryをはじめ、機械学習やビジネスインテリジェンスの領域で幅広く深い知見を有しています。サポートが必要な方は、お問い合わせください。