Pour accélérer le traitement de vos requêtes et en réduire le coût, évitez ces huit erreurs courantes.

Comment gagner du temps et de l'argent sur le traitement de vos requêtes BigQuery
Pour dépenser moins et tirer davantage de BigQuery, il faut savoir repérer les erreurs fréquentes commises lors de l'écriture des requêtes. Pour accélérer le traitement de vos requêtes et en réduire le coût, voici huit erreurs courantes à éviter :
1. SELECT *
Le SELECT * est probablement la principale source de coûts supplémentaires inutiles dans les requêtes BigQuery.
Lorsque vous sélectionnez toutes les colonnes d'une table ou d'une vue, vous scannez généralement bien plus de données que nécessaire. Un SELECT \* peut se justifier dans quelques cas : lorsque vous avez déjà filtré une vue, lorsque vous avez utilisé une Common-Table-Expression (CTE) pour réduire le volume de données nécessaires, ou lorsque vous travaillez sur une petite table dont toutes les données sont utiles (par exemple une table de faits).
Dans tous les autres cas, exécuter un SELECT \* sur vos données ne fait qu'alourdir votre facture BigQuery, puisque celle-ci repose sur le volume de données scannées en mode tarification à la demande.
Par exemple, sur une table de 5 To comportant cinq colonnes de volumes équivalents, qu'il faut entièrement scanner, un SELECT * coûtera 25 $, tandis qu'une requête limitée aux deux colonnes nécessaires via un SELECT \* ne coûtera que 10 $. La facture grimpe vite pour des requêtes lancées plusieurs fois par jour.
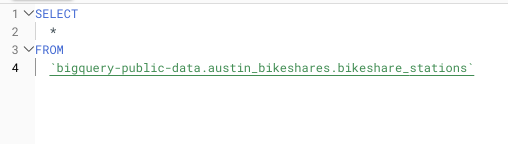
Exemple d'utilisation d'un SELECT * sur une requête portant sur un très grand jeu de données public
2. Jointures inutiles ou trop volumineuses
Pour les entrepôts de données orientés OLAP (comme BigQuery), il est recommandé de dénormaliser les schémas afin d'aplatir les structures de données et de limiter le nombre de jointures par rapport à une base relationnelle classique. En effet, une jointure est nettement plus lente dans BigQuery que dans une base traditionnelle, du fait du mode de stockage des données dans le système sous-jacent. Joindre de grandes tables prend évidemment plus de temps et scanne davantage de données que de stocker simplement les données utiles (ou une copie) dans la même table.
Évitez également la self-join, qui consiste à découper les données d'une table en fenêtres temporelles ou à ordonner en interne les lignes dupliquées (le ranking dans de nombreux SGBD). C'est une opération extrêmement lente : utilisez plutôt les fonctions de fenêtre ou analytiques proposées par BigQuery.
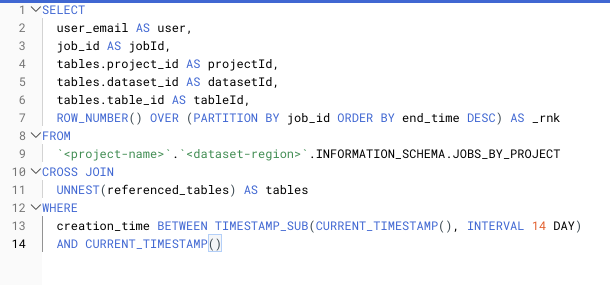
Voici un exemple de classement des job IDs en doublon dans votre vue INFORMATION_SCHEMA :
SELECT query, job_id AS jobId, COALESCE(total_bytes_billed, 0) AS totalBytesBilled, ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnkFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT3. Cross joins
Les cross joins ne sont pas une opération que privilégierait spontanément un développeur issu d'un Relational Database Management System (RDBMS), mais elles s'imposent dans plusieurs cas d'usage propres à BigQuery. Le principal : le dépliage (unnesting) de tableaux en lignes — une opération relativement courante sur des données analytiques.
Exemple de dépliage d'une colonne de type RECORD à l'aide d'un CROSS JOIN
En revanche, si vous placez un cross join comme opération la plus interne de votre requête, il chargera bien plus de données qu'il n'en transmettra en sortie, ce qui amène BigQuery à vous facturer la lecture et le scan de volumes qui seront écartés plus tard dans la requête. Effectuez plutôt vos cross joins au point le plus externe possible afin de réduire le volume de données lues en amont. Vous y gagnerez sur le nombre de slots et sur le volume facturé.
4. Mauvaise utilisation des Common Table Expressions (CTE)
Les Common Table Expressions (CTE) sont précieuses pour structurer du code SQL qui s'enfonce dans plusieurs niveaux de sous-requêtes. Utilisées en général pour la lisibilité plus que pour la performance, elles ne matérialisent pas les données et sont ré-exécutées à chaque appel. Le principal problème de coût et de performance que je rencontre est l'utilisation d'une CTE référencée plusieurs fois dans une même requête : la requête de la CTE est alors exécutée plusieurs fois, et la lecture des données vous est facturée à chaque exécution.
5. Ne pas utiliser les partitions dans les clauses WHERE
Les partitions comptent parmi les fonctionnalités les plus importantes de BigQuery pour réduire les coûts et optimiser les performances de lecture, mais elles sont fréquemment oubliées, ce qui entraîne des dépenses inutiles. Une partition découpe une table sur le disque en plusieurs partitions physiques, sur la base d'une valeur entière ou de type timestamp/datetime/date d'une colonne donnée. Ainsi, lorsque vous lisez une table partitionnée et que vous précisez une plage sur cette colonne, seules les partitions contenant les données de cette plage sont scannées — et non la table entière.
La requête suivante récupère le total des octets facturés pour toutes les requêtes des 14 derniers jours. La table JOBS_BY_PROJECT est partitionnée sur la colonne creation_time (la documentation du schéma est disponible ici) et, exécutée sur une table d'environ 17 Go, elle traite 884 Mo de données.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()La requête suivante s'appuie sur la colonne start_time, qui n'est pas partitionnée mais reste généralement à une fraction de seconde de la valeur creation_time. Sur le même jeu de données, elle traite 15 Go : elle scanne en effet l'intégralité de la table pour en extraire les valeurs demandées.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()Le contraste est saisissant, même sur un petit jeu de données : la première requête coûte environ 0,004 $ et la seconde environ 0,75 $. Mal exploiter une colonne partitionnée revient donc à payer près de 21 fois plus cher.
Les performances aussi sont en jeu : la première requête s'exécute en deux secondes environ, la seconde en cinq. À l'échelle d'une table de plusieurs To, l'écart peut facilement atteindre plusieurs minutes par exécution.
6. Recourir à des vues trop complexes
Comme la plupart de ses cousins pseudo- ou réellement relationnels, BigQuery prend en charge la notion de vue. Une vue est essentiellement une requête dont les résultats sont présentés comme une table pour en faciliter l'interrogation. Si la vue contient des calculs très lourds rejoués à chaque appel, les performances de la requête peuvent s'en trouver fortement dégradées. Lorsque la logique d'une vue est trop complexe, mieux vaut souvent la précalculer dans une autre table ou la basculer dans une vue matérialisée pour gagner en performance.
7. Petites insertions
BigQuery est conçu pour traiter de gros volumes de données à la fois, mais il est parfois nécessaire d'insérer un petit nombre d'enregistrements dans une table, notamment dans certaines applications de type streaming.
Pour les petites insertions, insérer 1 Ko ou 10 Mo prend en général un temps et un usage de slots comparables. Réaliser 1 000 insertions d'une ligne de 1 Ko peut consommer jusqu'à 1 000 fois plus de temps de slot qu'une seule insertion de 10 Mo de lignes. Plutôt que de multiplier les petites insertions, regroupez les données et insérez-les par lots. Le même principe s'applique au streaming : au lieu d'utiliser des Streaming inserts, regroupez vos données avant de les insérer en respectant un délai d'arrivée.
8. Abus des instructions DML
C'est un problème majeur, qui survient généralement lorsque l'on aborde BigQuery comme un RDBMS traditionnel et que l'on recrée les données à volonté.
Voici trois exemples relativement courants :
DELETE TABLE <table-name> IF EXISTS;CREATE TABLE <table-name> ...;INSERT INTO <table-name> (<columns>) VALUES (<values>);TRUNCATE TABLE <table-name>;INSERT INTO <table-name> (<columns>) VALUES (<values>);DELETE FROM TABLE <table-name> WHERE <condition>;INSERT INTO <table-name> (<columns>) VALUES (<values>);Si l'exécution de ces instructions sur un RDBMS comme SQL Server ou MySQL reste relativement peu coûteuse, leurs performances sont médiocres dans BigQuery. Ce dernier n'est pas optimisé pour les instructions DML comme l'est un RDBMS traditionnel : envisagez plutôt un modèle additif. Dans ce modèle, les nouvelles lignes sont insérées avec un timestamp signalant la version la plus récente, et les anciennes sont supprimées périodiquement si l'historique n'est pas nécessaire.
BigQuery est un entrepôt de données pensé pour l'analytique : il est conçu pour exploiter des données existantes, pas pour les modifier de manière transactionnelle.
Et maintenant ?
Cet article est une version condensée de ma série d'articles consacrée à l'optimisation de vos requêtes BigQuery.
Chez DoiT, nous disposons d'une expertise approfondie et étendue sur BigQuery, ainsi que dans les domaines du machine learning et de la business intelligence. Pour bénéficier de notre accompagnement, contactez-nous.