Para acelerar o processamento das suas queries e reduzir os custos envolvidos, evite estes oito erros comuns.

Como economizar tempo e dinheiro ao processar suas queries no BigQuery
Gastar menos e fazer mais com o BigQuery passa por reconhecer alguns erros recorrentes que as pessoas cometem ao escrever queries. Para acelerar o processamento e reduzir os custos, fuja destes oito erros comuns:
1. SELECT *
O SELECT * é provavelmente a maior fonte de custos extras desnecessários em queries do BigQuery.
Quando você seleciona todas as colunas de uma tabela ou view, normalmente está só varrendo dados em excesso. Em alguns casos, o SELECT \* faz sentido: quando você já filtrou a view, quando usou uma Common-Table-Expression (CTE) para reduzir o conjunto de dados ou quando tem uma tabela pequena cujos dados são todos necessários (como uma tabela de fatos).
Fora dessas situações, rodar um SELECT \* nos seus dados só infla a sua conta do BigQuery, já que a cobrança no modelo on-demand é baseada no volume de dados varridos pelas queries.
Por exemplo, se você executar um SELECT * em uma tabela de 5TB com cinco colunas de volumes iguais de dados, todas precisarão ser varridas, e essa query vai custar US$ 25. Já uma query com SELECT \* apenas nas duas colunas de que você precisa custaria só US$ 10. A conta cresce rápido quando a query roda várias vezes por dia.
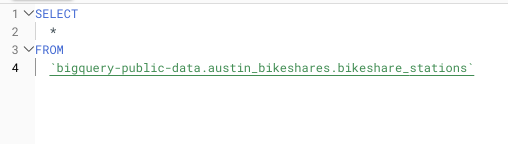
Exemplo de uso de SELECT * em uma query sobre um dataset público muito grande
2. Joins desnecessários ou maiores do que o preciso
Em data warehouses voltados para uma estratégia OLAP (como o BigQuery), o recomendado é desnormalizar os schemas do banco para achatar as estruturas de dados e reduzir o número de joins necessários, ao contrário do que se faz em um banco relacional tradicional. Isso porque uma operação de join é bem mais lenta no BigQuery do que em um banco tradicional, por causa de como os dados são armazenados no sistema subjacente. Fazer join de tabelas grandes leva mais tempo e varre mais dados do que simplesmente manter os dados necessários (ou uma cópia) na mesma tabela.
Você também deve evitar o "self-join", em que os dados da tabela podem precisar ser separados em janelas de tempo ou ganhar uma ordenação interna em linhas duplicadas (chamada de ranking em muitos sistemas de banco de dados). É algo extremamente lento, então prefira as funções de janela ou analíticas oferecidas pelo BigQuery.
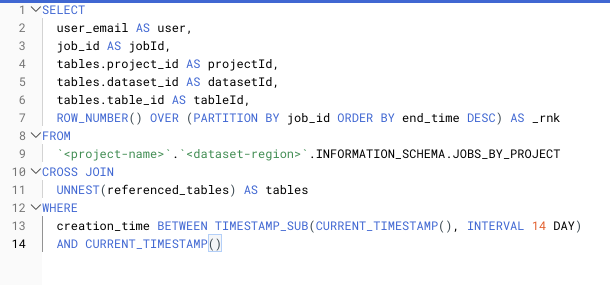
Veja um exemplo de ranking de IDs de jobs duplicados na sua view INFORMATION_SCHEMA:
SELECT query, job_id AS jobId, COALESCE(total_bytes_billed, 0) AS totalBytesBilled, ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnkFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT3. Cross joins
Cross joins não são algo que alguém com experiência em engenharia de software vindo de um Relational Database Management System (RDBMS) costuma usar, mas são necessários em várias situações no BigQuery. O principal caso de uso é desaninhar arrays em linhas — uma operação bem comum no trabalho com dados analíticos.
Exemplo de desaninhamento de uma coluna do tipo RECORD usando um CROSS JOIN
No entanto, se você usar cross joins como a operação mais interna da query, eles puxam muito mais dados do que será entregue na saída, e o BigQuery acaba cobrando para varrer e ler um monte de dados que pode ser descartado em uma fase posterior. Em vez disso, faça os cross joins no ponto mais externo possível da sua query, para reduzir o volume de dados lidos antes da operação. Isso diminui a contagem de slots e o volume de dados pelo qual você paga.
4. Usar Common Table Expressions (CTEs) de forma incorreta
As Common Table Expressions (CTEs) são ótimas para quebrar código SQL que está descendo por vários níveis de subqueries. Em geral, são usadas em prol da legibilidade, e não da performance: elas não materializam os dados e são executadas novamente cada vez que aparecem na query. O maior problema de custo e performance que vejo é referenciar a mesma CTE várias vezes em uma query. A CTE acaba sendo executada de novo a cada referência, e você é cobrado por ler os dados várias vezes.
5. Não usar partições nas cláusulas WHERE
Embora as partições estejam entre os recursos mais importantes do BigQuery para reduzir custos e otimizar a performance de leitura, elas costumam ser esquecidas, gerando gastos desnecessários nas queries. Uma partição divide a tabela em disco em diferentes partições físicas, com base em um valor inteiro ou de timestamp/datetime/date em uma coluna específica. Assim, ao ler dados de uma tabela particionada e especificar um intervalo nessa coluna, o BigQuery só precisa varrer as partições que contêm os dados daquele intervalo — e não a tabela inteira.
A query a seguir traz o total de bytes cobrados em todas as queries dos últimos 14 dias. A JOBS_BY_PROJECT é particionada pela coluna creation_time (a documentação do schema está aqui) e, ao rodar contra uma tabela de exemplo com cerca de 17GB no total, processa 884 MB de dados.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()A query abaixo é executada usando a coluna start_time, que não é particionada, mas costuma ficar a frações de segundo do valor de creation_time. No mesmo dataset de exemplo, ela processa 15 GB de dados — a lógica é que precisa varrer a tabela inteira para extrair os valores pedidos.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()O contraste é gritante, mesmo em um dataset menor: como a primeira query custa cerca de US$ 0,004 e a segunda cerca de US$ 0,75, deixar de aproveitar uma coluna particionada sai aproximadamente 21 vezes mais caro.
A performance também sofre: a primeira query leva cerca de dois segundos para rodar; a segunda, cerca de cinco. Em uma tabela de múltiplos TB, a diferença pode chegar facilmente a vários minutos por execução.
6. Usar views complicadas demais
Como a maioria dos seus parentes pseudo e de fato relacionais, o BigQuery suporta uma estrutura chamada view. Em essência, uma view é uma query que se apresenta como tabela para facilitar consultas. Se ela contém cálculos muito pesados, executados toda vez que é consultada, a performance da query pode cair bastante. Quando a lógica da view é excessivamente complicada, talvez faça mais sentido pré-calcular os dados em outra tabela ou usar uma materialized view para ganhar performance.
7. Inserts pequenos
O BigQuery brilha ao processar grandes volumes de dados de uma vez, mas, em alguns casos, é preciso inserir poucos registros em uma tabela — especialmente em algumas aplicações de streaming.
Para inserts pequenos, inserir 1KB ou 10MB tende a consumir tempo e slots parecidos. Fazer 1.000 inserts de uma linha de 1KB pode consumir até 1.000 vezes mais tempo de slot do que um único insert de 10MB de linhas. Em vez de vários inserts pequenos, agrupe os dados e insira em lote. O mesmo vale para operações de streaming: em vez de usar Streaming inserts, agrupe seus dados antes de inseri-los, com um prazo de chegada definido.
8. Abusar de instruções DML
Esse é um problema grande que costuma aparecer quando alguém encara o BigQuery como um RDBMS tradicional e fica recriando dados à vontade.
Veja três exemplos relativamente comuns:
DELETE TABLE <table-name> IF EXISTS;CREATE TABLE <table-name> ...;INSERT INTO <table-name> (<columns>) VALUES (<values>);TRUNCATE TABLE <table-name>;INSERT INTO <table-name> (<columns>) VALUES (<values>);DELETE FROM TABLE <table-name> WHERE <condition>;INSERT INTO <table-name> (<columns>) VALUES (<values>);Em um RDBMS como SQL Server ou MySQL, rodar isso seria uma operação relativamente barata, mas no BigQuery a performance é muito ruim. Ele não é otimizado para instruções DML do mesmo jeito que um RDBMS tradicional, então considere adotar um "modelo aditivo". Nele, novas linhas são inseridas com um timestamp para indicar a versão mais recente, e as linhas mais antigas são removidas periodicamente, caso o histórico não seja necessário.
O BigQuery é um data warehouse calibrado para analytics, ou seja, foi pensado para trabalhar com dados existentes, não para modificá-los de forma transacional.
Próximos passos
Este artigo é uma versão condensada da minha série de artigos sobre como otimizar suas queries no BigQuery.
Na DoiT, temos expertise profunda e ampla em BigQuery, além das áreas de machine learning e business intelligence. Para contar com o nosso apoio, entre em contato.