Wer seine Abfragen beschleunigen und die damit verbundenen Kosten senken möchte, sollte diese acht typischen Fehler vermeiden.

So sparen Sie Zeit und Geld bei BigQuery-Abfragen
Wer mit BigQuery mehr erreichen und gleichzeitig weniger ausgeben möchte, sollte die häufigsten Fehler beim Schreiben von BigQuery-Abfragen kennen. Wer seine Abfragen beschleunigen und Kosten senken will, sollte diese acht typischen Fehler vermeiden:
1. SELECT *
SELECT * ist wahrscheinlich die größte Quelle unnötiger Zusatzkosten bei BigQuery-Abfragen.
Wenn Sie alle Spalten einer Tabelle oder View auswählen, scannen Sie in der Regel schlicht überflüssige Daten. In wenigen Fällen kann ein SELECT \* dennoch sinnvoll sein – etwa wenn Sie eine View bereits gefiltert, mit einer Common-Table-Expression (CTE) die benötigte Datenmenge reduziert haben oder eine kleine Tabelle vorliegt, deren gesamter Inhalt benötigt wird (zum Beispiel eine Faktentabelle).
Andernfalls treibt ein SELECT \* auf Ihre Daten schlicht Ihre BigQuery-Rechnung in die Höhe, denn BigQuery rechnet im On-Demand-Preismodell nach dem Datenvolumen ab, das Ihre Abfragen scannen.
Ein Beispiel: Führen Sie ein SELECT *auf einer 5-TB-Tabelle mit fünf Spalten aus, die jeweils gleich viele Daten enthalten und alle gescannt werden müssen, kostet diese Abfrage 25 USD. Eine Abfrage mit SELECT \* auf nur die zwei tatsächlich benötigten Spalten käme dagegen auf lediglich 10 USD. Bei mehrfach täglich ausgeführten Abfragen summiert sich das schnell.
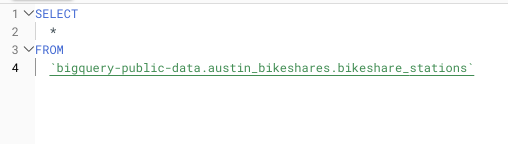
Beispiel für ein SELECT * auf einer sehr großen öffentlichen Dataset-Abfrage
2. Unnötige oder zu große Joins
Bei Data Warehouses mit OLAP-Fokus (wie BigQuery) ist es ratsam, die Schemas der Datenbank zu denormalisieren, um Datenstrukturen zu verflachen und die Anzahl nötiger Joins gegenüber einer klassischen relationalen Datenbank zu minimieren. Der Grund: Eine Join-Operation ist in BigQuery deutlich langsamer als in einer klassischen Datenbank – das liegt daran, wie die Daten im zugrunde liegenden System gespeichert werden. Große Tabellen zu joinen dauert naturgemäß länger und scannt mehr Daten, als die benötigten Werte (oder eine Kopie davon) gleich in derselben Tabelle vorzuhalten.
Vermeiden Sie auch den sogenannten "Self-Join", bei dem Daten aus einer Tabelle in Zeitfenster zerlegt oder doppelte Zeilen intern sortiert werden müssen (in vielen Datenbanksystemen Ranking genannt). Das ist extrem langsam – greifen Sie stattdessen zu den von BigQuery bereitgestellten Window- bzw. Analytischen Funktionen.
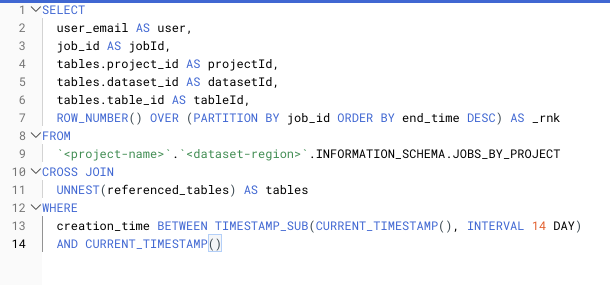
Hier ein Beispiel für das Ranking doppelter Job-IDs in Ihrer INFORMATION_SCHEMA-View:
SELECT query, job_id AS jobId, COALESCE(total_bytes_billed, 0) AS totalBytesBilled, ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnkFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT3. Cross Joins
Cross Joins setzt kaum jemand mit klassischem Software-Engineering-Hintergrund aus einem Relational Database Management System (RDBMS) regelmäßig ein – in BigQuery sind sie jedoch für mehrere Anwendungsfälle nötig. Hauptanwendungsfall ist das Auflösen von Arrays in Zeilen (Unnesting) – eine recht häufige Operation bei der Arbeit mit analytischen Daten.
Beispiel für das Unnesting einer RECORD-typisierten Spalte mittels CROSS JOIN
Setzen Sie Cross Joins jedoch als innerste Operation Ihrer Abfrage ein, ziehen sie weit mehr Daten heran, als am Ende ausgegeben werden – BigQuery stellt Ihnen dann das Scannen und Lesen großer Datenmengen in Rechnung, die in einer späteren Phase der Abfrage ohnehin verworfen werden. Führen Sie Cross Joins stattdessen so weit wie möglich außen in der Abfrage aus, um die vor dem Cross Join gelesene Datenmenge gering zu halten. Das senkt Ihren Slot-Verbrauch und das Datenvolumen, für das Sie zahlen.
4. Common Table Expressions (CTEs) falsch eingesetzt
Common Table Expressions (CTEs) eignen sich hervorragend, um SQL-Code aufzubrechen, der sich in mehreren Ebenen von Subqueries verliert. Sie dienen meist der Lesbarkeit, nicht der Performance: Sie materialisieren die Daten nicht und werden bei jeder Verwendung erneut ausgeführt. Das größte Kosten- und Performance-Problem entsteht, wenn ein CTE in einer Abfrage mehrfach referenziert wird. Die CTE-Abfrage läuft dann mehrfach – und das Lesen der Daten wird Ihnen entsprechend mehrfach berechnet.
5. Keine Partitionen in WHERE-Klauseln
Obwohl Partitionen zu den wichtigsten BigQuery-Funktionen für Kostensenkung und Lese-Performance gehören, werden sie häufig weggelassen – mit unnötigen Mehrkosten als Folge. Eine Partition unterteilt eine Tabelle auf der Festplatte anhand eines Integer- oder Timestamp-/Datetime-/Date-Werts in einer bestimmten Spalte in mehrere physische Partitionen. Lesen Sie Daten aus einer partitionierten Tabelle und geben Sie einen Bereich auf dieser Spalte an, müssen nur die Partitionen gescannt werden, die Daten in diesem Bereich enthalten – nicht die ganze Tabelle.
Die folgende Abfrage ermittelt die insgesamt abgerechneten Bytes aller Abfragen der letzten 14 Tage. JOBS_BY_PROJECT ist nach der Spalte creation_time partitioniert (Schemadokumentation hier). Auf eine Beispieltabelle mit einer Gesamtgröße von etwa 17 GB angewendet, verarbeitet sie 884 MB an Daten.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()Die folgende Abfrage nutzt die Spalte start_time, die nicht partitioniert ist, aber meist nur Sekundenbruchteile vom creation_time-Wert abweicht. Auf demselben Beispieldatensatz verarbeitet sie 15 GB an Daten – sie scannt also die gesamte Tabelle, um die angeforderten Werte herauszuziehen.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()Der Unterschied ist selbst bei einem kleineren Datensatz drastisch: Während die erste Abfrage rund 0,004 USD kostet, schlägt die zweite mit etwa 0,75 USD zu Buche – ohne richtig genutzte Partitionsspalte zahlen Sie also rund das 21-Fache.
Auch bei der Performance gibt es deutliche Unterschiede: Die erste Abfrage läuft rund zwei Sekunden, die zweite etwa fünf. Bei Tabellen im Multi-TB-Bereich können daraus pro Abfrage schnell Differenzen von mehreren Minuten werden.
6. Überkomplexe Views
Wie die meisten seiner pseudo- und echten relationalen Verwandten kennt auch BigQuery das Konstrukt der View. Im Kern ist eine View eine Abfrage, deren Ergebnis sich wie eine Tabelle abfragen lässt. Enthält die View sehr aufwendige Berechnungen, die bei jedem Zugriff erneut ausgeführt werden, kann das die Performance der Abfrage erheblich verschlechtern. Ist die Logik einer View übermäßig komplex, ist sie oft besser in einer separaten Tabelle vorberechnet oder als Materialized View aufgehoben, um die Performance zu steigern.
7. Kleine Inserts
BigQuery spielt seine Stärken aus, wenn größere Datenmengen am Stück verarbeitet werden – manchmal müssen aber dennoch wenige Datensätze in eine Tabelle eingefügt werden, etwa bei bestimmten Streaming-Anwendungen.
Bei kleinen Inserts benötigen 1 KB oder 10 MB in der Regel ähnlich viel Zeit und Slot-Nutzung. 1.000 Einfügungen einer 1-KB-Zeile können bis zum 1.000-Fachen der Slot-Nutzungszeit eines einzigen Inserts von 10 MB an Zeilen verursachen. Statt vieler kleiner Inserts sollten Sie Daten bündeln und im Batch einfügen. Gleiches gilt fürs Streaming: Statt Streaming-Inserts zu nutzen, bündeln Sie Ihre Daten besser mit einer Anlieferungsfrist und fügen sie gemeinsam ein.
8. Übermäßige Nutzung von DML-Statements
Dieses Problem tritt vor allem dann auf, wenn jemand BigQuery wie ein klassisches RDBMS behandelt und Daten nach Belieben neu erzeugt.
Drei relativ häufige Beispiele:
DELETE TABLE <table-name> IF EXISTS;CREATE TABLE <table-name> ...;INSERT INTO <table-name> (<columns>) VALUES (<values>);TRUNCATE TABLE <table-name>;INSERT INTO <table-name> (<columns>) VALUES (<values>);DELETE FROM TABLE <table-name> WHERE <condition>;INSERT INTO <table-name> (<columns>) VALUES (<values>);Auf einem RDBMS wie SQL Server oder MySQL wären diese Operationen relativ günstig – in BigQuery laufen sie dagegen sehr ineffizient. BigQuery ist nicht in gleicher Weise auf DML-Statements optimiert wie ein klassisches RDBMS. Setzen Sie stattdessen auf ein "additives Modell": Neue Zeilen werden mit einem Timestamp eingefügt, der den aktuellsten Stand kennzeichnet, und ältere Zeilen werden – sofern keine Historie benötigt wird – periodisch gelöscht.
BigQuery ist ein für Analytics ausgelegtes Data Warehouse und damit auf die Arbeit mit bestehenden Daten zugeschnitten, nicht auf transaktionale Datenänderungen.
Wie geht es weiter?
Dieser Artikel ist eine Kurzfassung meiner Artikelserie zur Optimierung Ihrer BigQuery-Abfragen.
Bei DoiT verfügen wir über tiefes und breites Know-how rund um BigQuery sowie in den Bereichen Machine Learning und Business Intelligence. Wenn Sie unsere Unterstützung nutzen möchten, nehmen Sie Kontakt mit uns auf.