Si quieres acelerar el procesamiento de tus consultas y reducir los costos asociados, evita estos ocho errores comunes.

Cómo ahorrar tiempo y dinero al procesar tus consultas en BigQuery
Para gastar menos y obtener más de BigQuery, es clave identificar algunos de los errores más comunes que se cometen al escribir consultas. Si quieres acelerar su procesamiento y reducir los costos asociados, evita estos ocho errores:
1. SELECT *
SELECT * es probablemente la mayor fuente de costos adicionales innecesarios en las consultas de BigQuery.
Cuando seleccionas todas las columnas de una tabla o vista, por lo general solo estás escaneando datos de más. Hay algunos casos en los que sí tiene sentido un SELECT \*: cuando ya filtraste una vista, cuando usaste una Common-Table-Expression (CTE) para reducir los datos necesarios o cuando tienes una tabla pequeña en la que se requieren todos los datos (como una tabla de hechos).
Fuera de esos casos, ejecutar un SELECT \* sobre tus datos solo infla tu factura de BigQuery, ya que la facturación se basa en el volumen de datos que escaneas en tus consultas cuando usas el modelo de Precios on-demand.
Por ejemplo, si ejecutas un SELECT * sobre una tabla de 5TB con cinco columnas que contienen volúmenes iguales de datos, y todas deben escanearse, esa consulta costará $25, mientras que una consulta con un SELECT \* solo sobre las dos columnas que necesitas costaría apenas $10. Los costos se acumulan rápido cuando las consultas se ejecutan varias veces al día.
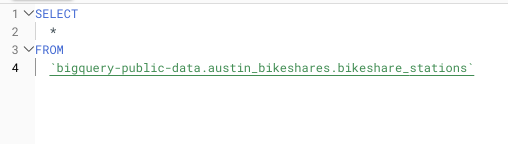
Ejemplo del uso de un SELECT * en una consulta sobre un dataset público muy grande
2. Joins innecesarios o demasiado grandes
En los data warehouses orientados a una estrategia OLAP (como BigQuery), se recomienda desnormalizar los esquemas de la base de datos para aplanar las estructuras y reducir al mínimo la cantidad de joins necesarios, a diferencia de una base de datos relacional tradicional. Esto ocurre porque una operación de join en BigQuery es mucho más lenta que en una base de datos tradicional, debido a la forma en que se almacenan los datos en el sistema subyacente. Hacer joins entre tablas grandes obviamente toma más tiempo y escanea más datos que simplemente almacenar los datos requeridos (o una copia) en la misma tabla.
También conviene evitar el "self-join", cuando los datos de la tabla deben dividirse en ventanas de tiempo o requieren un orden interno sobre filas duplicadas (lo que en muchos sistemas de bases de datos se llama ranking). Esto es extremadamente lento, así que mejor usa las window o analytic functions que ofrece BigQuery.
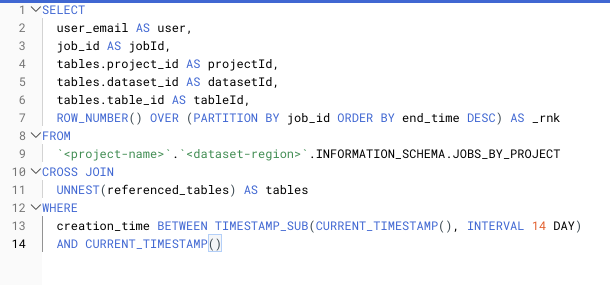
Aquí tienes un ejemplo de cómo rankear job IDs duplicados en tu vista INFORMATION_SCHEMA:
SELECT query, job_id AS jobId, COALESCE(total_bytes_billed, 0) AS totalBytesBilled, ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnkFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT3. Cross joins
Los cross joins no son algo que alguien con experiencia en ingeniería de software acostumbrado a un Relational Database Management System (RDBMS) usaría, pero en BigQuery son necesarios para varias cosas. El caso de uso principal es desanidar arrays en filas, una operación bastante común al trabajar con datos analíticos.
Ejemplo de cómo desanidar una columna de tipo RECORD usando un CROSS JOIN
Sin embargo, si usas cross joins como la operación más interna de tu consulta, traen muchísimos más datos de los que finalmente llegarán a la salida, lo que provoca que BigQuery te facture por escanear y leer un montón de datos que pueden descartarse en una fase posterior. En su lugar, ejecuta los cross joins en el punto más externo posible de tu consulta, para reducir al mínimo el volumen de datos que se leen antes del cross join. Así disminuyes la cantidad de slots y el volumen de datos por el que tienes que pagar.
4. Usar Common Table Expressions (CTEs) de forma incorrecta
Las Common Table Expressions (CTEs) son excelentes para descomponer código SQL que se enreda en múltiples niveles de subconsultas. Suelen usarse por legibilidad más que por rendimiento; no materializan los datos y se vuelven a ejecutar cada vez que se invocan. El mayor problema de costo y rendimiento que veo es usar una CTE en una consulta y referenciarla varias veces. La consulta de la CTE se ejecuta entonces múltiples veces, así que se te facturará por leer los datos varias veces.
5. No usar particiones en las cláusulas WHERE
Aunque las particiones son una de las funciones más importantes de BigQuery para reducir costos y optimizar el rendimiento de lectura, con frecuencia se omiten, lo que genera gasto innecesario en consultas. Una partición divide una tabla en disco en distintas particiones físicas, en función de un valor entero o de timestamp/datetime/date en una columna específica. Así, cuando lees datos de una tabla particionada y especificas un rango sobre esa columna, solo se escanean las particiones que contienen los datos de ese rango y no la tabla completa.
La siguiente consulta obtiene el total de bytes facturados de todas las consultas de los últimos 14 días. JOBS_BY_PROJECT está particionada por la columna creation_time (la documentación del esquema está aquí) y, al ejecutarse contra una tabla de muestra de aproximadamente 17 GB, procesa 884 MB de datos.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()La siguiente consulta usa la columna start_time, que no está particionada pero suele estar a fracciones de segundo del valor de creation_time; contra el mismo dataset de muestra, procesa 15 GB de datos. La razón es que escanea la tabla completa para extraer los valores solicitados.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()El contraste es enorme, incluso con un dataset pequeño: dado que la primera consulta cuesta unos $0.004 y la segunda alrededor de $0.75, no aprovechar correctamente una columna particionada resulta unas 21 veces más caro.
El rendimiento también se ve afectado: la primera consulta tarda unos dos segundos y la segunda alrededor de cinco. Al escalar a una tabla de varios TB, fácilmente se generarían diferencias de varios minutos por cada ejecución.
6. Usar vistas demasiado complejas
Como la mayoría de sus parientes pseudo y verdaderamente relacionales, BigQuery admite un constructo llamado vista. En esencia, una vista es una consulta que presenta sus resultados como si fueran una tabla para facilitar la consulta. Si la vista contiene cálculos muy pesados que se ejecutan cada vez que se la consulta, puede degradar de forma considerable el rendimiento. Si la lógica de una vista es demasiado complicada, conviene precalcularla en otra tabla o convertirla en una vista materializada para mejorar el rendimiento.
7. Inserts pequeños
BigQuery rinde mejor cuando procesa grandes bloques de datos a la vez, pero a veces hace falta insertar una pequeña cantidad de registros en una tabla, sobre todo en aplicaciones de tipo streaming.
En los inserts pequeños, insertar 1 KB o 10 MB suele tomar cantidades similares de tiempo y uso de slots. Hacer 1,000 inserts de una fila de 1 KB podría consumir hasta 1,000 veces más tiempo de slots que un único insert de 10 MB de filas. En lugar de ejecutar varios inserts pequeños, agrupa los datos e insértalos en lote. Lo mismo aplica para operaciones de streaming: en vez de usar Streaming inserts, agrupa tus datos antes de insertarlos con un plazo límite de llegada.
8. Abusar de las sentencias DML
Este es un problema importante que suele surgir cuando alguien aborda BigQuery como un RDBMS tradicional y recrea datos a su antojo.
Estos son tres ejemplos relativamente comunes:
DELETE TABLE <table-name> IF EXISTS;CREATE TABLE <table-name> ...;INSERT INTO <table-name> (<columns>) VALUES (<values>);TRUNCATE TABLE <table-name>;INSERT INTO <table-name> (<columns>) VALUES (<values>);DELETE FROM TABLE <table-name> WHERE <condition>;INSERT INTO <table-name> (<columns>) VALUES (<values>);Aunque ejecutar esto en un RDBMS como SQL Server o MySQL sería una operación relativamente económica, en BigQuery tienen muy mal rendimiento. BigQuery no está optimizado para sentencias DML como sí lo está un RDBMS tradicional, así que considera usar un "modelo aditivo" en su lugar. En este modelo, las nuevas filas se insertan con un timestamp que indica cuál es la más reciente, y las más antiguas se eliminan de forma periódica si no se necesita el histórico.
BigQuery es un data warehouse afinado para analítica, así que está diseñado para trabajar con datos existentes y no para modificarlos de manera transaccional.
Qué hacer ahora
Este artículo es una versión condensada de mi serie sobre cómo optimizar tus consultas en BigQuery.
En DoiT tenemos una experiencia amplia y profunda en BigQuery, así como en machine learning y business intelligence. Para aprovechar nuestro soporte, ponte en contacto.