Per velocizzare l'esecuzione delle query e contenerne i costi, conviene evitare questi otto errori ricorrenti.

Come risparmiare tempo e denaro nell'esecuzione delle query BigQuery
Per spendere meno e ottenere di più con BigQuery occorre saper riconoscere alcuni degli errori più frequenti che si commettono nella scrittura delle query. Per velocizzarne l'esecuzione e ridurne i costi, ecco gli otto errori da evitare:
1. SELECT *
SELECT * è probabilmente la principale causa di costi aggiuntivi superflui nelle query BigQuery.
Quando si selezionano tutte le colonne di una tabella o di una vista, di norma si finisce per scansionare una mole di dati eccessiva. In alcuni casi un SELECT \* può essere giustificato: ad esempio quando la vista è già stata filtrata, quando si è ricorsi a una Common-Table-Expression (CTE) per ridurre i dati necessari, oppure quando si lavora su una tabella di piccole dimensioni in cui tutti i dati servono davvero (come una tabella dei fatti).
Negli altri casi, eseguire un SELECT \* sui propri dati fa semplicemente lievitare la fattura BigQuery, perché con il modello di prezzo on-demand i costi si calcolano sul volume di dati scansionati dalle query.
Ad esempio, eseguendo un SELECT *su una tabella da 5 TB con cinque colonne di pari dimensione, da scansionare per intero, la query costa 25 dollari; la stessa query con un SELECT \* limitato alle due colonne effettivamente necessarie ne costa appena 10. Per query eseguite più volte al giorno, il conto sale in fretta.
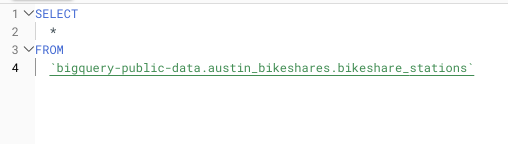
Esempio di SELECT * su una query rivolta a un dataset pubblico di grandi dimensioni
2. Join superflui o sovradimensionati
Per i data warehouse orientati a una strategia OLAP (come BigQuery) è consigliabile denormalizzare gli schemi del database per appiattire le strutture dati e ridurre al minimo il numero di join, rispetto a quanto avverrebbe in un database relazionale tradizionale. Il motivo è che in BigQuery un'operazione di join è molto più lenta che in un database tradizionale, per via del modo in cui i dati vengono memorizzati nel sistema sottostante. Unire tabelle di grandi dimensioni richiede ovviamente più tempo e scansiona più dati rispetto al semplice memorizzare i dati necessari (o una loro copia) all'interno della stessa tabella.
È inoltre opportuno evitare il "self-join", impiegato per suddividere i dati di una tabella in finestre temporali o per stabilire un ordinamento interno fra righe duplicate (operazione chiamata ranking in molti sistemi di database). Si tratta di un'operazione estremamente lenta: meglio affidarsi alle window function o funzioni analitiche messe a disposizione da BigQuery.
Ecco un esempio di ranking dei job ID duplicati nella vista INFORMATION_SCHEMA:
SELECT query, job_id AS jobId, COALESCE(total_bytes_billed, 0) AS totalBytesBilled, ROW_NUMBER() OVER(PARTITION BY job_id ORDER BY end_time DESC) AS _rnkFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECT3. Cross join
I cross join non rientrano fra gli strumenti tipici di chi proviene da un Relational Database Management System (RDBMS) con un background da software engineer, ma in BigQuery sono indispensabili in diverse situazioni. Il caso d'uso principale è l'unnesting di array in righe, un'operazione piuttosto frequente quando si lavora su dati analitici.
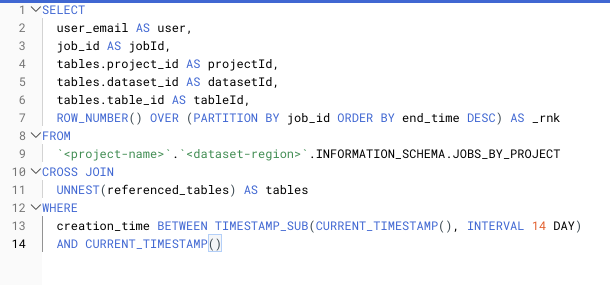
Esempio di unnesting di una colonna di tipo RECORD tramite un CROSS JOIN
Se però si usa il cross join come operazione più interna della query, vengono caricati molti più dati di quelli che finiranno nell'output: BigQuery fattura quindi la scansione e la lettura di una grande quantità di dati che potrebbero essere scartati nelle fasi successive. È preferibile spostare i cross join nel punto più esterno possibile della query, così da ridurre al minimo il volume di dati letti prima dell'operazione. In questo modo si riducono il numero di slot e i dati a pagamento.
4. Uso scorretto delle Common Table Expressions (CTE)
Le Common Table Expressions (CTE) sono ottime per spezzettare codice SQL che si addentra in più livelli di subquery. Vengono usate più per la leggibilità che per le prestazioni: non materializzano i dati e vengono rieseguite a ogni richiamo. Il problema più frequente, in termini di costi e prestazioni, è l'utilizzo di una CTE richiamata più volte all'interno della stessa query: la CTE viene rieseguita a ogni riferimento e si finisce per pagare più volte la lettura degli stessi dati.
5. Mancato uso delle partizioni nelle clausole WHERE
Le partizioni sono una delle funzionalità più importanti di BigQuery per ridurre i costi e ottimizzare le prestazioni in lettura, eppure vengono spesso ignorate, generando spese inutili. Una partizione suddivide una tabella su disco in più partizioni fisiche, sulla base di un valore intero o di tipo timestamp/datetime/date in una specifica colonna: leggendo i dati da una tabella partizionata e indicando un intervallo su quella colonna, vengono scansionate solo le partizioni che contengono i dati di quell'intervallo, non l'intera tabella.
La query seguente recupera il totale dei byte fatturati per tutte le query degli ultimi 14 giorni. JOBS_BY_PROJECT è partizionata in base alla colonna creation_time (la documentazione dello schema è disponibile qui) e, eseguita su una tabella di esempio di circa 17 GB complessivi, elabora 884 MB di dati.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()La query seguente, invece, sfrutta la colonna start_time, che non è partizionata ma di norma dista frazioni di secondo dal valore di creation_time: sullo stesso dataset di esempio elabora 15 GB di dati. Il motivo è che la query scansiona l'intera tabella per estrarne i valori richiesti.
DECLARE interval_in_days INT64 DEFAULT 14;
SELECT query, total_bytes_billed AS totalBytesBilledFROM `<project-name>`.`<dataset-region>`.INFORMATION_SCHEMA.JOBS_BY_PROJECTWHERE start_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL interval_in_days DAY) AND CURRENT_TIMESTAMP()Il divario è netto anche su un dataset di dimensioni ridotte: con la prima query che costa circa 0,004 dollari e la seconda circa 0,75 dollari, non sfruttare correttamente una colonna partizionata risulta circa 21 volte più costoso.
Anche le prestazioni ne risentono: la prima query impiega circa due secondi, la seconda circa cinque. Su una tabella di diversi TB, le differenze possono facilmente arrivare a vari minuti per ogni esecuzione.
6. Viste eccessivamente complesse
Come la maggior parte dei suoi parenti pseudo- e pienamente relazionali, BigQuery prevede un costrutto chiamato vista. In sostanza, una vista è una query che restituisce i propri risultati sotto forma di tabella, per agevolarne l'interrogazione. Se la vista contiene calcoli molto onerosi, eseguiti a ogni interrogazione, le prestazioni della query possono peggiorare in modo sensibile. Quando la logica di una vista è eccessivamente complessa, conviene piuttosto pre-calcolarla in un'altra tabella o trasformarla in una vista materializzata, per migliorarne le prestazioni.
7. Inserimenti di piccole dimensioni
BigQuery dà il meglio di sé elaborando blocchi consistenti di dati alla volta, ma a volte è necessario inserire un numero ridotto di record in una tabella, soprattutto in alcune applicazioni di tipo streaming.
Per i piccoli inserimenti, scrivere 1 KB o 10 MB richiede in genere tempi e utilizzo di slot analoghi. Eseguire 1.000 inserimenti di una riga da 1 KB può consumare fino a 1.000 volte il tempo di slot di un singolo inserimento da 10 MB. Anziché ripetere tanti piccoli inserimenti, conviene raggruppare i dati e inserirli in batch. Lo stesso vale per le operazioni di streaming: invece di affidarsi agli Streaming insert, è meglio aggregare i dati prima dell'inserimento, fissando una scadenza di arrivo.
8. Uso eccessivo delle istruzioni DML
È un problema rilevante, che emerge tipicamente quando si approccia BigQuery come un RDBMS tradizionale e si ricreano i dati a piacimento.
Ecco tre esempi piuttosto comuni:
DELETE TABLE <table-name> IF EXISTS;CREATE TABLE <table-name> ...;INSERT INTO <table-name> (<columns>) VALUES (<values>);TRUNCATE TABLE <table-name>;INSERT INTO <table-name> (<columns>) VALUES (<values>);DELETE FROM TABLE <table-name> WHERE <condition>;INSERT INTO <table-name> (<columns>) VALUES (<values>);Su un RDBMS come SQL Server o MySQL queste operazioni sono relativamente poco costose, ma in BigQuery hanno prestazioni decisamente scarse. BigQuery non è ottimizzato per le istruzioni DML come lo è un RDBMS tradizionale: meglio adottare un "modello additivo". In questo modello le nuove righe vengono inserite con un timestamp che ne indica l'ultima versione, mentre le righe più vecchie vengono eliminate periodicamente se non serve mantenere lo storico.
BigQuery è un data warehouse pensato per l'analisi: è progettato per lavorare su dati esistenti, non per modificarli in modo transazionale.
I prossimi passi
Questo articolo è una sintesi della mia serie di approfondimenti sull'ottimizzazione delle query BigQuery.
In DoiT mettiamo a disposizione un'expertise ampia e approfondita su BigQuery, oltre che nel machine learning e nella business intelligence. Per richiedere il nostro supporto, contattaci.