
Cloud Dataproc は、Apache Spark と Apache Hadoop のクラスタを、シンプルかつ低コストで動かせるフルマネージドのクラウドサービスです。立ち上げが驚くほど速く、使い勝手も抜群。これまで数時間〜数日かかっていた処理が数秒〜数分で終わり、課金も秒単位で、使った分だけを支払えば済みます。
Google Cloud Dataproc クラスタはいつでもサイズ変更が可能で、3 ノードから数百ノードまで自在にスケールできます。データパイプラインがクラスタのリソースを食いつぶす心配もありません。クラスタ起動後でも、手動でスケールアップ/ダウンが可能です。
とはいえ、workloads が必要とするリソース量が時間によって変動する場合は、クラスタを継続的に監視し、ワーカーを手動で追加・削減すべきかを判断しなければなりません。さらに通常は、コンピュートコストを抑えるために、ワーカーの一部を preemptible インスタンスとして動かしたいところでしょう。
そこで登場するのが Shamash です。Shamash は、単一プロジェクト内の複数の Google Dataproc クラスタを監視し、自動でスケーリングできるオープンソースのオートスケーリングシステムです。
Shamash は、バビロニアおよびアッシリアにおける正義の神。コストとパフォーマンスのバランスを取ることを役割とする、Shamash オートスケーラーにぴったりの名前です。
Shamash には次のような要件がありました。
- 管理負担を減らすため、サーバーレスで動作すること
- 複数クラスタに対応し、それぞれ個別のオートスケーリング設定を持てること
- 標準の Dataproc イメージとクラスタで動作すること
- 運用コストを抑えるため preemptible ワーカーをサポートすること
- Shamash 自体の運用コストが低いこと
そこで Shamash を Google App Engine の Standard Environment 上で動かすことに決めました。これだけで以下 2 つの要件を満たせます。
- App Engine によるサーバーレス運用。サーバー管理は不要で、高可用性とスケーラビリティを最初から備えています。
- 使用するデータも、クラスタへの操作も、すべて Dataproc API から取得・実行できます。各監視対象クラスタの設定データは Google Datastore(マネージド NoSQL データベース)に保存されます。
- 運用コストの低さ ― App Engine の料金モデルに加え、Shamash は 2 分に 1 度しか「目を覚まさず」、それ以外の時間はリソースを消費しないため、コストを非常に低く抑えられます。
実際のオートスケーリングには、標準で利用できる以下 2 つの Dataproc メトリクスを使うことにしました。
- YARNMemoryAvailablePercentage ― YARN が利用できる、クラスタの残メモリ割合。
- ContainerPendingRatio ― 割り当て済み YARN コンテナに対する保留中コンテナの比率。
Shamash は Python(flask および flask-admin を使用)で実装されており、以下の Google Cloud Platform サービスも併用しています。
- Cloud Pub/Sub
- Stackdriver Monitoring
- Cloud Datastore
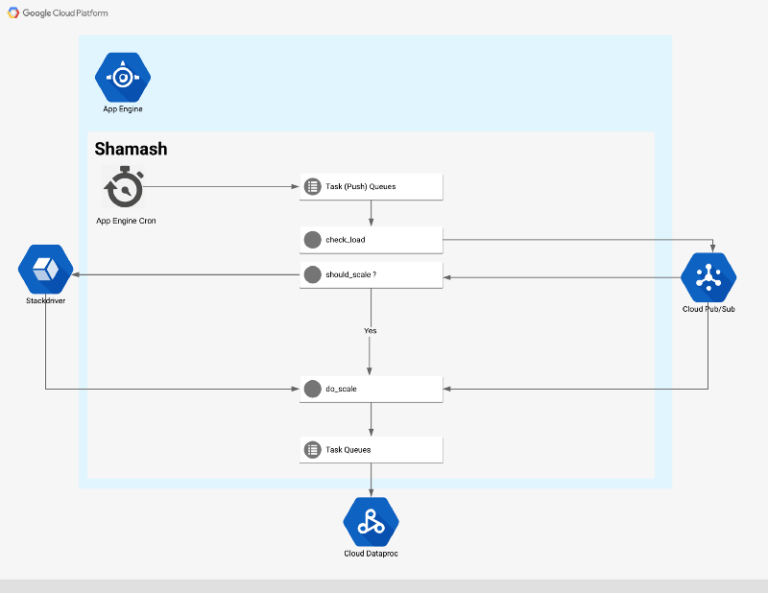
Shamash の全体アーキテクチャ
フロー
オートスケーリングフローのエントリポイントは、5 分ごとに実行される cron ジョブです(cron.yaml) で設定変更可能)。
https://gist.github.com/avivl/cee52d0135fe8166fa3c9a5d4aa2e782
cron ジョブは Web エンドポイントを呼び出し、Shamash が監視している各クラスタに対して監視タスクを生成します。
https://gist.github.com/avivl/f2df757c2af0f553e37e2facb63ebefa
監視タスクは Dataproc API 経由でクラスタからデータを取得し、Pub/Sub のトピックに発行します。新しいメッセージがトピックに到着すると、Pub/Sub サービスは関数を呼び出し、次の 2 つの処理を実行します。
- クラスタのすべてのメトリクスを時系列データとして Stackdriver に書き込みます。
- メトリクスをオートスケーリングルールと照合し、クラスタをスケール(アップまたはダウン)させる必要があるかを判断します。スケーリングが必要な場合、別の Pub/Sub トピックにメッセージが発行されます。
スケーリングタスクでは、クラスタに追加または削除すべきノード数の予測を試みます。クラスタにメモリが十分に残っていない、あるいは逆にメモリをまったく使っていない場合は、ヒューリスティック分析によって新しいノード数を算出します。
https://gist.github.com/avivl/af13077399cdbed9b122079edf2534d5
Stackdriver に十分な履歴データが蓄積されていれば、Shamash はクラスタに追加すべき新しいノード数を予測しようとします。
https://gist.github.com/avivl/4a67cf3db820eda5b76981874df50a22
境界値や妥当性をチェックしたうえで、新しいノード数でクラスタにパッチを適用します。スケールダウン時、保留中の YARN コンテナがある場合、Shamash がクラスタからノードを削除することはありません。
設定

新しい Google Cloud Dataproc クラスタを Shamash で構成するには、次の項目を設定する必要があります。
- Cluster ― Google Dataproc クラスタ名
- Region ― クラスタのリージョン
- PreemptiblePct ― Dataproc クラスタにおける preemptible ワーカーの比率
- ContainerPendingRatio ― クラスタのスケールアウトをトリガーする、割り当て済みコンテナに対する保留中コンテナの比率(UpContainerPendingRatio = yarn-containers-pending / yarn-containers-allocated)。yarn-containers-allocated = 0 の場合は ContainerPendingRatio = yarn-containers-pending となります。
- UpYARNMemAvailPct ― クラスタのスケールアップをトリガーする、YARN が利用可能な残メモリの割合。
- DownYARNMemAvailePct ― スケールダウンをトリガーする、YARN が利用可能な残メモリの割合。
- MinInstances ― ターゲットを満たさない場合でもクラスタが保持する最小ワーカー数。
- MaxInstances ― ターゲットを超えた場合でも許容される最大ワーカー数。
可視化
Shamash 自体には可視化機能を組み込んでいませんが、すべてのメトリクスは Stackdriver にレポートされるため、Shamash が追跡しているメトリクスや、ノード数、ワーカー数、preemptible ワーカー数を表示するダッシュボードを自由に構築できます。
Shamash の動作確認のため、BigQuery のサンプルデータセットの 1 つ Wiki1B を Google Cloud Storage バケットにエクスポートし、以下のクエリで HIVE テーブルを作成しました。
CREATE EXTERNAL TABLE wiki (year INT, month INT, day INT, wikimedia_project STRING, language STRING, title STRING, views INT)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’LOCATION ‘gs://hive-store/’;テーブルを作成したら、次のクエリを HIVE ジョブとして実行します。
gcloud dataproc jobs submit hive --region us-central1 --cluster cluster-4806 --execute="SELECT year, language, count(language) as counter FROM wiki group by year, language order by year, counter DESC;" --asyncStackdriver を見れば、ジョブの進行に合わせて Dataproc ノード数が増減する様子を確認できます。
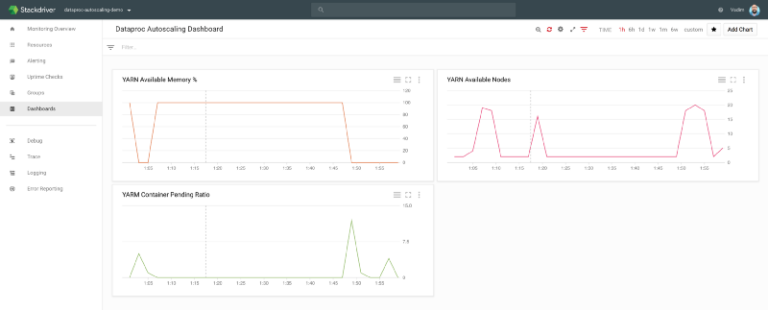
Google Stackdriver による Shamash の監視
具体的には、YARN ノード数がわずか 2 から最大 20 ノード近くまで増え、そのうち 80%(設定したポリシーに従って)が preemptible となり、ジョブ完了後には再び 2 までスケールダウンする様子が見て取れます。
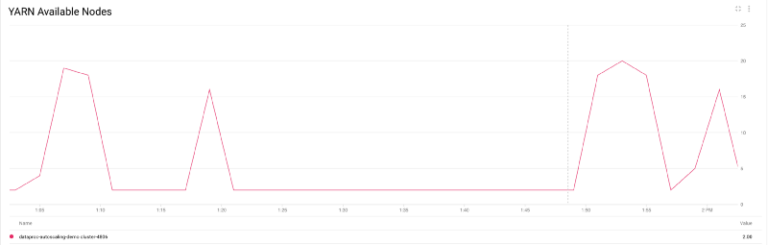
YARN ノード数のスケールアップ/ダウン
クラスタの CPU 使用率からも結果を確認できます。
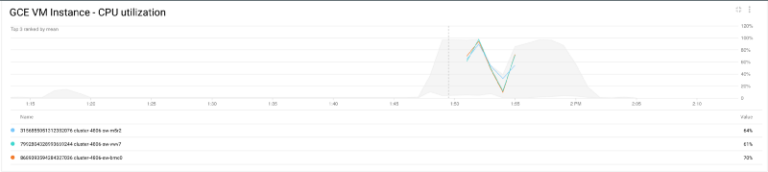
クラスタの CPU 使用率
インスタンスの CPU 負荷が上がると、Shamash はクラスタにノードを追加して負荷を分散し、ジョブが完了して CPU 使用率が下がれば、不要なノードをクラスタから削除します。
Shamash を構築するなかで、Google App Engine、Task Queues、Cloud Pub/Sub、Cloud Dataproc を組み合わせれば、比較的複雑なシステムでも手軽に構築できることを改めて実感しました。
Shamash はオープンソースです。issue や pull request は https://github.com/doitintl/shamash で受け付けていますので、ぜひ改善にご参加ください。
もっと記事を読みたい方は、投稿一覧をご覧いただき、Twitter のフォローもお願いします。