
Cloud Dataproc est un service cloud entièrement managé, remarquablement rapide à provisionner et simple d'utilisation, conçu pour exécuter des clusters Apache Spark et Apache Hadoop de façon simple et particulièrement économique. Des opérations qui prenaient autrefois des heures, voire des jours, ne demandent plus que quelques secondes ou minutes, et vous ne payez que les ressources réellement consommées, à la seconde près.
Vous pouvez redimensionner les clusters Google Cloud Dataproc à tout moment — de trois à plusieurs centaines de nœuds — sans craindre que vos pipelines de données saturent les ressources du cluster. Une fois le cluster opérationnel, vous l'agrandissez ou le réduisez manuellement.
Cependant, si vos workloads varient au fil du temps en termes de ressources nécessaires, il faudra surveiller le cluster et décider d'ajouter ou de retirer manuellement des workers. Vous voudrez par ailleurs faire tourner une partie de ces workers sur des instances préemptibles afin d'optimiser vos coûts de calcul.
C'est précisément là qu'intervient Shamash. Shamash est un système d'autoscaling open source capable de surveiller et de redimensionner plusieurs clusters Google Dataproc au sein d'un même projet.
Shamash était le dieu de la justice en Babylonie et en Assyrie, à l'image de l'autoscaler Shamash dont la mission consiste à maintenir le bon équilibre entre coûts et performances.
Notre cahier des charges pour Shamash comportait plusieurs exigences :
- Fonctionner en mode serverless pour limiter la charge de gestion
- Prendre en charge plusieurs clusters, chacun avec sa propre configuration d'autoscaling
- S'intégrer aux images et clusters Dataproc standard
- Prendre en charge les workers préemptibles pour réduire les coûts opérationnels
- Coût opérationnel réduit pour Shamash lui-même
Nous avons choisi de développer Shamash et de l'exécuter sur Google App Engine, en environnement Standard. Ce seul choix nous a permis de cocher deux exigences :
- Fonctionnement serverless grâce à App Engine. Aucun serveur à administrer, et nous bénéficions d'emblée de la haute disponibilité et de la scalabilité.
- Toutes les données utilisées et toutes les opérations effectuées sur le cluster sont accessibles via l'API DataProc. Chaque cluster surveillé dispose de sa propre configuration stockée dans Google Datastore (base NoSQL managée).
- Coût opérationnel réduit — grâce au modèle tarifaire d'App Engine et au fait que Shamash ne se réveille que toutes les 2 minutes, sans consommer de ressources le reste du temps, ce qui maintient le coût à un niveau très bas.
Pour réaliser l'autoscaling à proprement parler, nous avons choisi de nous appuyer sur deux métriques Dataproc disponibles nativement :
- YARNMemoryAvailablePercentage — le pourcentage de mémoire restante dans le cluster disponible pour YARN.
- ContainerPendingRatio — le ratio entre conteneurs YARN en attente et conteneurs alloués.
Shamash a été écrit en Python (avec flask & flask-admin) et s'appuie sur plusieurs autres services de Google Cloud Platform :
- Cloud Pub/Sub
- Stackdriver Monitoring
- Cloud Datastore
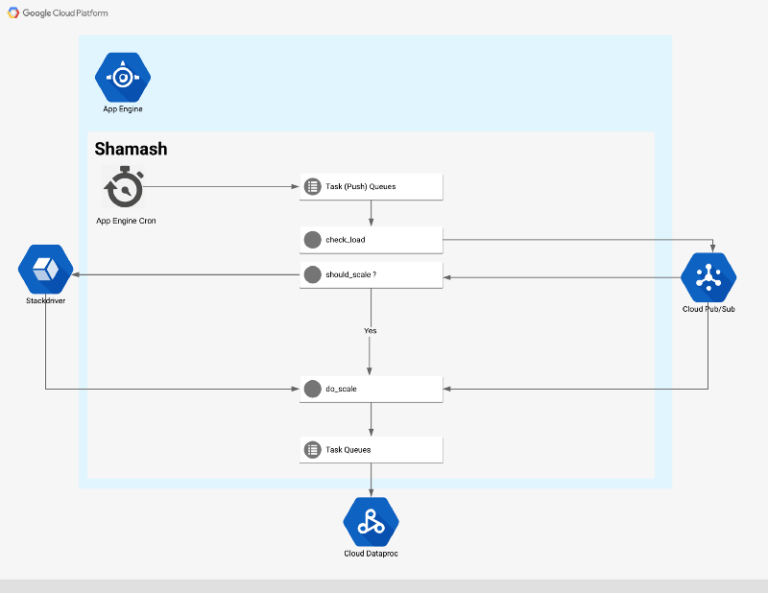
Architecture haut niveau de Shamash
Flux
Le point d'entrée du flux d'autoscaling est une tâche cron exécutée toutes les 5 minutes (configurable via cron.yaml)
https://gist.github.com/avivl/cee52d0135fe8166fa3c9a5d4aa2e782
La tâche cron appelle un endpoint web qui crée une tâche de monitoring pour chaque cluster surveillé par Shamash :
https://gist.github.com/avivl/f2df757c2af0f553e37e2facb63ebefa
La tâche de monitoring récupère les données du cluster via l'API Dataproc et les publie dans un topic Pub/Sub. Dès qu'un nouveau message arrive dans ce topic, le service Pub/Sub déclenche une fonction qui exécute deux tâches :
- Écrire toutes les métriques du cluster dans Stackdriver sous forme de séries temporelles
- Confronter les métriques aux règles d'autoscaling et déterminer s'il faut redimensionner le cluster (à la hausse ou à la baisse). Si un redimensionnement est nécessaire, un message est publié dans un autre topic Pub/Sub.
La tâche de scaling cherche à anticiper combien de nœuds doivent être ajoutés ou retirés du cluster. Si le cluster manque de mémoire ou n'en utilise pas du tout, on peut appliquer une analyse heuristique pour calculer le nouveau nombre de nœuds.
https://gist.github.com/avivl/af13077399cdbed9b122079edf2534d5
Si nous disposons de suffisamment de données historiques dans Stackdriver, Shamash tentera de prédire combien de nouveaux nœuds doivent être ajoutés au cluster.
https://gist.github.com/avivl/4a67cf3db820eda5b76981874df50a22
Après quelques contrôles de bornes et de cohérence, le cluster est mis à jour avec le nouveau nombre de nœuds. Lors d'un événement de scale down, Shamash ne retirera jamais de nœuds du cluster tant que des conteneurs YARN sont en attente.
Configuration

Pour configurer un nouveau cluster Google Cloud Dataproc avec Shamash, vous devrez renseigner les paramètres suivants :
- Cluster — nom du cluster Google Dataproc
- Region — région du cluster
- PreemptiblePct — proportion de workers préemptibles dans le cluster Dataproc
- ContainerPendingRatio — ratio de conteneurs en attente alloués déclenchant un scale out du cluster. (UpContainerPendingRatio = yarn-containers-pending / yarn-containers-allocated). Si yarn-containers-allocated = 0, alors ContainerPendingRatio = yarn-containers-pending.
- UpYARNMemAvailPct — pourcentage de mémoire restante disponible pour YARN déclenchant un scale up du cluster.
- DownYARNMemAvailePct — pourcentage de mémoire restante disponible pour YARN déclenchant un scale down.
- MinInstances - nombre minimal de workers que contiendra le cluster, même si la cible n'est pas atteinte
- MaxInstances — nombre maximal de workers autorisés, même si la cible est dépassée
Visualisation
Nous n'avons pas intégré de visualisation à Shamash, mais comme toutes les métriques remontent vers Stackdriver, vous pouvez créer un dashboard qui affiche les métriques suivies par Shamash, ainsi que le nombre de nœuds, de workers et de workers préemptibles.
Pour tester Shamash, j'ai exporté l'un des jeux de données d'exemple de BigQuery — en l'occurrence Wiki1B — vers un bucket Google Cloud Storage, puis créé une table HIVE en exécutant :
CREATE EXTERNAL TABLE wiki (year INT, month INT, day INT, wikimedia_project STRING, language STRING, title STRING, views INT)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’LOCATION ‘gs://hive-store/’;Une fois la table créée, j'ai lancé la requête suivante en tant que job HIVE :
gcloud dataproc jobs submit hive --region us-central1 --cluster cluster-4806 --execute="SELECT year, language, count(language) as counter FROM wiki group by year, language order by year, counter DESC;" --asyncDans Stackdriver, vous pouvez observer le nombre de nœuds Dataproc augmenter puis diminuer au fil de l'exécution du job :
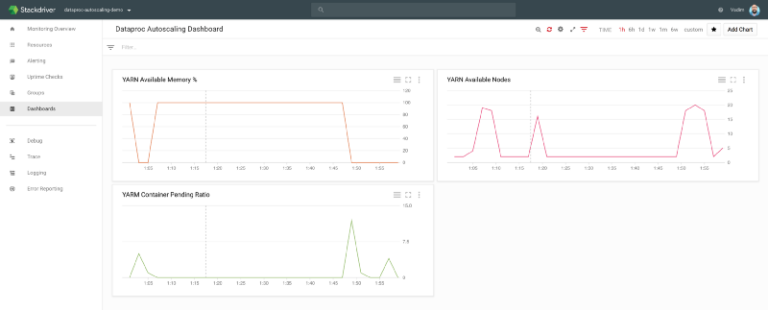
Google Stackdriver — Monitoring de Shamash
Plus précisément, on voit le nombre de nœuds YARN passer de seulement 2 à près de 20, dont 80 % en préemptibles (conformément à la politique que j'ai configurée), avant de redescendre à 2 une fois les jobs terminés.
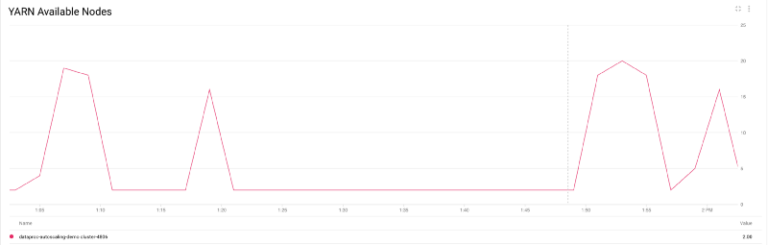
Scale up et scale down du nombre de nœuds YARN
Nous pouvons également vérifier les résultats en examinant l'utilisation CPU du cluster :
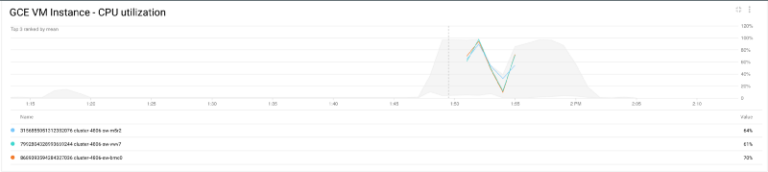
Utilisation CPU du cluster
Le CPU des instances monte en charge ; à mesure que Shamash ajoute des nœuds au cluster, la charge retombe. Une fois le job terminé et le CPU sous-utilisé, Shamash retire les nœuds devenus inutiles.
Notre expérience de développement de Shamash nous a une fois de plus confirmé la facilité avec laquelle on peut bâtir des systèmes relativement complexes en s'appuyant sur Google App Engine, Task Queues, Cloud Pub/Sub et Cloud Dataproc.
Shamash est open source et nous invitons chacun à contribuer à son amélioration en soumettant des issues et des pull requests sur https://github.com/doitintl/shamash
Envie de lire d'autres articles ? Consultez mes publications, suivez-moi sur Twitter