
O Cloud Dataproc é um serviço de nuvem totalmente gerenciado, fácil de usar e extremamente rápido de provisionar para rodar clusters Apache Spark e Apache Hadoop de forma simples e com ótimo custo-benefício. Operações que antes levavam horas ou dias passam a levar segundos ou minutos, e você paga só pelos recursos que usa, com cobrança por segundo.
Você pode redimensionar clusters do Google Cloud Dataproc a qualquer momento — de três a centenas de nós — sem se preocupar que seus pipelines de dados ultrapassem os recursos do cluster. Depois que o cluster sobe, dá para escalá-lo manualmente, para cima ou para baixo.
Mas, se seus workloads não consomem uma quantidade constante de recursos ao longo do tempo, você vai precisar acompanhar o cluster e decidir quando adicionar mais workers ou remover alguns deles. Além disso, normalmente é interessante que parte desses workers rode como instâncias preemptivas, ajudando a otimizar os custos de computação.
É aí que entra o Shamash. O Shamash é um sistema de auto-scaling open source capaz de monitorar e escalar vários clusters do Google Dataproc dentro de um único projeto.
Shamash era o deus da justiça na Babilônia e na Assíria — assim como o auto-scaler Shamash, cuja missão é equilibrar custo e desempenho.
Definimos alguns requisitos para o Shamash:
- Rodar de forma serverless para reduzir a carga de gerenciamento
- Suportar vários clusters, cada um com sua própria configuração de autoscaling
- Funcionar com imagens e clusters padrão do Dataproc
- Suportar workers preemptivos para reduzir o custo operacional
- Manter baixo o custo operacional do próprio Shamash
Resolvemos construir o Shamash e rodá-lo no Google App Engine, Standard Environment. Só essa decisão já cobriu dois dos requisitos:
- Operação serverless via App Engine. Não precisamos administrar servidores e ganhamos alta disponibilidade e escalabilidade prontas para uso.
- Todos os dados que consumimos e todas as operações que executamos no cluster estão disponíveis pela API do DataProc. Cada cluster monitorado tem sua própria configuração armazenada no Google Datastore (banco NoSQL gerenciado).
- Baixo custo operacional — graças ao modelo de preços do App Engine e ao fato de o Shamash "acordar" a cada 2 minutos e, no resto do tempo, não consumir recursos, mantendo o preço bem baixo.
Para fazer o autoscaling propriamente dito, optamos por trabalhar com duas métricas do Dataproc disponíveis nativamente:
- YARNMemoryAvailablePercentage — percentual de memória restante no cluster disponível para o YARN.
- ContainerPendingRatio — razão entre containers YARN pendentes e containers alocados.
O Shamash foi escrito em Python (com flask & flask-admin) e usa alguns serviços adicionais do Google Cloud Platform:
- Cloud Pub/Sub
- Stackdriver Monitoring
- Cloud Datastore
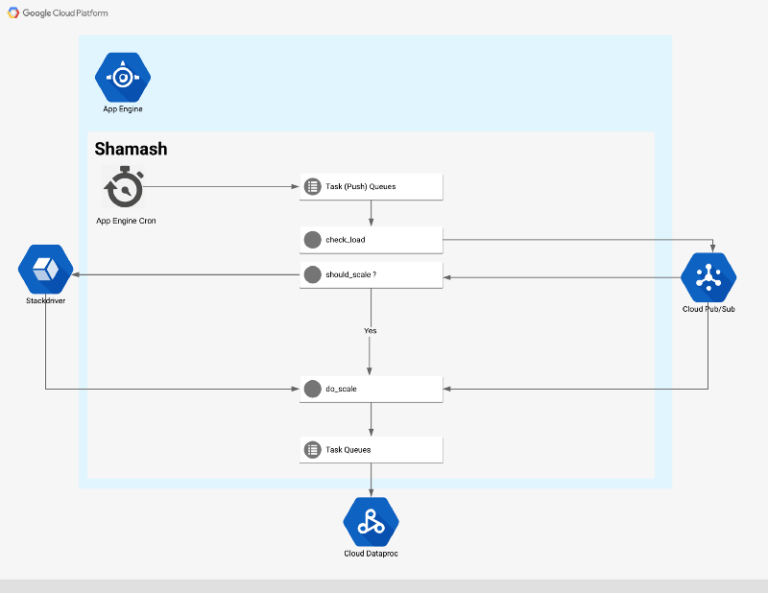
Arquitetura de alto nível do Shamash
Fluxo
O ponto de entrada do fluxo de autoscaling é um cron job que roda a cada 5 minutos (configurável via cron.yaml)
https://gist.github.com/avivl/cee52d0135fe8166fa3c9a5d4aa2e782
O cron job aciona um endpoint web que cria uma tarefa de monitoramento para cada cluster que o Shamash acompanha:
https://gist.github.com/avivl/f2df757c2af0f553e37e2facb63ebefa
A tarefa de monitoramento busca os dados do cluster pela API do Dataproc e publica em um tópico do Pub/Sub. Quando chega uma nova mensagem nesse tópico, o serviço Pub/Sub aciona uma função que faz duas coisas:
- Grava todas as métricas do cluster no Stackdriver como série temporal
- Compara as métricas com as regras de autoscaling e decide se o cluster precisa ser escalado (para cima ou para baixo). Se for o caso, publica uma mensagem em outro tópico Pub/Sub.
A tarefa de scaling tenta prever quantos nós precisam ser adicionados ou removidos. Se o cluster não tem memória suficiente ou simplesmente não usa memória nenhuma, dá para aplicar uma análise heurística e calcular um novo número de nós.
https://gist.github.com/avivl/af13077399cdbed9b122079edf2534d5
Se houver dados históricos suficientes no Stackdriver, o Shamash tenta prever quantos novos nós devem ser adicionados ao cluster.
https://gist.github.com/avivl/4a67cf3db820eda5b76981874df50a22
Depois de algumas verificações de limites e sanidade, aplicamos um patch no cluster com o novo número de nós. Em um evento de scale down, o Shamash nunca remove nós se ainda houver containers YARN pendentes.
Configuração

Para configurar um novo cluster do Google Cloud Dataproc com o Shamash, defina os seguintes parâmetros:
- Cluster — nome do cluster no Google Dataproc
- Region — região do cluster
- PreemptiblePct — proporção de workers preemptivos no cluster Dataproc
- ContainerPendingRatio — proporção de containers pendentes em relação aos alocados para disparar um evento de scale out do cluster. (UpContainerPendingRatio = yarn-containers-pending / yarn-containers-allocated). Se yarn-containers-allocated = 0, então ContainerPendingRatio = yarn-containers-pending.
- UpYARNMemAvailPct — percentual de memória restante disponível para o YARN que dispara o scale up do cluster.
- DownYARNMemAvailePct — percentual de memória restante disponível para o YARN que dispara o scale down.
- MinInstances - número mínimo de workers que o cluster manterá, mesmo que o alvo não seja atingido.
- MaxInstances — número máximo de workers permitido, mesmo que o alvo seja excedido.
Visualização
Não embutimos nenhuma visualização no Shamash, mas, como todas as métricas vão para o Stackdriver, você pode montar um dashboard com as métricas que o Shamash acompanha, além do número de nós, de workers e de workers preemptivos.
Para testar o Shamash, exportei um dos datasets de exemplo do BigQuery, especificamente o Wiki1B, para um bucket do Google Cloud Storage e criei uma tabela HIVE com:
CREATE EXTERNAL TABLE wiki (year INT, month INT, day INT, wikimedia_project STRING, language STRING, title STRING, views INT)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’LOCATION ‘gs://hive-store/’;Com a tabela criada, executei a seguinte consulta como job HIVE:
gcloud dataproc jobs submit hive --region us-central1 --cluster cluster-4806 --execute="SELECT year, language, count(language) as counter FROM wiki group by year, language order by year, counter DESC;" --asyncPelo Stackdriver, dá para acompanhar o número de nós do Dataproc subindo e descendo conforme o job avança:
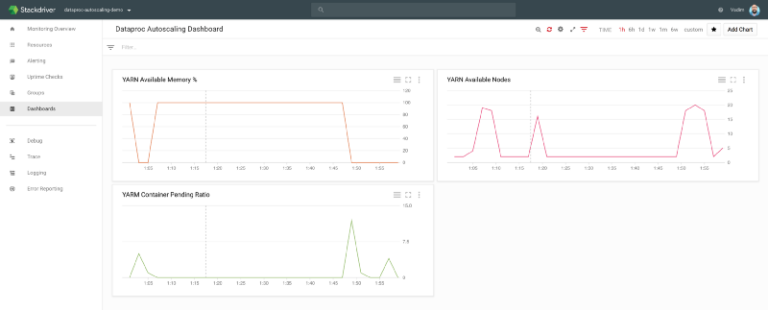
Google Stackdriver monitorando o Shamash
Mais especificamente, dá para ver o número de nós YARN saindo de apenas 2 para quase 20, com 80% deles preemptivos (conforme a política configurada), e depois voltando para 2 quando os jobs terminam.
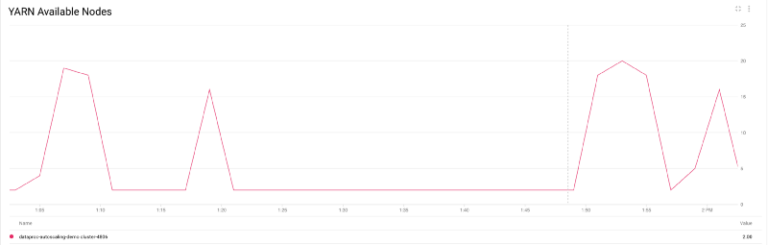
Número de nós YARN escalando para cima e para baixo
Também é possível conferir os resultados pela utilização de CPU do cluster:
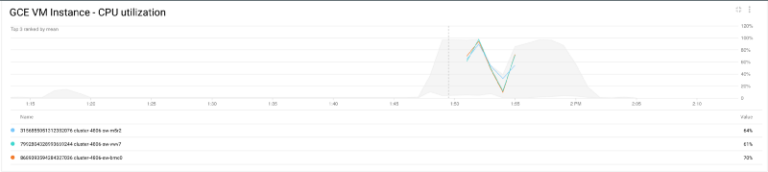
Utilização de CPU do cluster
A CPU das instâncias começa carregada e, à medida que o Shamash adiciona mais nós ao cluster, vai ficando mais folgada. Quando o job termina e o uso de CPU cai, o Shamash remove os nós desnecessários do cluster.
Com a experiência de construir o Shamash, confirmamos mais uma vez como é simples montar sistemas relativamente complexos sobre Google App Engine, Task Queues, Cloud Pub/Sub e Cloud Dataproc.
O Shamash é open source e convidamos todo mundo a colaborar no seu aprimoramento, abrindo issues e pull requests em https://github.com/doitintl/shamash
Quer mais conteúdos? Veja meus posts e me siga no twitter