
Cloud Dataproc ist ein blitzschnell bereitgestellter, einfach zu bedienender und vollständig verwalteter Cloud-Service, mit dem sich Apache Spark- und Apache Hadoop-Cluster unkompliziert und äußerst kosteneffizient betreiben lassen. Vorgänge, die früher Stunden oder Tage dauerten, sind in Sekunden oder Minuten erledigt – und Sie zahlen sekundengenau nur für die tatsächlich genutzten Ressourcen.
Sie können Google Cloud Dataproc Cluster jederzeit in der Größe anpassen – von drei bis zu hunderten Knoten – und müssen sich nie sorgen, dass Ihre Datenpipelines die Cluster-Ressourcen sprengen. Sobald der Cluster läuft, lässt er sich manuell hoch- oder herunterskalieren.
Schwankt der Ressourcenbedarf Ihrer workloads jedoch im Zeitverlauf, müssen Sie den Cluster im Auge behalten und entscheiden, wann Sie manuell weitere Worker hinzufügen oder entfernen. Hinzu kommt, dass Sie einen Teil dieser Worker üblicherweise als Preemptible-Instanzen betreiben möchten, um Ihre Compute-Kosten zu senken.
Hier kommt Shamash ins Spiel. Shamash ist ein Open-Source-Autoscaling-System, das mehrere Google Dataproc Cluster innerhalb eines einzigen Projekts überwachen und skalieren kann.
Shamash war der Gott der Gerechtigkeit in Babylonien und Assyrien – ganz wie der Shamash-Autoscaler, der die Balance zwischen Kosten und Performance hält.
An Shamash hatten wir einige Anforderungen:
- Serverless-Betrieb, um den Verwaltungsaufwand zu minimieren
- Unterstützung mehrerer Cluster, jeder mit eigener Autoscaling-Konfiguration
- Kompatibilität mit Standard-Dataproc-Images und -Clustern
- Unterstützung von Preemptible-Workern zur Senkung der Betriebskosten
- Geringe Betriebskosten von Shamash selbst
Wir haben uns entschieden, Shamash zu entwickeln und in der Standard Environment auf Google App Engine zu betreiben. Damit haben wir bereits zwei Anforderungen abgehakt:
- Serverless-Betrieb über App Engine. Wir müssen keine Server verwalten und bekommen Hochverfügbarkeit und Skalierbarkeit out of the box.
- Sämtliche Daten und alle Operationen, die wir auf dem Cluster ausführen, sind über die DataProc API verfügbar. Die Konfigurationsdaten jedes überwachten Clusters liegen in Google Datastore (verwaltete NoSQL-Datenbank).
- Geringe Betriebskosten – dank des Preismodells von App Engine und der Tatsache, dass Shamash nur alle 2 Minuten kurz "aufwacht" und in der übrigen Zeit keinerlei Ressourcen verbraucht.
Für das eigentliche Autoscaling setzen wir auf zwei Dataproc-Metriken, die out of the box zur Verfügung stehen:
- YARNMemoryAvailablePercentage – Der Prozentsatz des im Cluster verbleibenden, für YARN verfügbaren Speichers.
- ContainerPendingRatio – Das Verhältnis ausstehender YARN-Container zu zugewiesenen Containern.
Shamash wurde in Python geschrieben (mit flask & flask-admin) und nutzt einige weitere Google Cloud Platform-Dienste:
- Cloud Pub/Sub
- Stackdriver Monitoring
- Cloud Datastore
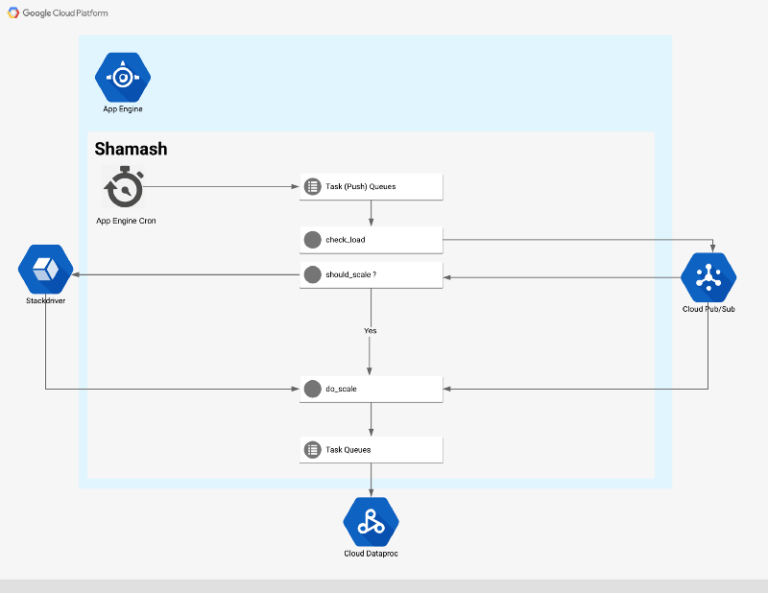
Shamash – High-Level-Architektur
Ablauf
Den Einstieg in den Autoscaling-Ablauf bildet ein Cron-Job, der alle 5 Minuten läuft (konfigurierbar über cron.yaml)
https://gist.github.com/avivl/cee52d0135fe8166fa3c9a5d4aa2e782
Der Cron-Job ruft einen Web-Endpunkt auf, der für jeden von Shamash überwachten Cluster eine Monitoring-Aufgabe anlegt:
https://gist.github.com/avivl/f2df757c2af0f553e37e2facb63ebefa
Die Monitoring-Aufgabe holt die Daten über die Dataproc API aus dem Cluster und veröffentlicht sie in einem Pub/Sub-Topic. Trifft eine neue Nachricht im Topic ein, ruft der Pub/Sub-Dienst eine Funktion auf, die zwei Dinge erledigt:
- Sie schreibt alle Cluster-Metriken als Zeitreihendaten nach Stackdriver.
- Sie prüft die Metriken anhand der Autoscaling-Regeln und entscheidet, ob der Cluster skaliert werden muss (hoch oder herunter). Ist eine Skalierung nötig, wird eine Nachricht in einem weiteren Pub/Sub-Topic veröffentlicht.
Die Skalierungsaufgabe versucht vorherzusagen, wie viele Knoten dem Cluster hinzugefügt oder entfernt werden müssen. Wenn der Cluster zu wenig Speicher übrig hat oder gar keinen Speicher nutzt, lässt sich anhand heuristischer Analysen eine neue Knotenanzahl berechnen.
https://gist.github.com/avivl/af13077399cdbed9b122079edf2534d5
Liegen genügend historische Daten in Stackdriver vor, versucht Shamash vorherzusagen, wie viele neue Knoten dem Cluster hinzugefügt werden sollten.
https://gist.github.com/avivl/4a67cf3db820eda5b76981874df50a22
Nach Grenzwert- und Plausibilitätsprüfungen patchen wir den Cluster mit der neuen Knotenanzahl. Bei einem Scale-Down-Ereignis entfernt Shamash niemals Knoten aus dem Cluster, solange noch ausstehende YARN-Container vorhanden sind.
Konfiguration

Um einen neuen Google Cloud Dataproc Cluster mit Shamash einzurichten, sind folgende Einstellungen nötig:
- Cluster – Name des Google Dataproc Clusters
- Region – Cluster-Region
- PreemptiblePct – Anteil der Preemptible-Worker im Dataproc Cluster
- ContainerPendingRatio – Verhältnis ausstehender zu zugewiesenen Containern, das ein Scale-Out-Ereignis des Clusters auslöst. (UpContainerPendingRatio = yarn-containers-pending / yarn-containers-allocated). Falls yarn-containers-allocated = 0, dann ContainerPendingRatio = yarn-containers-pending.
- UpYARNMemAvailPct – Prozentsatz des für YARN verbleibenden Speichers, der ein Scale-Up des Clusters auslöst.
- DownYARNMemAvailePct – Prozentsatz des für YARN verbleibenden Speichers, der ein Scale-Down auslöst.
- MinInstances – Mindestanzahl an Workern im Cluster, selbst wenn das Ziel nicht erreicht wird.
- MaxInstances – Maximal zulässige Worker-Anzahl, selbst wenn das Ziel überschritten wird.
Visualisierung
Eine eigene Visualisierung haben wir in Shamash nicht eingebaut. Da aber alle Metriken an Stackdriver gemeldet werden, können Sie sich ein Dashboard zusammenstellen, das die von Shamash erfassten Metriken sowie die Anzahl der Knoten, Worker und Preemptible-Worker anzeigt.
Um Shamash zu testen, habe ich einen der BigQuery-Beispieldatensätze – konkret Wiki1B – in einen Google Cloud Storage-Bucket exportiert und mit folgendem Befehl eine HIVE-Tabelle angelegt:
CREATE EXTERNAL TABLE wiki (year INT, month INT, day INT, wikimedia_project STRING, language STRING, title STRING, views INT)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’LOCATION ‘gs://hive-store/’;Nach dem Anlegen der Tabelle habe ich folgende Abfrage als HIVE-Job ausgeführt:
gcloud dataproc jobs submit hive --region us-central1 --cluster cluster-4806 --execute="SELECT year, language, count(language) as counter FROM wiki group by year, language order by year, counter DESC;" --asyncIn Stackdriver lässt sich beobachten, wie die Anzahl der Dataproc-Knoten im Verlauf des Jobs hoch- und wieder herunterläuft:
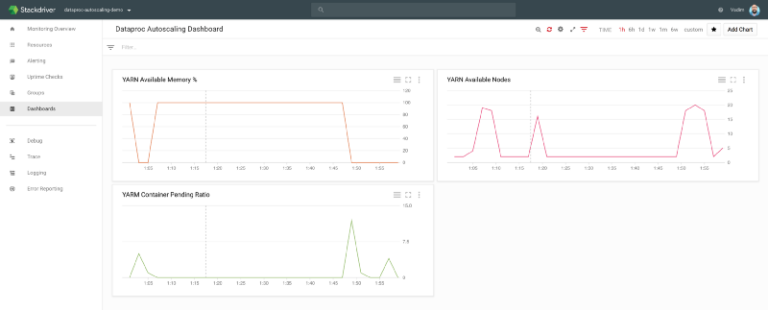
Google Stackdriver – Monitoring von Shamash
Konkret sieht man, wie die Anzahl der YARN-Knoten von nur 2 auf fast 20 wächst – davon 80 % als Preemptible-Worker (gemäß meiner Konfiguration) – und nach Abschluss der Jobs wieder auf 2 zurückgefahren wird.
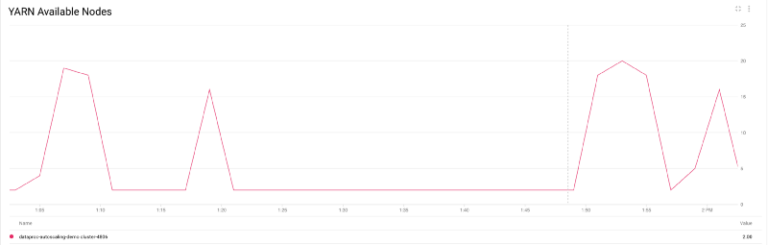
YARN – Knotenanzahl beim Hoch- und Herunterskalieren
Verifizieren lassen sich die Ergebnisse auch über die CPU-Auslastung des Clusters:
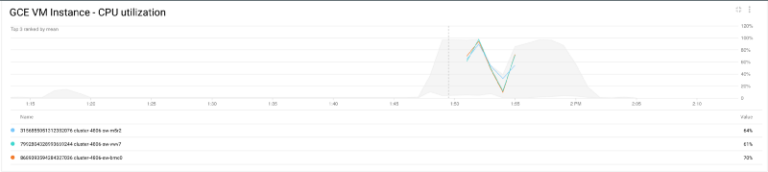
CPU-Auslastung des Clusters
Die CPU der Instanzen wird stärker ausgelastet, und während Shamash dem Cluster weitere Knoten hinzufügt, sinkt die Auslastung wieder. Ist der Job abgeschlossen und die CPU-Auslastung geht zurück, entfernt Shamash überflüssige Knoten aus dem Cluster.
Bei der Entwicklung von Shamash haben wir einmal mehr erlebt, wie einfach sich auch komplexere Systeme auf Basis von Google App Engine, Task Queues, Cloud Pub/Sub und Cloud Dataproc umsetzen lassen.
Shamash ist Open Source – wir laden alle ein, das Projekt mit Issues und Pull Requests auf https://github.com/doitintl/shamash mitzugestalten.
Lust auf mehr? Schauen Sie sich meine Beiträge an oder folgen Sie mir auf Twitter.