
Cloud Dataproc es un servicio en la nube totalmente administrado, fácil de usar y con un aprovisionamiento increíblemente rápido, pensado para correr clústeres de Apache Spark y Apache Hadoop de forma simple y muy rentable. Operaciones que antes tardaban horas o días ahora se completan en segundos o minutos, y solo pagas por los recursos que usas, con facturación por segundo.
Puedes redimensionar los clústeres de Google Cloud Dataproc en cualquier momento —desde tres hasta cientos de nodos— para no tener que preocuparte de que tus pipelines de datos superen los recursos del clúster. Una vez que el clúster está activo, puedes escalarlo manualmente hacia arriba o hacia abajo.
Sin embargo, si la cantidad de recursos que necesitan tus workloads no es constante a lo largo del tiempo, vas a tener que monitorear el clúster y decidir si conviene agregar o quitar workers manualmente. Además, normalmente te interesa que parte de esos workers corra como instancias preemptible para optimizar tus costos de cómputo.
Aquí entra en escena Shamash. Shamash es un sistema de autoescalado open source capaz de monitorear y escalar varios clústeres de Google Dataproc dentro de un mismo proyecto.
Shamash era el dios de la justicia en Babilonia y Asiria, igual que el autoscaler Shamash, cuya tarea es mantener el equilibrio entre costos y rendimiento.
Definimos algunos requisitos para Shamash:
- Correr serverless para reducir la carga operativa
- Soportar múltiples clústeres, cada uno con su propia configuración de autoescalado
- Funcionar con imágenes y clústeres estándar de Dataproc
- Soportar workers preemptible para reducir el costo operativo
- Bajo costo operativo del propio Shamash
Decidimos construir Shamash y correrlo en Google App Engine, Standard Environment. Solo con eso cubrimos dos de los requisitos:
- Operación serverless gracias a App Engine. No tenemos que administrar servidores y obtenemos alta disponibilidad y escalabilidad de fábrica.
- Todos los datos que utilizamos y todas las operaciones que ejecutamos sobre el clúster están disponibles a través de la API de DataProc. Cada clúster monitoreado tiene sus propios datos de configuración almacenados en Google Datastore (base de datos NoSQL administrada).
- Bajo costo operativo, gracias al modelo de precios de App Engine y a que Shamash "se despierta" una vez cada 2 minutos y el resto del tiempo no consume recursos, lo que mantiene el costo muy bajo.
Para el autoescalado en sí, decidimos trabajar con dos métricas de Dataproc disponibles de fábrica:
- YARNMemoryAvailablePercentage — el porcentaje de memoria restante del clúster disponible para YARN.
- ContainerPendingRatio — la proporción entre contenedores YARN pendientes y contenedores asignados.
Shamash se escribió en Python (con flask y flask-admin) y se apoya en otros servicios de Google Cloud Platform:
- Cloud Pub/Sub
- Stackdriver Monitoring
- Cloud Datastore
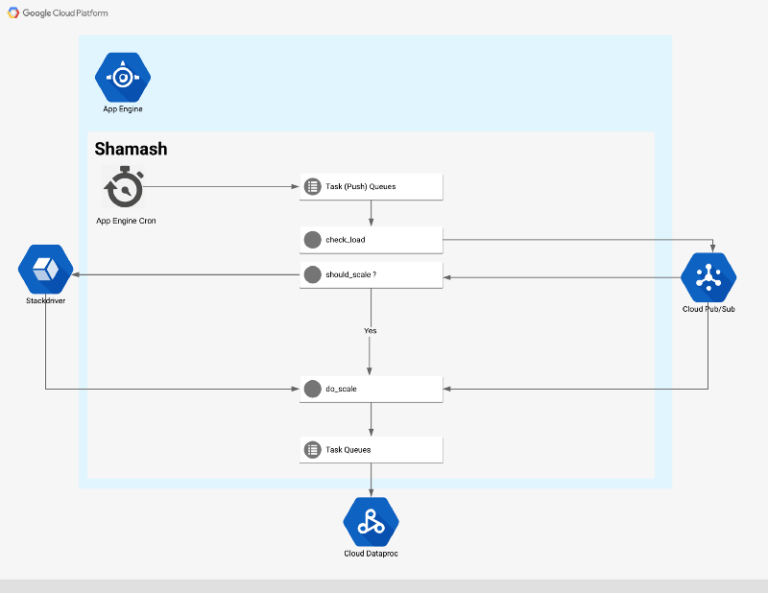
Arquitectura de alto nivel de Shamash
Flujo
El punto de entrada al flujo de autoescalado es un cron job que se ejecuta cada 5 minutos (configurable mediante cron.yaml)
https://gist.github.com/avivl/cee52d0135fe8166fa3c9a5d4aa2e782
El cron job llama a un endpoint web que crea una tarea de monitoreo para cada clúster que Shamash supervisa:
https://gist.github.com/avivl/f2df757c2af0f553e37e2facb63ebefa
La tarea de monitoreo obtiene los datos del clúster a través de la API de Dataproc y los publica en un topic de Pub/Sub. Cuando llega un mensaje nuevo al topic, el servicio de Pub/Sub invoca una función que realiza dos tareas:
- Escribe todas las métricas del clúster en Stackdriver como datos de series temporales.
- Compara las métricas con las reglas de autoescalado y decide si hay que escalar el clúster (hacia arriba o hacia abajo). Si el clúster debe escalarse, se publica un mensaje en otro topic de Pub/Sub.
La tarea de escalado intenta predecir cuántos nodos hay que agregar o quitar del clúster. Si al clúster no le queda suficiente memoria o no está usando memoria en absoluto, podemos aplicar análisis heurísticos y calcular un nuevo número de nodos.
https://gist.github.com/avivl/af13077399cdbed9b122079edf2534d5
Si tenemos suficientes datos históricos almacenados en Stackdriver, Shamash intenta predecir cuántos nodos nuevos deberían agregarse al clúster.
https://gist.github.com/avivl/4a67cf3db820eda5b76981874df50a22
Tras algunas validaciones de límites y de coherencia, parcheamos el clúster con el nuevo número de nodos. En un evento de reducción, Shamash nunca quita nodos del clúster si todavía hay contenedores YARN pendientes.
Configuración

Para configurar un nuevo clúster de Google Cloud Dataproc con Shamash, hay que definir los siguientes parámetros:
- Cluster — nombre del clúster de Google Dataproc.
- Region — región del clúster.
- PreemptiblePct — proporción de workers preemptible en el clúster de Dataproc.
- ContainerPendingRatio — proporción de contenedores pendientes sobre asignados que dispara un evento de scale out del clúster. (UpContainerPendingRatio = yarn-containers-pending / yarn-containers-allocated). Si yarn-containers-allocated = 0, entonces ContainerPendingRatio = yarn-containers-pending.
- UpYARNMemAvailPct — porcentaje de memoria restante disponible para YARN que dispara el escalado hacia arriba del clúster.
- DownYARNMemAvailePct — porcentaje de memoria restante disponible para YARN que dispara el escalado hacia abajo.
- MinInstances - número mínimo de workers que tendrá el clúster, incluso si no se alcanza el objetivo.
- MaxInstances — número máximo de workers permitidos, incluso si se supera el objetivo.
Visualización
No incluimos visualización dentro de Shamash, pero como todas las métricas se reportan a Stackdriver, puedes armar un dashboard que muestre las métricas que Shamash está rastreando, junto con el número de nodos, de workers y de workers preemptible.
Para probar Shamash, exporté uno de los datasets de ejemplo de BigQuery, concretamente Wiki1B, a un bucket de Google Cloud Storage y creé una tabla HIVE con:
CREATE EXTERNAL TABLE wiki (year INT, month INT, day INT, wikimedia_project STRING, language STRING, title STRING, views INT)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’LOCATION ‘gs://hive-store/’;Una vez creada la tabla, ejecuté la siguiente consulta como un job de HIVE:
gcloud dataproc jobs submit hive --region us-central1 --cluster cluster-4806 --execute="SELECT year, language, count(language) as counter FROM wiki group by year, language order by year, counter DESC;" --asyncDesde Stackdriver puedes monitorear cómo el número de nodos de Dataproc sube y baja a medida que el job avanza:
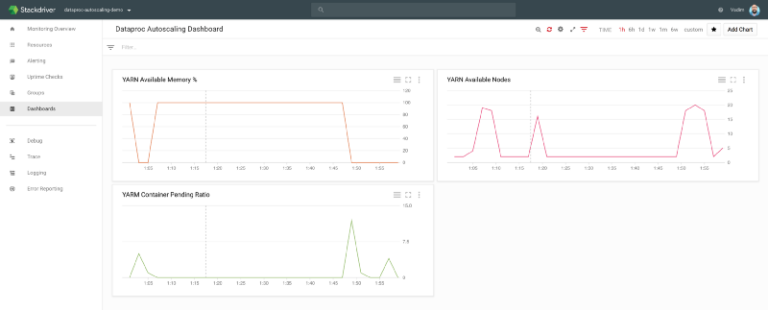
Google Stackdriver monitoreando Shamash
En detalle, se ve cómo el número de nodos YARN pasa de apenas 2 a casi 20, con un 80% de ellos como preemptible (según la política que configuré), y luego vuelve a 2 cuando los jobs terminan.
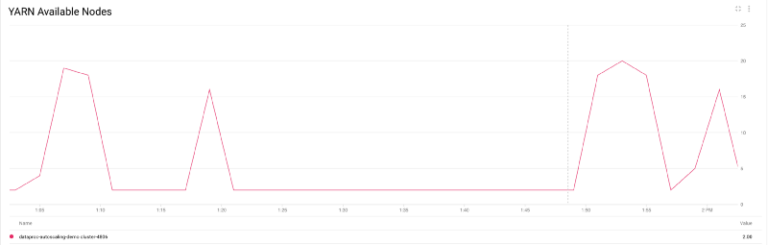
Cantidad de nodos YARN escalando hacia arriba y hacia abajo
También podemos verificar los resultados revisando la utilización de CPU del clúster:
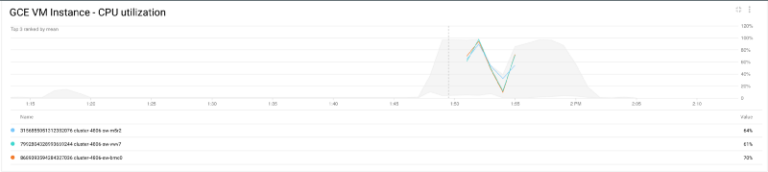
Utilización de CPU del clúster
La CPU de las instancias se satura y, a medida que Shamash agrega más nodos al clúster, se va aliviando; cuando el job termina y la utilización baja, Shamash retira los nodos que ya no hacen falta.
A partir de nuestra experiencia construyendo Shamash, comprobamos una vez más lo fácil que resulta crear sistemas relativamente complejos sobre Google App Engine, Task Queues, Cloud Pub/Sub y Cloud Dataproc.
Shamash es open source y te invitamos a sumarte a su mejora abriendo issues y pull requests en https://github.com/doitintl/shamash
¿Quieres más historias? Revisa mis posts o sígueme en Twitter.