
Cloud Dataproc è un servizio cloud completamente gestito, semplice da usare e con un provisioning fulmineo, pensato per eseguire cluster Apache Spark e Apache Hadoop in modo lineare e davvero conveniente. Operazioni che un tempo richiedevano ore o giorni si completano in pochi secondi o minuti, e si paga solo per le risorse effettivamente utilizzate, con fatturazione al secondo.
I cluster Google Cloud Dataproc si possono ridimensionare in qualsiasi momento — da tre a centinaia di nodi — senza il timore che le pipeline di dati saturino le risorse del cluster. Una volta avviato, il cluster può essere scalato manualmente verso l'alto o verso il basso.
Tuttavia, se i workloads non hanno un fabbisogno di risorse costante nel tempo, occorre monitorare il cluster e decidere se aggiungere o rimuovere manualmente dei worker. In genere, inoltre, conviene far girare alcuni di questi worker come istanze preemptible, così da ottimizzare i costi di calcolo.
Ed è qui che entra in gioco Shamash: un sistema di auto-scaling open source capace di monitorare e scalare più cluster Google Dataproc all'interno di un singolo progetto.
Shamash era il dio della giustizia nella Babilonia e nell'Assiria, proprio come l'auto-scaler Shamash, il cui compito è trovare il giusto compromesso tra costi e prestazioni.
I requisiti che ci eravamo dati per Shamash erano questi:
- Esecuzione serverless, per ridurre il carico di gestione
- Supporto a più cluster, ciascuno con la propria configurazione di autoscaling
- Compatibilità con immagini e cluster Dataproc standard
- Supporto ai worker preemptible per abbattere i costi operativi
- Costi operativi contenuti per Shamash stesso
Abbiamo deciso di sviluppare Shamash ed eseguirlo su Google App Engine, Standard Environment. Già solo questa scelta ci ha permesso di soddisfare due dei requisiti:
- Operatività serverless grazie ad App Engine: niente server da gestire, con alta disponibilità e scalabilità out of the box.
- Tutti i dati e le operazioni sul cluster sono accessibili tramite l'API Dataproc. I dati di configurazione di ogni cluster monitorato sono memorizzati su Google Datastore (database NoSQL gestito).
- Costi operativi ridotti, grazie al modello di pricing di App Engine e al fatto che Shamash si "risveglia" una volta ogni 2 minuti, mentre nel resto del tempo non consuma alcuna risorsa: la spesa resta quindi davvero bassa.
Per l'autoscaling vero e proprio abbiamo scelto di lavorare con due metriche Dataproc disponibili out of the box:
- YARNMemoryAvailablePercentage — la percentuale di memoria residua del cluster disponibile per YARN.
- ContainerPendingRatio — il rapporto tra container YARN in attesa e container allocati.
Shamash è scritto in Python (con flask & flask-admin) e si appoggia ad altri servizi di Google Cloud Platform:
- Cloud Pub/Sub
- Stackdriver Monitoring
- Cloud Datastore
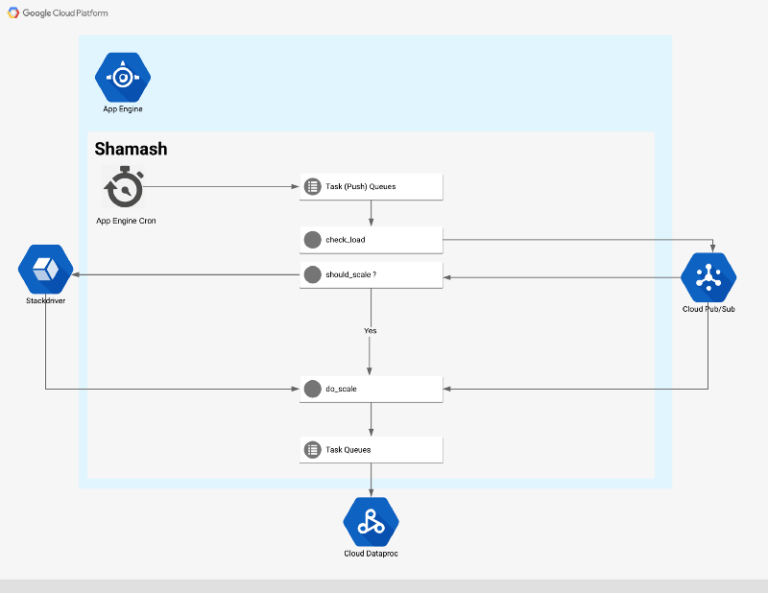
Architettura di alto livello di Shamash
Flusso
Il punto di ingresso del flusso di autoscaling è un cron job eseguito ogni 5 minuti (configurabile tramite cron.yaml)
https://gist.github.com/avivl/cee52d0135fe8166fa3c9a5d4aa2e782
Il cron job richiama un endpoint web che genera un task di monitoraggio per ciascun cluster sotto controllo di Shamash:
https://gist.github.com/avivl/f2df757c2af0f553e37e2facb63ebefa
Il task di monitoraggio recupera i dati dal cluster tramite l'API Dataproc e li pubblica su un topic Pub/Sub. Quando arriva un nuovo messaggio, il servizio Pub/Sub invoca una funzione che svolge due compiti:
- scrive tutte le metriche del cluster su Stackdriver come time series;
- confronta le metriche con le regole di autoscaling e decide se è necessario scalare il cluster (verso l'alto o verso il basso). In caso affermativo, viene pubblicato un messaggio su un altro topic Pub/Sub.
Il task di scaling cerca di stimare quanti nodi aggiungere o rimuovere dal cluster. Se il cluster non ha memoria sufficiente o non ne sta usando affatto, possiamo applicare alcune analisi euristiche per calcolare un nuovo numero di nodi.
https://gist.github.com/avivl/af13077399cdbed9b122079edf2534d5
Se in Stackdriver sono disponibili dati storici sufficienti, Shamash proverà a prevedere quanti nuovi nodi aggiungere al cluster.
https://gist.github.com/avivl/4a67cf3db820eda5b76981874df50a22
Dopo alcuni controlli sui limiti e di sanity check, applichiamo una patch al cluster con il nuovo numero di nodi. In caso di scale down, Shamash non rimuove mai nodi dal cluster se ci sono container YARN in attesa.
Configurazione

Per configurare un nuovo cluster Google Cloud Dataproc con Shamash occorre impostare i seguenti parametri:
- Cluster — nome del cluster Google Dataproc
- Region — regione del cluster
- PreemptiblePct — percentuale di worker preemptible nel cluster Dataproc
- ContainerPendingRatio — rapporto tra container in attesa e container allocati che fa scattare un evento di scale out del cluster (UpContainerPendingRatio = yarn-containers-pending / yarn-containers-allocated). Se yarn-containers-allocated = 0, allora ContainerPendingRatio = yarn-containers-pending.
- UpYARNMemAvailPct — percentuale di memoria residua disponibile per YARN che fa scattare lo scale up del cluster.
- DownYARNMemAvailePct — percentuale di memoria residua disponibile per YARN che fa scattare lo scale down.
- MinInstances - numero minimo di worker che il cluster manterrà, anche se il target non viene raggiunto.
- MaxInstances — numero massimo di worker consentiti, anche se il target viene superato.
Visualizzazione
Non abbiamo integrato alcuna visualizzazione direttamente in Shamash, ma poiché tutte le metriche vengono inviate a Stackdriver, è possibile costruire una dashboard che mostri le metriche tracciate da Shamash, oltre al numero di nodi, di worker e di worker preemptible.
Per provare Shamash ho esportato uno dei dataset di esempio di BigQuery, nello specifico Wiki1B, in un bucket Google Cloud Storage e ho creato una tabella HIVE eseguendo:
CREATE EXTERNAL TABLE wiki (year INT, month INT, day INT, wikimedia_project STRING, language STRING, title STRING, views INT)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’LOCATION ‘gs://hive-store/’;Una volta creata la tabella, ho lanciato la seguente query come job HIVE:
gcloud dataproc jobs submit hive --region us-central1 --cluster cluster-4806 --execute="SELECT year, language, count(language) as counter FROM wiki group by year, language order by year, counter DESC;" --asyncDa Stackdriver è possibile monitorare il numero di nodi Dataproc che cresce e diminuisce man mano che il job procede:
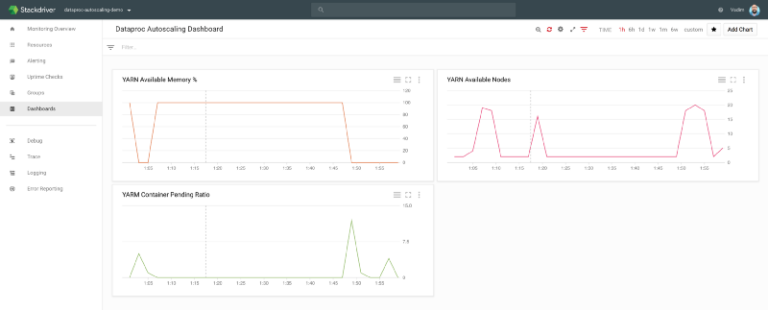
Google Stackdriver Monitoring Shamash
Più in dettaglio, si può notare il numero di nodi YARN passare da appena 2 a quasi 20, con l'80% in modalità preemptible (come configurato nella mia policy), per poi tornare a 2 al termine dei job.
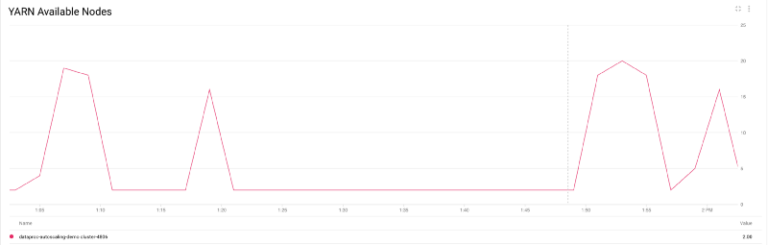
Numero di nodi YARN che scalano verso l'alto e verso il basso
Possiamo verificare i risultati anche guardando l'utilizzo della CPU del cluster:
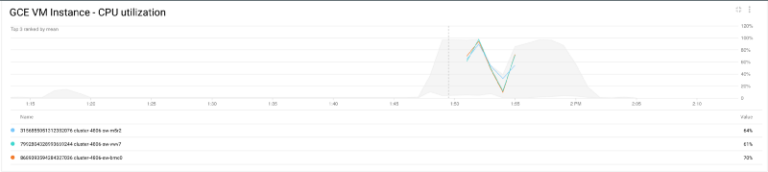
Utilizzo della CPU del cluster
La CPU delle istanze inizia a caricarsi e, man mano che Shamash aggiunge nodi al cluster, il carico cala; una volta terminato il job e con l'utilizzo della CPU in discesa, Shamash rimuove i nodi non più necessari.
L'esperienza con lo sviluppo di Shamash ci ha confermato ancora una volta con quanta semplicità si possano costruire sistemi anche piuttosto complessi sfruttando Google App Engine, Task Queues, Cloud Pub/Sub e Cloud Dataproc.
Shamash è open-source e invitiamo tutti a contribuire al suo miglioramento aprendo issue e pull request su https://github.com/doitintl/shamash
Vuoi leggere altre storie? Dai un'occhiata ai miei post e seguimi su Twitter