HTTP(S)リクエストを振り分けるレイヤー7のロードバランサー。
Amazon Web Services(AWS)のApplication Load Balancer(ALB)は、アプリケーションへの受信トラフィックを管理する強力なツールです。ALB配下のアプリケーションがダウンすれば、収益の損失や顧客満足度の低下、業務の停滞、さらにはブランドイメージの毀損にまで波及しかねません。問題が起きた際にパフォーマンスと可用性を維持するうえで、効果的なトラブルシューティングは欠かせません。
本記事では、Application Load Balancerのトラブルシューティングにおけるベストプラクティスを取り上げ、問題に効率よく的確に対処するためのポイントを解説します。
本記事の対象範囲
AWS ALBは多彩な機能を備えており、それぞれに固有のトラブルシューティング手法が求められます。すべての機能を本記事で網羅することはできませんが、今後個別の記事で順次取り上げていく予定です。今回は、お客様支援の現場でとくに頻繁に遭遇する次の課題に絞ってお話しします。
- 接続の問題
- HTTP関連のエラー
- 想定外のレイテンシ
本記事の狙いは、問題をさまざまな角度から捉え直し、根本原因まで掘り下げて突き止めるための手がかりを提供することです。
基本的なツールと知識を押さえておけば、ユーザー認証やgRPC、セッションスティッキネスといった高度なALB機能についても、しっかりとしたトラブルシューティング戦略を組み立てられるようになります。
さっそく見ていきましょう
根本原因を突き止めるには、体系立てたトラブルシューティングが欠かせません。問題を効率よく特定・分析・解決するための筋道を与えてくれるからです。それでは、各課題を順番に見ていきましょう。
接続の問題
TCP接続のタイムアウト。
ALB配下のアプリケーションにクライアントがまったくアクセスできない、というケースがあります。この場合、まず注目すべきはフロントエンド接続です。その前に、フロントエンド接続とバックエンド接続の違いを整理しておきましょう。
フロントエンド接続とは、クライアントとALBの間のやり取りを指します。ブラウザやアプリケーションといったクライアントは、ALBのDNSをIPアドレスに解決したうえでALBへリクエストを送信します。ALB側のリスナーは、指定されたプロトコルとポートで受信リクエストを処理します。
バックエンド接続とは、ALBがアプリケーションへトラフィックを振り分ける経路を指します。ALBはリクエストをターゲットグループ(EC2インスタンス、コンテナ、IPアドレスなどで構成)へ転送します。ヘルスチェックでターゲットが正常に応答できる状態であることを確認したうえで、健全なターゲットに対してトラフィックを均等に分散します。
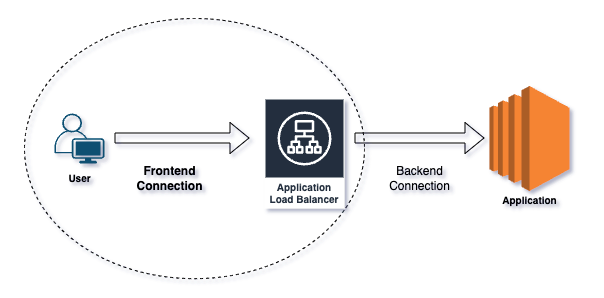
フロントエンド接続とバックエンド接続。
- 適切な問いを立てる:TCPタイムアウトか、それともリセットか?
タイムアウトはALBがリクエストを受け取っていない、または応答を返していない状態を意味し、リセットはALBが応答したものの、その内容が想定外だったことを意味します。
「つながりません」と言われたら——まずはリスナーポートに対してcurlやtelnetを実行し、その出力を読み解くことから始めましょう。Postmanのようなツールを使ったり、ブラウザでアプリケーションのURLに直接アクセスしたりするのも有効です。
接続のリセットは、誤ったリスナーポートへの接続や、クライアント側のファイアウォール設定が原因で発生することがあります。
接続タイムアウトの典型的な原因は、インターネット向けALBがプライベートサブネットに配置されている、クライアントとALBサブネット間のルーティングに問題がある、AWSのネットワークACLやセキュリティグループによって通信が制限されている、といったケースです。
SSLハンドシェイクエラーについては、OpenSSLやcurlコマンドで原因を絞り込み、CloudWatchのClientTLSNegotiationErrorCountメトリクスの推移を監視しましょう。値が増加していれば、暗号スイートの不一致やクライアント証明書の検証失敗が疑われます。
openssl s_client -connect
: curl -iv https://server:port
- 断続的か、常時発生か:ALBのDNSを解決し、各IPに対して接続テストを行うことで、問題が一時的なものか継続的なものかを切り分けましょう。
- 基本を見落とさない:セキュリティグループ、ネットワークACL、ルートテーブルがタイムアウトを引き起こすこともあります。インターネット向けの構成では、すべてのALBサブネットにインターネットゲートウェイへの適切なルートが設定されているかを確認してください。内部ロードバランサーの場合は、ユーザーの接続元(Direct Connect、Transit Gateway、VPNなど)に応じて正しいルーティングが構成されている必要があります。
- ロギングと監視:TCP/SSLエラーはアクセスログには記録されませんが、VPCフローログや接続ログには残ります。
- 一部のユーザーか、全ユーザーか:影響範囲が全ユーザーなのか、特定の地域に限定されているのかを見極めましょう。原因がクライアントの社内ネットワークやISPのルーティングにある場合もあります。
- ALBは長時間接続には不向き:ALBはAWSがプロビジョニング・管理・運用しています。そのIPアドレスは動的で、状況に応じて変動します。需要に合わせてALBがスケールしたり、ALBソフトウェアが稼働する基盤ホストに障害が起きたりすると、ALBはハードウェアやネットワーク構成を変更して復旧を図るため、長時間張りっぱなしの接続はいずれ切断されてしまいます。こうした用途にはNLBの利用を検討してください。
- クライアントはDNS TTLを尊重する:ALBのIPアドレスが変わりうる以上、ALBへ接続するクライアントはDNSを再解決して最新の値を取得する必要があります。DNSエントリを長時間キャッシュしたり、IPをハードコーディングしたりしていると、いつか必ず接続が切れます。
HTTP関連のエラー
HTTP 500で応答しているアプリケーション。
4xxや5xxといったHTTPステータスコードは、クライアントリクエストまたはサーバー応答のいずれかに問題があることを示します。HTTPエラー応答の一覧はこちらを参照してください。大まかには次のとおりです。
- 4xxエラー:不正なリクエストや認証エラーなど、クライアント側の問題。
- 5xxエラー:アプリケーションのクラッシュや構成ミスなど、サーバー側の問題。
ALBのような仲介役がクライアントリクエストをバックエンドへプロキシしている構成では、原因の切り分けが少し難しくなります。
最初にすべきは、ユーザーが直面している具体的なHTTPエラーを特定することです。多くの場合、この情報はクライアント側のブラウザやアプリケーションの画面で確認できます。すぐに分からない場合は、デベロッパーツールを使えばエラーコードを把握できます。クライアント側のデバッグ手段が限られるモバイルアプリでは、ALBのアクセスログに記録されるelb_status_codeを確認することで、エラーの正確な内容を突き止められます。
次にもっとも重要なステップは、エラーの発生源を切り分けること——つまり、ALB側で発生しているのか、それともバックエンド側なのかを特定することです。
ターゲットが返したHTTPエラーレスポンスコードを把握するには、HTTPCode_Target_4XX_CountおよびHTTPCode_Target_5XX_CountのCloudWatchメトリクスに増加がないか確認します。エラーがALB側で発生している場合は、HTTPCode_ELB_4XX_CountやHTTPCode_ELB_5XX_Countのメトリクスが増加します。さらに詳しく調べるなら、アクセスログのelb_status_codeとtarget_status_codeを突き合わせて、正確なエラーコードを確認しましょう。
シナリオ1:
elb_status_codeとtarget_status_codeの両方にエラーコードが入っており、両者が一致している場合、HTTPエラーの発生源はターゲットであり、ALBはそれをユーザーへそのまま中継しただけです。シナリオ2:
elb_status_codeにエラーコードが入っているがtarget_status_codeが「-」の場合、HTTPエラーはALB側で発生しており、ターゲットはHTTPエラーコードを返していないことを意味します。
http 2024-04-15T13:52:50.757968Z app/my-ALB/dc6cc9188 192.168.145.39:2347 10.0.0.1:80 -1 -1 -1 502 - 94 326 "GET http://example.com:80 HTTP/1.1" "curl/7.51.0" - - arn:aws:elasticloadbalancing:us-east-1:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337262-36d228ad5d99923122bbe354"
上記のアクセスログでは、elb_status_codeが502、target_status_codeが「-」となっています。さらに、request_processing_time、target_processing_time、response_processing_timeのいずれも-1です。これは、ロードバランサーが登録済みターゲットとのTCP接続を確立できなかった、あるいはSSLハンドシェイクを完了できなかったことを意味し、その結果としてALBが502エラーを生成したわけです。
ここで強調しておきたいのは、HTTPエラーコードがALB由来に見えても、実際の根本原因は別のところに潜んでいる場合があるということです。
ALBが生成しうるエラーの一覧と考えられる原因については、こちらのリンクを参照してください。すべてのHTTPエラーコードを本記事でカバーすることはできませんが、ALBが生成するHTTP 502およびHTTP 504は、お客様支援の現場でとりわけ多く遭遇するため、ここで触れておく価値があります。
ALBが生成しうるHTTP 502シナリオの切り分け:https://repost.aws/knowledge-center/elb-alb-troubleshoot-502-errors
ALBが生成しうるHTTP 504シナリオの切り分け:https://repost.aws/knowledge-center/504-error-alb
バックエンドのリソース使用状況、Webサーバーの構成、外部依存関係なども、断続的または継続的な502/504エラーの大きな要因となります。こちらのAWS記事では、バックエンドの状態を分析・デバッグするのに役立つコマンドが紹介されています。
HTTPエラーがどこで発生したかにかかわらず、リクエストをエンドツーエンドで追跡したい場面はあるはずです。X-Amzn-Trace-Idをログに残しておけば、ALBとWebサーバーを通過するリクエストを追跡できます。ALBとバックエンド双方のアクセスログでこの一意のヘッダーを突き合わせることで、ALBが処理した全リクエストを完全に可視化できます。
最後に、つねに正しい問いを自分に投げかけることを忘れないでください。エラーは特定の1ユーザーだけに起きているのか、それとも多数に影響しているのか? 断続的か、それとも継続的か? エラーに何らかのパターンはあるか? 特定のURIやホストに偏っているのか、それとも複数にまたがっているのか? 単一のターゲットだけで発生しているのか、複数のターゲットで発生しているのか?
想定外のレイテンシ
レイテンシとは、アプリケーションがユーザーリクエストに応答するまでにかかる時間のことです。レイテンシが高いと、アプリケーションのパフォーマンスとユーザー体験に深刻な影響を与えます。
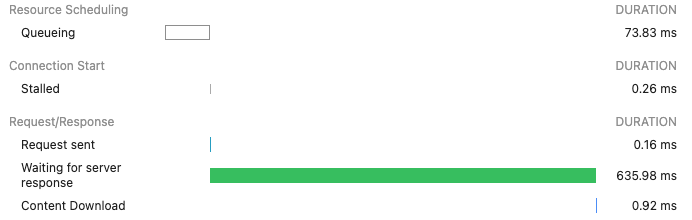
ブラウザのデベロッパーツールのネットワーク欄に表示された各種接続タイマー。
レイテンシ問題のトラブルシューティングでは、原因がレイヤー3/4(TCP/IP)にあるのか、それともレイヤー7(アプリケーション)にあるのか、さらにALB側なのかバックエンド側なのかを見極めることが重要です。
以下のコマンドは、http://backendip:portのバックエンドサーバーへHTTPリクエストを送り、レスポンスを破棄したうえで、各リクエストのタイミングメトリクスとHTTPステータスコードを表示します。接続時間、リダイレクト時間、リクエスト全体の所要時間といった情報が得られるため、アプリケーションのパフォーマンスや健全性を把握するのに役立ちます。バックエンドサーバーとALBドメインに対して別々に実行することで、タイミングの異常を検出できます。
for ((i = 1; i <= 10; i++)); do curl -w "http_code:%{http_code}\t time_connect=%{time_connect}\t time_redirect=%{time_redirect}\t time_pretransfer=%{time_pretransfer}\t time_starttransfer=%{time_starttransfer}\t time_total=%{time_total}\n\n" -o /dev/null -k -s http://backendip:port -o /dev/null ; done
ALBかバックエンドか:CloudWatchのTargetResponseTimeメトリクスは、HTTPリクエストがロードバランサーから出てからターゲットの応答が返ってくるまでの時間を計測するもので、バックエンドのレイテンシを表します。平均値や最大値にスパイクが見られる場合、想定外のレイテンシの原因はバックエンドにある可能性が高いです。
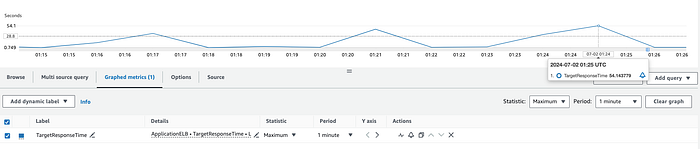
最適化されていないバックエンドが、HTTPリクエストに対して約54秒後に応答している様子。
個々のリクエストの処理時間をさらに掘り下げるには、ALBアクセスログからrequest_processing_timeとtarget_processing_timeを、Webサーバーログからバックエンドの処理時間をそれぞれ確認しましょう。
request_processing_time — ロードバランサーがクライアントからリクエストを受信してから、ターゲットへ送信するまでの時間。
target_processing_time — ロードバランサーがターゲットへリクエストを送信してから、ターゲットがレスポンスヘッダーの送信を開始するまでの時間。
これらのメトリクスを分析することで、レイテンシがどこで発生しているのかをピンポイントで突き止められます。
本来であれば、バックエンド側で記録される応答時間(バックエンド処理時間)はtarget_processing_timeと一致するはずです。一致しない場合、その差はALBとバックエンド間のネットワークレイテンシを示します。前述のとおり、target_processing_timeが高ければ、バックエンドが過負荷または最適化不足の状態にあるか、外部依存関係に問題がある可能性があります。
一方、request_processing_timeが高い場合は、ALB自体に問題があるサインです。ALBでユーザー認証を行う際には、AWS WAFやIDプロバイダーへのバックチャネルリクエストによって生じるレイテンシも考慮に入れる必要があります。
まとめ
本記事では、AWS ALBのトラブルシューティングのベストプラクティスを、接続の問題、HTTP関連のエラー、想定外のレイテンシという代表的な3つの課題に絞って解説しました。体系立てたアプローチに、コマンドラインツールやAWSネイティブの可観測性ツールを組み合わせることで、根本原因を切り分け・特定する重要性をお伝えしました。今後の記事では、特定のALB機能とそのトラブルシューティング手法をさらに深掘りしていきます。
もっと詳しく知りたい方や、当社のサービスにご興味のある方は、お気軽にお問い合わせください。ご連絡はこちらからどうぞ。