Load Balancer di Layer 7 per la distribuzione delle richieste HTTP(s).
L'Application Load Balancer di Amazon Web Services (AWS) ( ALB) è uno strumento potente per gestire il traffico in ingresso verso le applicazioni. Quando un'applicazione dietro un ALB va in downtime, le conseguenze possono essere pesanti: perdite di fatturato, clienti insoddisfatti, interruzioni operative e persino danni alla reputazione del brand. Quando emergono problemi, un troubleshooting efficace diventa fondamentale per garantire performance e disponibilità ottimali.
In questo articolo vedremo le best practice per il troubleshooting dell'Application Load Balancer, così da affrontare i problemi in modo rapido ed efficace.
Ambito
Gli AWS ALB offrono un'ampia gamma di funzionalità, ognuna delle quali richiede metodologie di troubleshooting specifiche. Non potendo trattarle tutte nel dettaglio in un solo articolo, dedicherò in futuro dei post specifici a ciascuna di esse. Per ora mi concentrerò sui problemi più comuni che ho riscontrato lavorando a fianco dei clienti.
- Problemi di connettività.
- Errori HTTP.
- Latenza anomala.
L'obiettivo di questo blog post è indicarti la direzione giusta, spingendoti ad analizzare il problema da angolazioni diverse e ad approfondire fino a individuarne la causa principale.
Partendo da strumenti e nozioni di base, è possibile costruire una solida strategia di troubleshooting anche per funzionalità avanzate dell'ALB come autenticazione utente, gRPC e session stickiness.
Entriamo nel vivo
Un troubleshooting strutturato è essenziale per arrivare alla causa principale di un problema, perché fornisce un metodo sistematico per identificare, analizzare e risolvere le criticità in modo efficiente. Affrontiamo questi problemi uno alla volta:
Problemi di connettività
Timeout della connessione TCP.
I client potrebbero trovare l'applicazione dietro l'ALB del tutto irraggiungibile. In questi casi, il troubleshooting deve concentrarsi sulla connessione frontend. Vediamo prima la differenza tra connessioni frontend e backend:
Le connessioni frontend riguardano il modo in cui i client interagiscono con l'ALB. I client, come browser e applicazioni, dopo aver risolto il DNS dell'ALB negli indirizzi IP, inviano le richieste all'ALB. I listener sull'ALB gestiscono le richieste in ingresso utilizzando i protocolli e le porte specificati.
Le connessioni backend riguardano il modo in cui l'ALB instrada il traffico verso le applicazioni. L'ALB inoltra le richieste ai target group, che possono includere istanze EC2, container o indirizzi IP. Esegue health check per verificare che i target siano integri e in grado di gestire le richieste, distribuendo poi il traffico in ingresso in modo uniforme tra i target sani.
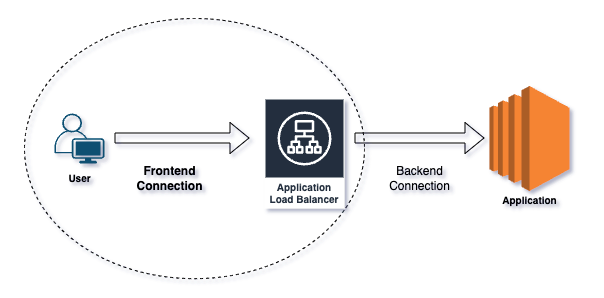
Connessione frontend vs backend.
- Poniti le domande giuste: timeout o reset TCP?
Un timeout indica che l'ALB non ha mai ricevuto la richiesta o non ha mai inviato una risposta; un reset, invece, indica che l'ALB ha risposto, ma in modo inatteso.
Quante volte hai sentito dire "non riesco a connettermi"? — Per capire i problemi di connettività, parti eseguendo curl o telnet sulla porta del listener e interpreta l'output. In alternativa, puoi usare strumenti come Postman oppure aprire direttamente l'URL dell'applicazione nel browser.
I reset di connessione possono dipendere da tentativi sulla porta del listener sbagliata o dalle impostazioni del firewall lato client.
Tra le possibili cause dei timeout di connessione ci sono un ALB internet-facing collocato in una subnet privata, problemi di routing tra i client e le subnet dell'ALB oppure restrizioni imposte da Network ACL/Security Group di AWS.
Per gli errori di handshake SSL, sfrutta i comandi OpenSSL e Curl per individuare i problemi e tieni d'occhio la metrica CloudWatch ClientTLSNegotiationErrorCount: un suo aumento può segnalare mismatch di cipher o errori di verifica del certificato client.
openssl s_client -connect
: curl -iv https://server:port
- Intermittente o costante: stabilisci se il problema è intermittente o persistente risolvendo il DNS dell'ALB e testando le connessioni verso i suoi IP.
- Non dimenticare le basi: Security Group, Network ACL e Route Table possono causare timeout. Verifica che tutte le subnet dell'ALB abbiano route Internet Gateway adeguate per i deployment internet-facing, oppure un routing corretto per i load balancer interni in base alla posizione degli utenti (Direct Connect, Transit Gateway, VPN).
- Logging e monitoring: gli errori TCP/SSL non vengono registrati negli access log, ma sono catturati nei VPC flow log e nei connection log.
- Pochi utenti o tutti: valuta se i problemi interessano la totalità degli utenti o solo determinate aree geografiche; le cause potrebbero risiedere nella rete interna del client o nel routing dell'ISP.
- L'ALB non è adatto a connessioni di lunga durata: l'ALB è provisionato, gestito e mantenuto da AWS. I suoi IP sono dinamici e cambiano nel tempo. Può accadere quando l'ALB deve scalare per soddisfare la domanda o quando l'host sottostante su cui gira il software dell'ALB presenta un guasto. Di conseguenza, l'ALB modifica la configurazione hardware e di rete per ripristinarsi dai fallimenti. Le connessioni di lunga durata, prima o poi, finiscono per interrompersi. Per questo caso d'uso, valuta l'utilizzo di NLB.
- Client che rispettano il TTL del DNS: dato che l'ALB può cambiare i propri indirizzi IP, i client che si connettono dovrebbero rispettare il TTL e risolvere nuovamente il DNS per ottenere i valori più aggiornati. Se i client tengono in cache la voce DNS troppo a lungo o hanno gli IP hardcoded, prima o poi la connessione si interromperà.
Errori HTTP
Applicazione che risponde con un codice di errore HTTP 500.
Gli errori HTTP, ovvero i codici di stato 4xx e 5xx, segnalano problemi nelle richieste del client o nelle risposte del server. Per l'elenco completo delle risposte di errore HTTP, consulta il link qui. In linea generale:
- Errori 4xx: problemi lato client, come richieste malformate o accessi non autorizzati.
- Errori 5xx: problemi lato server, come crash dell'applicazione o configurazioni errate.
Le cose si complicano quando entra in gioco un intermediario come l'ALB, che fa da proxy tra le richieste del client e l'applicazione backend.
Il primo passo è identificare lo specifico errore HTTP segnalato dall'utente. Spesso l'informazione è già visibile nel browser o nell'applicazione lato client. Quando non lo è, si possono utilizzare i developer tool per ricavare il codice di errore. Per le applicazioni mobili, dove le opzioni di debug lato client sono limitate, controllare l'elb_status_code negli access log dell'ALB fornisce dettagli precisi sull'errore.
Lo step di troubleshooting più importante a questo punto è isolare l'origine dell'errore — capire cioè se proviene dall'ALB o dal backend stesso.
Per identificare i codici di errore HTTP generati dal target, controlla gli incrementi nelle metriche CloudWatch HTTPCode_Target_4XX_Count e HTTPCode_Target_5XX_Count. Se invece l'errore proviene dall'ALB, vedrai aumentare le metriche HTTPCode_ELB_4XX_Count e HTTPCode_ELB_5XX_Count. Per un'analisi più approfondita, esamina nelle voci dell'access log i campi elb_status_code e target_status_code per individuare il codice di errore esatto.
Scenario 1: se sia
elb_status_codesiatarget_status_codecontengono codici di errore e questi coincidono, la risposta di errore HTTP arriva dal target e l'ALB l'ha semplicemente inoltrata all'utente.Scenario 2: se
elb_status_codecontiene un codice di errore matarget_status_codeè impostato su "-", la risposta di errore HTTP è stata generata dall'ALB, a indicare che il target non ha risposto con un codice di errore HTTP.
http 2024-04-15T13:52:50.757968Z app/my-ALB/dc6cc9188 192.168.145.39:2347 10.0.0.1:80 -1 -1 -1 502 - 94 326 "GET http://example.com:80 HTTP/1.1" "curl/7.51.0" - - arn:aws:elasticloadbalancing:us-east-1:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337262-36d228ad5d99923122bbe354"
Nell'access log qui sopra, l'elb_status_code è impostato a 502 e il target_status_code è "-". Inoltre, i campi request_processing_time, target_processing_time e response_processing_time sono tutti impostati a -1. Questo significa che il load balancer non è riuscito a stabilire una connessione TCP né a completare un handshake SSL con il target registrato, generando di conseguenza un errore 502.
Il punto che voglio sottolineare è che, anche se il codice di errore HTTP sembra arrivare dall'ALB, la causa reale risiede altrove.
Per l'elenco completo degli errori generati dall'ALB e delle relative cause possibili, consulta il link qui. Pur non potendo coprire ogni codice di errore HTTP in questo post, vale la pena soffermarsi sugli errori HTTP 502 e HTTP 504 generati dall'ALB, perché sono tra i più comuni che ho riscontrato lavorando con i clienti.
Isolare tutti i possibili scenari di HTTP 502 generati dall'ALB: https://repost.aws/knowledge-center/elb-alb-troubleshoot-502-errors
Isolare tutti i possibili scenari di HTTP 504 generati dall'ALB: https://repost.aws/knowledge-center/504-error-alb
Utilizzo delle risorse di backend, configurazione del web server e dipendenze esterne giocano un ruolo determinante e possono provocare errori 502/504 intermittenti o costanti. Questo articolo di AWS riporta alcuni comandi utili per analizzare e fare debug della salute del backend.
A prescindere da chi genera l'errore HTTP, può essere utile tracciare le richieste end-to-end. Loggando l'X-Amzn-Trace-Id puoi seguire le richieste attraverso l'ALB e i web server. Confrontando l'header univoco negli access log dell'ALB e del backend, ottieni piena visibilità su ogni richiesta gestita dall'ALB.
Infine, ricordati sempre di porti le domande giuste: l'errore riguarda un singolo utente o molti? È intermittente o costante? Si nota un pattern? Coinvolge un URI/host specifico o più di uno? Si manifesta su un singolo target o su più target?
Latenza anomala
La latenza è il tempo che impiega l'applicazione a rispondere alle richieste degli utenti. Una latenza elevata può compromettere seriamente le performance e l'esperienza utente dell'applicazione.
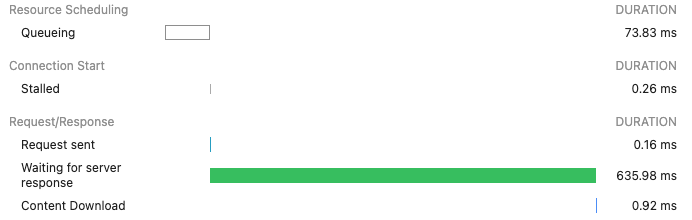
Sezione network dei developer tool del browser che mostra i diversi timer di connessione.
Quando si fa troubleshooting dei problemi di latenza, è importante stabilire se il problema risieda al Layer 3/4 (TCP/IP) o al Layer 7 (Applicazione), e se sia imputabile all'ALB o all'applicazione backend.
Il comando seguente invia richieste HTTP a un server backend all'indirizzo http://backendip:port, scarta le risposte e stampa diverse metriche di timing e il codice di stato HTTP per ogni richiesta. È utile per misurare le performance e la salute dell'applicazione, perché fornisce dettagli su tempo di connessione, tempo di redirezione e durata complessiva della richiesta. Esegui il comando separatamente sui server backend e sul dominio dell'ALB per individuare eventuali anomalie nei tempi.
for ((i = 1; i <= 10; i++)); do curl -w "http_code:%{http_code}\t time_connect=%{time_connect}\t time_redirect=%{time_redirect}\t time_pretransfer=%{time_pretransfer}\t time_starttransfer=%{time_starttransfer}\t time_total=%{time_total}\n\n" -o /dev/null -k -s http://backendip:port -o /dev/null ; done
ALB o backend: la metrica CloudWatch TargetResponseTime misura il tempo che intercorre dal momento in cui una richiesta HTTP lascia il load balancer fino alla ricezione della risposta dal target. È quindi un indicatore della latenza del backend. Se osservi picchi nei valori medi o massimi, la latenza anomala è con ogni probabilità imputabile al backend.
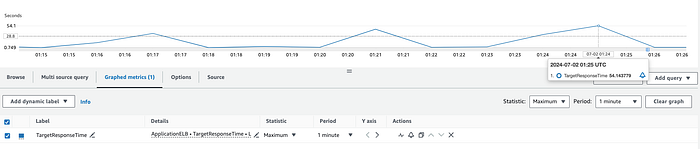
Backend non ottimizzato che risponde alla richiesta HTTP dopo circa 54 secondi.
Per indagare ulteriormente sul tempo di elaborazione delle singole richieste, esamina i campi request_processing_time e target_processing_time negli access log dell'ALB, oltre al tempo di elaborazione del backend registrato nei log del web server.
request_processing_time — il tempo che intercorre da quando il load balancer riceve la richiesta dal client a quando la inoltra a un target.
target_processing_time — il tempo che intercorre da quando il load balancer invia la richiesta a un target a quando il target inizia a inviare gli header di risposta.
L'analisi di queste metriche ti aiuterà a individuare con precisione dove si verificano i problemi di latenza.
Idealmente, il tempo di risposta registrato sul backend (backend processing time) dovrebbe coincidere con il target_processing_time. In caso contrario, la differenza rappresenta la latenza di rete tra l'ALB e il backend. Come anticipato, un target_processing_time elevato può indicare un backend sovraccarico o non ottimizzato, oppure problemi con dipendenze esterne.
Un request_processing_time elevato, invece, segnala problemi a carico dell'ALB stesso. Considera anche la latenza che può essere introdotta dalle richieste backchannel verso AWS WAF e gli identity provider quando l'autenticazione utente avviene sull'ALB.
In sintesi
Questo blog post analizza le best practice per il troubleshooting degli AWS ALB, concentrandosi su problemi comuni come quelli di connettività, gli errori HTTP e la latenza anomala. Mette in luce l'importanza di un approccio strutturato, affiancato a utility da riga di comando e agli strumenti di observability nativi di AWS, per isolare e identificare le cause principali. I prossimi post approfondiranno specifiche funzionalità dell'ALB e le relative metodologie di troubleshooting.
Se vuoi saperne di più o sei interessato ai nostri servizi, non esitare a contattarci. Puoi farlo qui.