Layer-7-Load-Balancer zur Verteilung von HTTP(S)-Anfragen.
Der Application Load Balancer von Amazon Web Services (AWS) ( ALB) ist ein leistungsstarkes Werkzeug, um eingehenden Traffic zu Ihren Anwendungen zu steuern. Fällt eine Anwendung hinter einem ALB aus, drohen Umsatzeinbußen, unzufriedene Kunden, Betriebsunterbrechungen und sogar Reputationsschäden. Treten Probleme auf, ist effektives Troubleshooting entscheidend, um Performance und Verfügbarkeit aufrechtzuerhalten.
In diesem Artikel zeigen wir Best Practices für das Troubleshooting des Application Load Balancers, damit Sie Probleme effizient und zielgerichtet lösen.
Scope
AWS ALBs bieten eine Vielzahl an Funktionen, die jeweils eigene Troubleshooting-Methoden erfordern. Da dieser Artikel nicht jede Funktion im Detail behandeln kann, werde ich sie in künftigen Blogposts gezielt aufgreifen. Hier konzentriere ich mich zunächst auf die häufigsten Probleme, die mir in der Kundenbetreuung begegnet sind:
- Verbindungsprobleme
- HTTP-bezogene Fehler
- Unerwartete Latenz
Dieser Beitrag soll Ihnen die Richtung weisen und Sie ermutigen, das Problem aus verschiedenen Blickwinkeln zu betrachten und der eigentlichen Ursache auf den Grund zu gehen.
Mit grundlegenden Tools und etwas Fachwissen lässt sich auch für fortgeschrittene ALB-Funktionen wie Benutzerauthentifizierung, gRPC oder Session Stickiness eine belastbare Troubleshooting-Strategie aufbauen.
Legen wir los
Strukturiertes Troubleshooting ist der Schlüssel, um die eigentliche Ursache eines Problems zu finden – es liefert einen systematischen Ansatz, um Probleme effizient zu identifizieren, zu analysieren und zu beheben. Gehen wir die Themen nacheinander durch:
Verbindungsprobleme
TCP-Verbindungs-Timeout.
Es kann vorkommen, dass Clients Ihre Anwendung hinter dem ALB überhaupt nicht erreichen. In diesen Fällen liegt der Fokus des Troubleshootings auf der Frontend-Verbindung. Zunächst der Unterschied zwischen Frontend- und Backend-Verbindungen:
Frontend-Verbindungen beschreiben, wie Clients mit dem ALB interagieren. Clients wie Browser oder Anwendungen lösen den ALB-DNS-Namen zu IP-Adressen auf und senden anschließend Anfragen an den ALB. Listener auf dem ALB verarbeiten die eingehenden Anfragen über die festgelegten Protokolle und Ports.
Backend-Verbindungen beschreiben, wie der ALB den Traffic an Ihre Anwendungen weiterleitet. Der ALB leitet Anfragen an Target Groups weiter, die EC2-Instanzen, Container oder IP-Adressen umfassen können. Über Health Checks stellt er sicher, dass die Targets gesund und in der Lage sind, Anfragen zu verarbeiten, und verteilt den eingehenden Traffic gleichmäßig auf diese gesunden Targets.
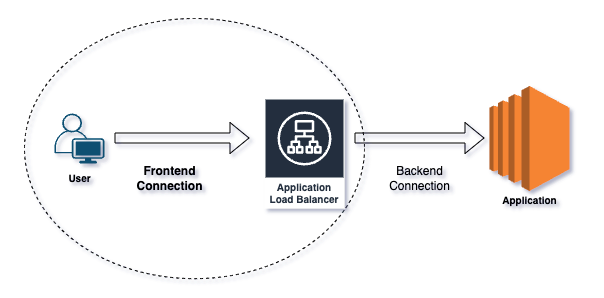
Frontend- vs. Backend-Verbindung.
- Stellen Sie die richtigen Fragen: TCP-Timeout oder Reset?
Ein Timeout bedeutet, dass der ALB Ihre Anfrage entweder nie erhalten oder nie beantwortet hat. Ein Reset heißt: Der ALB hat geantwortet – aber auf unerwartete Weise.
Schon einmal "Ich kann mich nicht verbinden" gehört? – Um Verbindungsprobleme zu verstehen, starten Sie mit curl oder telnet auf dem Listener-Port und werten Sie die Ausgabe aus. Alternativ eignen sich Tools wie Postman oder ein direkter Aufruf der Anwendungs-URL im Browser.
Connection Resets können entstehen, wenn auf einen falschen Listener-Port verbunden wird, oder durch Firewall-Einstellungen auf der Client-Seite.
Mögliche Ursachen für Verbindungs-Timeouts: ein Internet-facing ALB, der in einem privaten Subnetz platziert wurde, Routing-Probleme zwischen Clients und ALB-Subnetzen oder Einschränkungen durch AWS Network ACLs/Security Groups.
Bei SSL-Handshake-Fehlern helfen OpenSSL- und Curl-Befehle, das Problem einzugrenzen. Behalten Sie außerdem die CloudWatch-Metrik ClientTLSNegotiationErrorCount im Blick: Steigt sie an, deutet das auf nicht übereinstimmende Cipher Suites oder fehlgeschlagene Client-Zertifikatsprüfungen hin.
openssl s_client -connect
: curl -iv https://server:port
- Sporadisch oder dauerhaft: Klären Sie, ob das Problem sporadisch oder dauerhaft auftritt, indem Sie den ALB-DNS auflösen und Verbindungen zu den einzelnen IPs testen.
- Vergessen Sie die Grundlagen nicht: Security Groups, Network ACLs und Route Tables können Timeouts verursachen. Stellen Sie sicher, dass alle ALB-Subnetze bei Internet-facing-Deployments geeignete Internet-Gateway-Routen haben oder bei internen Load Balancern korrektes Routing entsprechend dem Standort der Nutzer (Direct Connect, Transit Gateway, VPNs).
- Logging und Monitoring: TCP/SSL-Fehler werden nicht in den Access Logs erfasst, jedoch in den VPC Flow Logs und Connection Logs.
- Wenige Nutzer oder alle: Prüfen Sie, ob das Problem alle Nutzer betrifft oder nur bestimmte Standorte; Ursachen können auch im internen Netzwerk eines Clients oder im Routing seines ISP liegen.
- ALB ist nicht für langlebige Verbindungen geeignet: Der ALB wird von AWS bereitgestellt, betrieben und gewartet. ALB-IPs sind dynamisch und ändern sich von Zeit zu Zeit – etwa wenn der ALB skalieren muss, um die Last zu bewältigen, oder wenn der zugrunde liegende Host der ALB-Software ausfällt. AWS passt dann Hardware- und Netzwerkkonfiguration an, um den Ausfall abzufangen. Lang laufende Verbindungen brechen dabei zwangsläufig ab. Für solche Anwendungsfälle eignet sich der NLB besser.
- Clients müssen die DNS-TTL respektieren: Da der ALB seine IP-Adressen ändern kann, sollten Clients, die sich mit dem ALB verbinden, den DNS regelmäßig neu auflösen, um die aktuellen Werte zu erhalten. Wenn Clients den DNS-Eintrag zu lange im Cache halten oder IPs hartkodiert sind, wird die Verbindung irgendwann brechen.
HTTP-bezogene Fehler
Anwendung antwortet mit einem HTTP-500-Fehlercode.
HTTP-Fehler wie 4xx- und 5xx-Statuscodes weisen auf Probleme entweder bei den Client-Anfragen oder bei den Server-Antworten hin. Eine vollständige Liste der HTTP-Fehlerantworten finden Sie hier. Grundsätzlich gilt:
- 4xx-Fehler: Probleme auf Client-Seite, etwa fehlerhafte Anfragen oder fehlende Berechtigungen.
- 5xx-Fehler: Probleme auf Server-Seite, etwa Anwendungsabstürze oder Fehlkonfigurationen.
Sobald ein Vermittler wie der ALB die Client-Anfragen an die Backend-Anwendung weiterleitet, wird die Fehlersuche allerdings etwas anspruchsvoller.
Im ersten Schritt gilt es, den konkreten HTTP-Fehler zu identifizieren, den der Nutzer meldet. Häufig ist diese Information direkt im Browser oder in der Anwendung sichtbar. Falls nicht, helfen die Developer Tools dabei, den Fehlercode aufzudecken. Bei mobilen Anwendungen, in denen die Debugging-Möglichkeiten auf Client-Seite begrenzt sind, liefert der elb_status_code in den ALB-Access Logs präzise Informationen zum aufgetretenen Fehler.
Der nächste – und wichtigste – Schritt im Troubleshooting besteht darin, die Fehlerquelle einzugrenzen: Stammt der Fehler vom ALB selbst oder vom Backend?
Um HTTP-Fehlercodes zu erkennen, die vom Target erzeugt wurden, prüfen Sie die CloudWatch-Metriken HTTPCode_Target_4XX_Count und HTTPCode_Target_5XX_Count auf Anstiege. Stammt der Fehler vom ALB, sehen Sie Anstiege in den Metriken HTTPCode_ELB_4XX_Count und HTTPCode_ELB_5XX_Count. Für eine genauere Analyse werfen Sie einen Blick in die Access-Log-Einträge und prüfen Sie elb_status_code sowie target_status_code, um den exakten Fehlercode zu ermitteln.
Szenario 1: Wenn sowohl
elb_status_codeals auchtarget_status_codeFehlercodes enthalten und übereinstimmen, stammt die HTTP-Fehlerantwort vom Target und der ALB hat den Fehler lediglich an den Nutzer weitergereicht.Szenario 2: Wenn
elb_status_codeeinen Fehlercode enthält,target_status_codeaber auf "-" gesetzt ist, stammt die HTTP-Fehlerantwort vom ALB – das Target hat in diesem Fall keinen HTTP-Fehlercode zurückgegeben.
http 2024-04-15T13:52:50.757968Z app/my-ALB/dc6cc9188 192.168.145.39:2347 10.0.0.1:80 -1 -1 -1 502 - 94 326 "GET http://example.com:80 HTTP/1.1" "curl/7.51.0" - - arn:aws:elasticloadbalancing:us-east-1:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337262-36d228ad5d99923122bbe354"
Im obigen Access Log steht elb_status_code auf 502 und target_status_code auf "-". Zudem stehen die Felder request_processing_time, target_processing_time und response_processing_time alle auf -1. Das bedeutet, dass der Load Balancer weder eine TCP-Verbindung aufbauen noch den SSL-Handshake mit dem registrierten Target abschließen konnte – mit dem Ergebnis, dass der ALB einen 502-Fehler erzeugt hat.
Wichtig dabei: Auch wenn der HTTP-Fehlercode auf den ersten Blick vom ALB stammt, liegt die eigentliche Ursache an anderer Stelle.
Eine vollständige Liste der vom ALB erzeugten Fehler und ihrer möglichen Ursachen finden Sie hier. In diesem Beitrag können wir nicht jeden HTTP-Fehlercode behandeln, doch lohnt es sich, die vom ALB erzeugten HTTP-502- und HTTP-504-Fehler hervorzuheben, da sie mir in der Kundenbetreuung am häufigsten begegnen.
Alle möglichen vom ALB erzeugten HTTP-502-Szenarien eingrenzen: https://repost.aws/knowledge-center/elb-alb-troubleshoot-502-errors
Alle möglichen vom ALB erzeugten HTTP-504-Szenarien eingrenzen: https://repost.aws/knowledge-center/504-error-alb
Backend-Ressourcenauslastung, Webserver-Konfiguration und externe Abhängigkeiten spielen eine wesentliche Rolle und können sporadische oder dauerhafte 502/504-Fehler verursachen. Dieser AWS-Beitrag listet einige nützliche Befehle auf, um den Backend-Zustand zu analysieren und zu debuggen.
Unabhängig davon, wer den HTTP-Fehler erzeugt, lohnt es sich oft, Anfragen Ende-zu-Ende nachzuverfolgen. Mit dem Logging des Headers X-Amzn-Trace-Id können Sie Anfragen durch ALB und Webserver hindurch verfolgen. Indem Sie den eindeutigen Header in den Access Logs des ALB und des Backends abgleichen, erhalten Sie volle Transparenz über jede Anfrage, die der ALB verarbeitet.
Und schließlich: Stellen Sie sich immer die richtigen Fragen. Betrifft der Fehler einen einzelnen Nutzer oder viele? Tritt er sporadisch oder dauerhaft auf? Gibt es ein Muster? Ist ein bestimmter URI/Host betroffen oder mehrere? Tritt er auf einem einzelnen Target auf oder auf mehreren?
Unerwartete Latenz
Latenz ist die Zeit, die eine Anwendung benötigt, um auf Nutzer-Anfragen zu antworten. Hohe Latenz kann Performance und Nutzererlebnis Ihrer Anwendung erheblich beeinträchtigen.
Der Netzwerk-Bereich der Browser-Developer-Tools mit verschiedenen Verbindungs-Timern.
Beim Troubleshooting von Latenzproblemen ist es wichtig zu klären, ob das Problem auf Layer 3/4 (TCP/IP) oder Layer 7 (Application) liegt – und ob es vom ALB oder von der Backend-Anwendung verursacht wird.
Der folgende Befehl sendet HTTP-Anfragen an einen Backend-Server unter http://backendip:port, verwirft die Antworten und gibt verschiedene Timing-Metriken sowie den HTTP-Statuscode für jede Anfrage aus. So lassen sich Performance und Zustand der Anwendung anhand von Verbindungszeit, Redirect-Zeit und gesamter Anfragedauer messen. Führen Sie den Befehl separat gegen die Backend-Server und gegen die ALB-Domain aus, um Timing-Anomalien zu identifizieren.
for ((i = 1; i <= 10; i++)); do curl -w "http_code:%{http_code}\t time_connect=%{time_connect}\t time_redirect=%{time_redirect}\t time_pretransfer=%{time_pretransfer}\t time_starttransfer=%{time_starttransfer}\t time_total=%{time_total}\n\n" -o /dev/null -k -s http://backendip:port -o /dev/null ; done
ALB oder Backend: Die CloudWatch-Metrik TargetResponseTime misst die Zeit von dem Moment, in dem eine HTTP-Anfrage den Load Balancer verlässt, bis eine Antwort vom Target eingeht. Diese Metrik gibt Aufschluss über die Backend-Latenz. Sehen Sie Spitzen in den Durchschnitts- oder Maximalwerten, ist die unerwartete Latenz mit hoher Wahrscheinlichkeit durch das Backend verursacht.
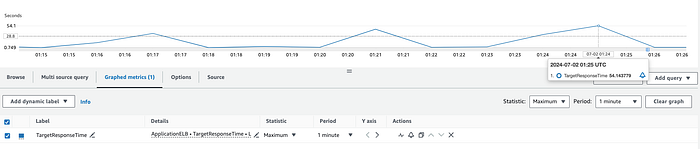
Nicht optimiertes Backend, das nach ca. 54 Sekunden auf die HTTP-Anfrage antwortet.
Um die Verarbeitungszeit einzelner Anfragen genauer zu untersuchen, schauen Sie sich die Felder request_processing_time und target_processing_time in den ALB-Access-Logs sowie die im Webserver-Log erfasste Backend-Verarbeitungszeit an.
request_processing_time – die Zeit von dem Moment, in dem der Load Balancer die Anfrage vom Client empfangen hat, bis er sie an ein Target weitergeleitet hat.
target_processing_time – die Zeit von dem Moment, in dem der Load Balancer die Anfrage an ein Target gesendet hat, bis das Target begonnen hat, die Response-Header zu senden.
Eine Analyse dieser Metriken hilft Ihnen, die Quelle von Latenzproblemen genau einzugrenzen.
Idealerweise sollte die im Backend protokollierte Antwortzeit (Backend-Verarbeitungszeit) der target_processing_time entsprechen. Ist das nicht der Fall, entspricht die Differenz der Netzwerk-Latenz zwischen ALB und Backend. Wie bereits erwähnt, kann eine hohe target_processing_time auf ein überlastetes oder nicht optimiertes Backend oder auf Probleme mit externen Abhängigkeiten hindeuten.
Eine hohe request_processing_time deutet hingegen auf Probleme mit dem ALB selbst hin. Bedenken Sie auch die Latenz, die durch Backchannel-Anfragen an AWS WAF und Identity Provider entstehen kann, wenn der ALB die Benutzerauthentifizierung übernimmt.
Zusammenfassung
Dieser Beitrag beleuchtet Best Practices für das Troubleshooting von AWS ALBs mit Fokus auf häufige Probleme wie Verbindungsstörungen, HTTP-Fehler und unerwartete Latenz. Er zeigt einen strukturierten Ansatz – kombiniert mit Kommandozeilen-Tools und nativen AWS-Observability-Werkzeugen –, um die eigentlichen Ursachen dieser Probleme zu isolieren und zu identifizieren. In künftigen Beiträgen widmen wir uns einzelnen ALB-Funktionen und ihren spezifischen Troubleshooting-Methoden.
Wenn Sie mehr erfahren möchten oder Interesse an unseren Services haben, sprechen Sie uns gerne an. Sie erreichen uns hier.