Load Balancer de Capa 7 que distribuye solicitudes HTTP(s).
El Application Load Balancer ( ALB) de Amazon Web Services (AWS) es una herramienta potente para gestionar el tráfico entrante hacia tus aplicaciones. Si tu aplicación se cae detrás de un ALB, puedes sufrir pérdida de ingresos, insatisfacción de los clientes, interrupciones operativas e incluso daños a la reputación de tu marca. Cuando aparecen problemas, un troubleshooting efectivo es clave para mantener un rendimiento y una disponibilidad óptimos.
En este artículo vamos a repasar las mejores prácticas para hacer troubleshooting del Application Load Balancer y resolver los problemas de forma eficiente y efectiva.
Alcance
Los ALB de AWS ofrecen una amplia variedad de funcionalidades, y cada una requiere su propia metodología de troubleshooting. Aunque este artículo no puede cubrir cada función al detalle, tengo pensado abordarlas en publicaciones dedicadas más adelante. Por ahora, me voy a enfocar en los problemas más comunes que me he encontrado al apoyar a clientes.
- Problemas de conectividad.
- Errores relacionados con HTTP.
- Latencia inesperada.
El objetivo de esta publicación es orientarte en la dirección correcta, invitándote a analizar el problema desde distintos ángulos y a profundizar hasta dar con la causa raíz.
Con herramientas y conocimientos básicos puedes armar una estrategia sólida de troubleshooting para funcionalidades avanzadas del ALB como autenticación de usuarios, gRPC y session stickiness.
Vamos directo al grano
Un troubleshooting estructurado es clave para llegar a la causa raíz de un problema, ya que aporta un enfoque sistemático para identificar, analizar y resolver incidentes de forma eficiente. Vamos a abordar estos problemas uno por uno:
Problemas de conectividad
Timeout de conexión TCP.
Puede que los clientes no logren acceder de ninguna forma a tu aplicación detrás del ALB. En esos casos, el troubleshooting debe centrarse en la conexión frontend. Antes que nada, te explico la diferencia entre conexiones frontend y backend:
Las conexiones frontend describen cómo los clientes interactúan con el ALB. Los clientes —navegadores y aplicaciones— resuelven el DNS del ALB a direcciones IP y luego le envían solicitudes. Los listeners del ALB atienden las solicitudes entrantes con los protocolos y puertos especificados.
Las conexiones backend describen cómo el ALB enruta el tráfico hacia tus aplicaciones. El ALB reenvía las solicitudes a los target groups, que pueden incluir instancias EC2, contenedores o direcciones IP. Realiza health checks para verificar que los targets estén sanos y puedan atender las solicitudes, y luego distribuye el tráfico entrante de forma uniforme entre esos targets sanos.
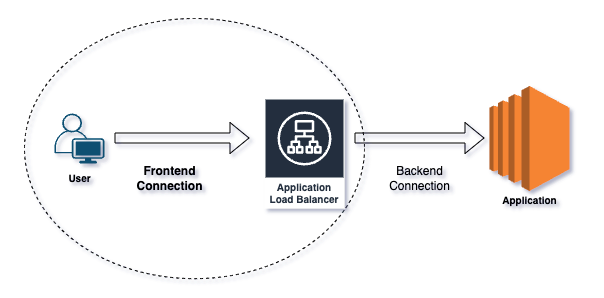
Conexión frontend vs backend.
- Hazte las preguntas correctas: ¿timeout o reset de TCP?
Un timeout indica que el ALB nunca recibió tu solicitud o nunca devolvió una respuesta, mientras que un reset indica que el ALB sí respondió, pero de forma inesperada.
¿Te suena ese clásico "no me puedo conectar"? — Para entender los problemas de conectividad, empieza ejecutando curl o telnet contra el puerto del listener e interpreta la salida. También puedes usar herramientas como Postman o acceder directamente a la URL de la aplicación desde un navegador.
Los resets de conexión pueden producirse por intentos contra el puerto de listener equivocado o por configuraciones de firewall del lado del cliente.
Entre las posibles causas de los timeouts de conexión están un ALB internet-facing colocado en una subnet privada, problemas de enrutamiento entre los clientes y las subnets del ALB, o restricciones impuestas por las Network ACL/Security Groups de AWS.
Para los errores de SSL handshake, apóyate en los comandos de OpenSSL y Curl para ubicar el problema, y monitorea la métrica ClientTLSNegotiationErrorCount de CloudWatch en busca de incrementos que indiquen incompatibilidades de cifrado o fallas en la verificación del certificado del cliente.
openssl s_client -connect
: curl -iv https://server:port
- Intermitente o constante: determina si el problema es intermitente o persistente resolviendo el DNS del ALB y probando conexiones contra sus IP.
- No olvides los fundamentos: los Security Groups, las Network ACL y las Route Tables pueden provocar timeouts. Asegúrate de que todas las subnets del ALB tengan rutas adecuadas hacia el Internet Gateway en despliegues internet-facing, o el enrutamiento correcto para load balancers internos según la ubicación del usuario (Direct Connect, Transit Gateway, VPN).
- Logging y monitoreo: los errores de TCP/SSL no quedan registrados en los access logs, pero sí se capturan en los VPC flow logs y los connection logs.
- Pocos usuarios o todos: piensa si el problema afecta a todos los usuarios o solo a ubicaciones específicas; el origen puede estar en la red interna del cliente o en problemas de enrutamiento del ISP.
- El ALB no es ideal para conexiones de larga duración: el ALB es aprovisionado, gestionado y mantenido por AWS. Las IP del ALB son dinámicas y cambian cada cierto tiempo. Esto puede ocurrir cuando el ALB necesita escalar para atender la demanda o cuando falla el host subyacente sobre el que se ejecuta su software. Como consecuencia, el ALB modifica la configuración de hardware y de red para recuperarse de las fallas, y las conexiones de larga duración terminan rompiéndose. Para este caso de uso considera NLB.
- Que los clientes respeten el TTL del DNS: ahora que sabemos que el ALB puede cambiar de direcciones IP, los clientes que se conectan a él deberían respetar el TTL y volver a resolver el DNS para obtener los valores más recientes. Si los clientes mantienen la entrada DNS en caché demasiado tiempo o tienen las IP hardcoded, en algún momento la conexión se va a romper.
Errores relacionados con HTTP
Aplicación respondiendo con un código de error HTTP 500.
Los errores HTTP, como los códigos de estado 4xx y 5xx, indican problemas en las solicitudes del cliente o en las respuestas del servidor. Puedes consultar la lista completa de respuestas de error HTTP en este enlace. En general:
- Errores 4xx: problemas del lado del cliente, como solicitudes mal formadas o accesos no autorizados.
- Errores 5xx: problemas del lado del servidor, como caídas de la aplicación o errores de configuración.
La cosa se complica un poco cuando hay un intermediario como el ALB haciendo proxy de las solicitudes del cliente hacia la aplicación de backend.
El primer paso es identificar el error HTTP concreto que está reportando el usuario. Muchas veces esa información se ve directamente en el navegador o en la aplicación del cliente. Cuando no es evidente, las developer tools ayudan a descubrir el código de error. En aplicaciones móviles, donde las opciones de depuración del lado del cliente son limitadas, revisar el campo elb_status_code en los access logs del ALB ofrece detalles precisos sobre el error.
El siguiente paso, y el más importante, es aislar el origen del error: determinar si proviene del ALB o del backend.
Para identificar los códigos de respuesta de error HTTP generados por el target, revisa los incrementos en las métricas de CloudWatch HTTPCode_Target_4XX_Count y HTTPCode_Target_5XX_Count. Si el error se originó en el ALB, verás incrementos en las métricas HTTPCode_ELB_4XX_Count y HTTPCode_ELB_5XX_Count. Para un análisis más detallado, examina las entradas del access log y revisa los valores de elb_status_code y target_status_code para determinar el código de error exacto.
Escenario 1: si tanto
elb_status_codecomotarget_status_codecontienen códigos de error y coinciden, la respuesta de error HTTP se originó en el target y el ALB simplemente la transmitió al usuario.Escenario 2: si
elb_status_codecontiene un código de error perotarget_status_codeaparece como "-", la respuesta de error HTTP se originó en el ALB, lo que indica que el target no respondió con un código de error HTTP.
http 2024-04-15T13:52:50.757968Z app/my-ALB/dc6cc9188 192.168.145.39:2347 10.0.0.1:80 -1 -1 -1 502 - 94 326 "GET http://example.com:80 HTTP/1.1" "curl/7.51.0" - - arn:aws:elasticloadbalancing:us-east-1:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337262-36d228ad5d99923122bbe354"
En el access log de arriba, elb_status_code es 502 y target_status_code es "-". Además, los campos request_processing_time, target_processing_time y response_processing_time están todos en -1. Esto significa que el load balancer no logró establecer una conexión TCP ni completar un SSL handshake con su target registrado, y por eso el ALB generó un error 502.
Lo que quiero resaltar es que, aunque el código de error HTTP parece originarse en el ALB, el problema de fondo está en otra parte.
Puedes consultar la lista completa de errores generados por el ALB y sus posibles causas en este enlace. No podemos cubrir cada código de error HTTP en este post, pero vale la pena destacar los errores HTTP 502 y HTTP 504 originados por el ALB, ya que están entre los problemas más comunes que me he encontrado al apoyar a clientes.
Aísla todos los posibles escenarios de HTTP 502 generados por el ALB: https://repost.aws/knowledge-center/elb-alb-troubleshoot-502-errors
Aísla todos los posibles escenarios de HTTP 504 generados por el ALB: https://repost.aws/knowledge-center/504-error-alb
El uso de recursos del backend, la configuración del servidor web y las dependencias externas tienen un peso importante y pueden derivar en errores 502/504 intermitentes o constantes. Esta publicación de AWS lista comandos útiles para analizar y depurar la salud del backend.
Sin importar quién genere el error HTTP, conviene rastrear las solicitudes de extremo a extremo. Registrar el X-Amzn-Trace-Id te permite seguir las solicitudes a través del ALB y de tus servidores web. Al cruzar este header único entre los access logs del ALB y del backend, obtienes visibilidad completa sobre cada solicitud que pasa por el ALB.
Para terminar, recuerda hacerte siempre las preguntas correctas: ¿el error afecta a un solo usuario o a muchos? ¿Es intermitente o constante? ¿Hay algún patrón? ¿Involucra una URI/host específica o varias? ¿Sucede en un solo target o en varios?
Latencia inesperada
La latencia es el tiempo que tarda la aplicación en responder a las solicitudes del usuario. Una latencia alta puede afectar gravemente el rendimiento y la experiencia de usuario de tu aplicación.
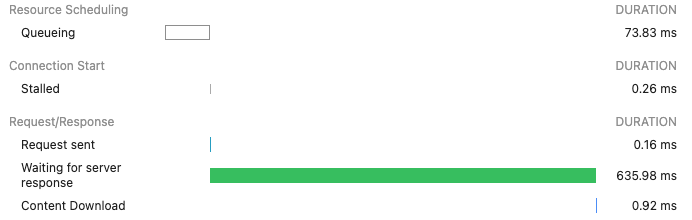
Sección de red de las developer tools del navegador mostrando distintos timers de conexión.
Al hacer troubleshooting de problemas de latencia, es importante determinar si el problema está en la Capa 3/4 (TCP/IP) o en la Capa 7 (Aplicación), y si lo causa el ALB o la aplicación de backend.
El siguiente comando envía solicitudes HTTP a un servidor de backend en http://backendip:port, descarta las respuestas e imprime varias métricas de tiempo y el código de estado HTTP de cada solicitud. De este modo se mide el rendimiento y la salud de la aplicación, con detalles como el tiempo de conexión, el tiempo de redirección y la duración total de la solicitud. Ejecuta el comando por separado contra los servidores de backend y contra el dominio del ALB para detectar cualquier anomalía en los tiempos.
for ((i = 1; i <= 10; i++)); do curl -w "http_code:%{http_code}\t time_connect=%{time_connect}\t time_redirect=%{time_redirect}\t time_pretransfer=%{time_pretransfer}\t time_starttransfer=%{time_starttransfer}\t time_total=%{time_total}\n\n" -o /dev/null -k -s http://backendip:port -o /dev/null ; done
ALB o backend: la métrica de CloudWatch TargetResponseTime mide el tiempo desde que una solicitud HTTP sale del load balancer hasta que llega la respuesta del target. Esta métrica refleja la latencia del backend. Si ves picos en las estadísticas de promedio o máximo, lo más probable es que la latencia inesperada provenga del backend.
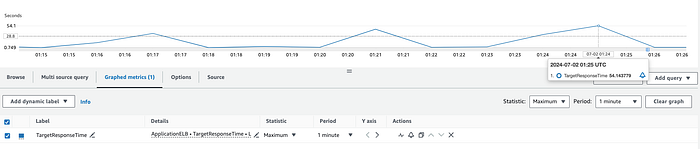
Backend no optimizado respondiendo a la solicitud HTTP después de unos 54 segundos.
Para profundizar en el tiempo de procesamiento de cada solicitud, examina request_processing_time y target_processing_time en los access logs del ALB, así como el tiempo de procesamiento del backend registrado en los logs del servidor web.
request_processing_time: el tiempo desde que el load balancer recibió la solicitud del cliente hasta que la envió al target.
target_processing_time: el tiempo desde que el load balancer envió la solicitud al target hasta que el target empezó a enviar los headers de respuesta.
Analizar estas métricas te ayudará a identificar dónde se están produciendo los problemas de latencia.
Idealmente, el tiempo de respuesta registrado en el backend (tiempo de procesamiento del backend) debería coincidir con el target_processing_time. Si no coincide, la diferencia corresponde a la latencia de red entre el ALB y el backend. Como ya mencionamos, un target_processing_time alto puede indicar un backend sobrecargado o no optimizado, o bien problemas con dependencias externas.
Por otro lado, un request_processing_time alto apunta a problemas en el propio ALB. Ten en cuenta la latencia que pueden introducir las solicitudes de backchannel hacia AWS WAF y los proveedores de identidad cuando se hace autenticación de usuarios en el ALB.
Resumen
Esta publicación repasa las mejores prácticas para hacer troubleshooting de los AWS ALB, con foco en problemas comunes como fallas de conectividad, errores relacionados con HTTP y latencia inesperada. Defiende un enfoque estructurado, apoyado en utilidades de línea de comandos y en herramientas nativas de observabilidad de AWS, para aislar e identificar las causas raíz de estos problemas. En próximas publicaciones profundizaremos en funcionalidades específicas del ALB y en sus metodologías de troubleshooting.
Si quieres saber más o te interesan nuestros servicios, no dudes en escribirnos. Puedes contactarnos aquí.