Load Balancer de niveau 7 chargé de distribuer les requêtes HTTP(s).
L'Application Load Balancer ( ALB) d'Amazon Web Services (AWS) est un outil puissant pour gérer le trafic entrant vers vos applications. Une indisponibilité de votre application derrière un ALB peut entraîner une perte de revenus, une insatisfaction client, des perturbations opérationnelles, voire nuire à la réputation de votre marque. Lorsqu'un incident survient, un dépannage efficace est indispensable pour préserver des performances et une disponibilité optimales.
Dans cet article, nous passons en revue les bonnes pratiques de dépannage de l'Application Load Balancer pour vous aider à traiter les incidents avec rigueur et efficacité.
Périmètre
Les ALB AWS proposent un large éventail de fonctionnalités, chacune appelant une méthodologie de dépannage spécifique. Cet article ne pourra pas toutes les détailler ; je leur consacrerai des billets dédiés à l'avenir. Pour l'heure, je me concentre sur les problèmes les plus fréquents rencontrés auprès des clients que j'accompagne.
- Problèmes de connectivité.
- Erreurs liées au protocole HTTP.
- Latence inattendue.
L'objectif de ce billet est de vous mettre sur la bonne piste, en vous incitant à examiner le problème sous différents angles et à creuser pour en identifier la cause racine.
En vous appuyant sur quelques outils et notions de base, vous pourrez bâtir une stratégie de dépannage solide pour les fonctionnalités avancées des ALB telles que l'authentification utilisateur, gRPC ou la persistance de session.
Entrons dans le vif du sujet
Un dépannage structuré est essentiel pour remonter à la cause racine d'un problème : il fournit une démarche systématique pour repérer, analyser et résoudre les incidents efficacement. Abordons ces problèmes un par un :
Problèmes de connectivité
Délai d'expiration de la connexion TCP.
Vos clients peuvent rencontrer une inaccessibilité totale de votre application derrière l'ALB. Dans ce cas, le dépannage doit se concentrer sur la connexion frontend. Commençons par clarifier la différence entre connexions frontend et backend :
Les connexions frontend désignent la façon dont les clients interagissent avec l'ALB. Les clients (navigateurs, applications), après avoir résolu le DNS de l'ALB en adresses IP, envoient leurs requêtes à l'ALB. Les listeners de l'ALB traitent les requêtes entrantes selon les protocoles et ports configurés.
Les connexions backend désignent la façon dont l'ALB achemine le trafic vers vos applications. L'ALB transmet les requêtes aux target groups, qui peuvent regrouper des instances EC2, des conteneurs ou des adresses IP. Il effectue des health checks pour s'assurer que les cibles sont saines et capables de traiter les requêtes, puis répartit uniformément le trafic entrant entre ces cibles saines.
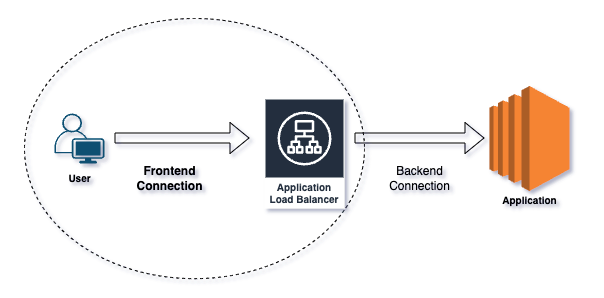
Connexion frontend vs backend.
- Posez les bonnes questions : timeout TCP ou reset ?
Un timeout signifie que l'ALB n'a jamais reçu votre requête ou n'a jamais renvoyé de réponse, tandis qu'un reset indique que l'ALB a bien répondu, mais de manière inattendue.
Vous avez déjà entendu un *Je n'arrive pas à me connecter* ? — Pour comprendre les problèmes de connectivité, commencez par exécuter curl ou telnet sur le port du listener et analysez la sortie. Vous pouvez également utiliser des outils comme Postman ou accéder directement à l'URL de l'application depuis un navigateur.
Les resets de connexion peuvent provenir d'une tentative sur un mauvais port de listener ou de paramètres de pare-feu côté client.
Côté timeouts de connexion, les causes possibles incluent un ALB internet-facing placé dans un sous-réseau privé, des problèmes de routage entre les clients et les sous-réseaux de l'ALB, ou des restrictions imposées par les Network ACLs / Security Groups d'AWS.
Pour les erreurs de SSL handshake, utilisez les commandes OpenSSL et Curl pour cibler les problèmes, et surveillez la métrique CloudWatch ClientTLSNegotiationErrorCount : toute hausse signale des incompatibilités de chiffrement ou des échecs de vérification du certificat client.
openssl s_client -connect
: curl -iv https://server:port
- Intermittent ou permanent : déterminez si le problème est intermittent ou persistant en résolvant le DNS de l'ALB et en testant les connexions vers ses IP.
- N'oubliez pas les fondamentaux : les Security Groups, Network ACLs et tables de routage peuvent provoquer des timeouts. Vérifiez que tous les sous-réseaux de l'ALB disposent de routes adéquates vers la passerelle Internet pour les déploiements internet-facing, ou d'un routage adapté pour les load balancers internes selon la localisation des utilisateurs (Direct Connect, Transit Gateway, VPN).
- Logging et monitoring : les erreurs TCP/SSL ne sont pas enregistrées dans les access logs, mais elles apparaissent dans les VPC flow logs et les connection logs.
- Quelques utilisateurs ou tous : regardez si les problèmes touchent l'ensemble des utilisateurs ou seulement certaines zones géographiques ; ils peuvent provenir du réseau interne d'un client ou du routage de son FAI.
- L'ALB n'est pas adapté aux connexions de longue durée : l'ALB est provisionné, géré et maintenu par AWS. Ses adresses IP sont dynamiques et changent régulièrement. Cela peut survenir lorsque l'ALB doit monter en charge pour absorber la demande, ou si l'hôte sous-jacent sur lequel le logiciel ALB est déployé tombe en panne. L'ALB modifie alors sa configuration matérielle et réseau pour se rétablir. Les connexions de longue durée finiront donc par être rompues. Pour ce cas d'usage, envisagez plutôt le NLB.
- Clients respectant le TTL DNS : sachant que l'ALB peut changer ses adresses IP, les clients qui s'y connectent doivent respecter et re-résoudre le DNS pour récupérer les valeurs les plus récentes. Si un client garde l'entrée DNS en cache trop longtemps ou code des IP en dur, la connexion finira par se rompre.
Erreurs liées au protocole HTTP
Application répondant avec un code d'erreur HTTP 500.
Les erreurs HTTP, comme les codes de statut 4xx et 5xx, signalent des problèmes côté requêtes client ou côté réponses serveur. Pour la liste complète des réponses d'erreur HTTP, consultez le lien ici. En règle générale :
- Erreurs 4xx : problèmes côté client, comme des requêtes incorrectes ou des accès non autorisés.
- Erreurs 5xx : problèmes côté serveur, comme des plantages d'application ou des erreurs de configuration.
L'analyse se complique lorsqu'un intermédiaire comme l'ALB relaie les requêtes du client vers l'application backend.
La première étape consiste à identifier l'erreur HTTP précise signalée par l'utilisateur. Cette information est souvent visible dans le navigateur ou l'application côté client. Lorsqu'elle ne saute pas aux yeux, les developer tools permettent de retrouver le code d'erreur. Pour les applications mobiles, où les options de débogage côté client sont limitées, vérifier elb_status_code dans les access logs de l'ALB fournit des détails précis sur l'erreur rencontrée.
L'étape de dépannage la plus importante qui suit consiste à isoler la source de l'erreur — déterminer si elle provient de l'ALB ou du backend lui-même.
Pour identifier les codes d'erreur HTTP générés par la cible, surveillez la progression des métriques CloudWatch HTTPCode_Target_4XX_Count et HTTPCode_Target_5XX_Count. Si l'erreur provient de l'ALB, ce sont les métriques HTTPCode_ELB_4XX_Count et HTTPCode_ELB_5XX_Count qui augmenteront. Pour une analyse plus fine, examinez les entrées des access logs concernant elb_status_code et target_status_code afin de déterminer le code d'erreur exact.
Scénario 1 : si
elb_status_codeettarget_status_codecontiennent tous deux des codes d'erreur identiques, la réponse d'erreur HTTP provient de la cible et l'ALB n'a fait que la relayer à l'utilisateur.Scénario 2 : si
elb_status_codecontient un code d'erreur mais quetarget_status_codeest défini sur "-", la réponse d'erreur HTTP provient de l'ALB, ce qui indique que la cible n'a pas répondu avec un code d'erreur HTTP.
http 2024-04-15T13:52:50.757968Z app/my-ALB/dc6cc9188 192.168.145.39:2347 10.0.0.1:80 -1 -1 -1 502 - 94 326 "GET http://example.com:80 HTTP/1.1" "curl/7.51.0" - - arn:aws:elasticloadbalancing:us-east-1:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337262-36d228ad5d99923122bbe354"
Dans l'access log ci-dessus, elb_status_code est défini sur 502 et target_status_code sur "-". Par ailleurs, les champs request_processing_time, target_processing_time et response_processing_time sont tous à -1. Cela signifie que le load balancer n'a pas pu établir de connexion TCP ni finaliser de SSL handshake avec sa cible enregistrée, d'où la génération d'une erreur 502 par l'ALB.
Le point que je tiens à souligner est qu'en apparence le code d'erreur HTTP semble venir de l'ALB, alors que le problème sous-jacent se situe en réalité ailleurs.
Pour une liste complète des erreurs générées par l'ALB et de leurs causes possibles, consultez le lien ici. Sans pouvoir couvrir tous les codes d'erreur HTTP dans ce billet, il est important de mettre en avant les erreurs HTTP 502 et HTTP 504 émises par l'ALB, qui figurent parmi les plus fréquentes que je rencontre auprès des clients.
Isoler tous les scénarios HTTP 502 possibles générés par l'ALB : https://repost.aws/knowledge-center/elb-alb-troubleshoot-502-errors
Isoler tous les scénarios HTTP 504 possibles générés par l'ALB : https://repost.aws/knowledge-center/504-error-alb
L'utilisation des ressources backend, la configuration du serveur web et les dépendances externes jouent un rôle déterminant et peuvent provoquer des erreurs 502/504 intermittentes ou récurrentes. Cet article AWS recense plusieurs commandes utiles pour analyser et déboguer la santé du backend.
Quelle que soit l'origine de l'erreur HTTP, il est souvent utile de tracer les requêtes de bout en bout. Le logging de X-Amzn-Trace-Id permet de suivre les requêtes à travers votre ALB et vos serveurs web. En recoupant cet en-tête unique entre les access logs de l'ALB et ceux du backend, vous obtenez une visibilité totale sur chaque requête traitée par l'ALB.
Enfin, gardez toujours en tête les bonnes questions : l'erreur touche-t-elle un seul utilisateur ou plusieurs ? Est-elle intermittente ou récurrente ? Y a-t-il un schéma d'erreur ? Concerne-t-elle un URI ou un hôte précis, ou plusieurs ? Survient-elle sur une seule cible ou sur plusieurs ?
Latence inattendue
La latence correspond au temps que met l'application à répondre aux requêtes des utilisateurs. Une latence élevée peut sérieusement dégrader les performances et l'expérience utilisateur de votre application.
Section réseau des developer tools du navigateur affichant les différents timers de connexion.
Lors du dépannage d'un problème de latence, il est important de déterminer s'il se situe au niveau 3/4 (TCP/IP) ou au niveau 7 (Application), et s'il est causé par l'ALB ou par l'application backend.
La commande suivante envoie des requêtes HTTP à un serveur backend sur http://backendip:port, ignore les réponses et affiche plusieurs métriques de timing ainsi que le code de statut HTTP de chaque requête. Elle permet de mesurer les performances et la santé de l'application en détaillant le temps de connexion, le temps de redirection et la durée totale de la requête. Exécutez-la séparément contre les serveurs backend et le domaine de l'ALB pour repérer toute anomalie de timing.
for ((i = 1; i <= 10; i++)); do curl -w "http_code:%{http_code}\t time_connect=%{time_connect}\t time_redirect=%{time_redirect}\t time_pretransfer=%{time_pretransfer}\t time_starttransfer=%{time_starttransfer}\t time_total=%{time_total}\n\n" -o /dev/null -k -s http://backendip:port -o /dev/null ; done
ALB ou backend : la métrique CloudWatch TargetResponseTime mesure le temps écoulé entre le départ d'une requête HTTP du load balancer et la réception de la réponse de la cible. Cette métrique reflète la latence backend. Si vous observez des pics sur la moyenne ou le maximum, la latence inattendue est probablement imputable au backend.
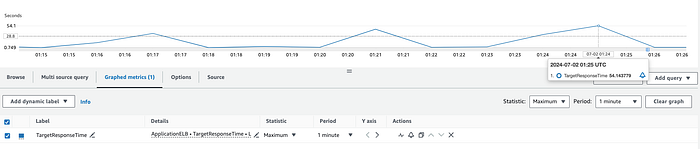
Backend non optimisé répondant à la requête HTTP au bout de ~54 secondes.
Pour approfondir l'analyse du temps de traitement de chaque requête, examinez request_processing_time et target_processing_time dans les access logs de l'ALB, ainsi que le temps de traitement backend consigné dans les logs du serveur web.
request_processing_time — le temps écoulé entre le moment où le load balancer reçoit la requête du client et celui où il la transmet à une cible.
target_processing_time — le temps écoulé entre l'envoi de la requête par le load balancer à une cible et le début de l'envoi des en-têtes de réponse par cette cible.
L'analyse de ces métriques vous permettra de localiser précisément l'origine des problèmes de latence.
Idéalement, le temps de réponse mesuré côté backend (temps de traitement backend) devrait correspondre au target_processing_time. Sinon, l'écart représente la latence réseau entre l'ALB et le backend. Comme indiqué plus haut, un target_processing_time élevé peut révéler un backend surchargé ou non optimisé, ou des problèmes liés à des dépendances externes.
À l'inverse, un request_processing_time élevé pointe vers des problèmes au niveau de l'ALB lui-même. Pensez aussi à la latence que peuvent introduire les requêtes en arrière-plan vers AWS WAF et les fournisseurs d'identité lors de l'authentification utilisateur sur l'ALB.
Synthèse
Ce billet de blog passe en revue les bonnes pratiques de dépannage des AWS ALB, en se concentrant sur les problèmes les plus courants : connectivité, erreurs liées au protocole HTTP et latence inattendue. Il met l'accent sur une approche structurée, appuyée par des utilitaires en ligne de commande et les outils d'observabilité natifs d'AWS, pour isoler et identifier la cause racine de ces incidents. Les prochains billets approfondiront des fonctionnalités spécifiques des ALB et leurs méthodologies de dépannage.
Si vous souhaitez en savoir plus ou que nos services vous intéressent, n'hésitez pas à nous contacter. Vous pouvez nous joindre ici.