Load Balancer de Camada 7 que distribui requisições HTTP(s).
O Application Load Balancer ( ALB) da Amazon Web Services (AWS) é uma ferramenta poderosa para gerenciar o tráfego de entrada das suas aplicações. Quando uma aplicação por trás de um ALB fica fora do ar, isso pode gerar perda de receita, insatisfação dos clientes, interrupções operacionais e até prejudicar a reputação da marca. Quando surgem problemas, um troubleshooting eficaz é essencial para manter o desempenho e a disponibilidade em níveis ideais.
Neste artigo, vamos explorar as boas práticas de troubleshooting do Application Load Balancer para garantir que você lide com os problemas de forma eficiente e certeira.
Escopo
Os AWS ALBs oferecem uma ampla gama de recursos, e cada um exige metodologias específicas de troubleshooting. Embora este artigo não consiga cobrir todos os recursos em detalhes, pretendo abordá-los em posts dedicados no futuro. Por enquanto, vou focar nos problemas mais comuns que encontrei ao ajudar clientes.
- Problemas de conectividade.
- Erros relacionados a HTTP.
- Latência inesperada.
O objetivo deste post é apontar o caminho certo, incentivando você a olhar o problema sob diferentes ângulos e a se aprofundar para chegar à causa raiz.
Com ferramentas e conhecimentos básicos, dá para construir uma estratégia robusta de troubleshooting até para recursos avançados do ALB, como autenticação de usuário, gRPC e session stickiness.
Vamos direto ao ponto
Um troubleshooting estruturado é essencial para chegar à causa raiz de um problema, pois oferece uma abordagem sistemática para identificar, analisar e resolver as questões com eficiência. Vamos atacar esses problemas um a um:
Problemas de conectividade
Timeout de conexão TCP.
Os clientes podem se deparar com a indisponibilidade total da sua aplicação por trás do ALB. Nesses casos, o foco do troubleshooting deve ser a conexão de frontend. Antes de mais nada, vou explicar a diferença entre conexões de frontend e backend:
Conexões de frontend dizem respeito à forma como os clientes interagem com o ALB. Os clientes, como navegadores e aplicativos, depois de resolverem o DNS do ALB para endereços IP, enviam requisições para o ALB. Listeners no ALB tratam as requisições de entrada usando protocolos e portas específicos.
Conexões de backend dizem respeito à forma como o ALB roteia o tráfego para suas aplicações. O ALB encaminha as requisições para target groups, que podem incluir instâncias EC2, contêineres ou endereços IP. Ele faz health checks para garantir que os targets estejam saudáveis e prontos para atender às requisições, e então distribui o tráfego de entrada uniformemente entre esses targets saudáveis.
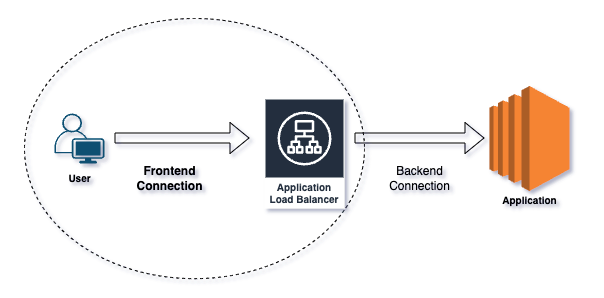
Conexão de Frontend vs Backend.
- Faça as perguntas certas: timeout de TCP ou reset?
Um timeout significa que o ALB nunca recebeu sua requisição ou nunca enviou uma resposta de volta; já um reset significa que o ALB respondeu, mas de uma forma inesperada.
Já ouviu o famoso "não consigo conectar"? — Para entender problemas de conectividade, comece rodando curl ou telnet na porta do listener e interprete o resultado. Outra opção é usar ferramentas como o Postman ou acessar a URL da aplicação diretamente no navegador.
Resets de conexão podem acontecer por tentativas na porta de listener errada ou por configurações de firewall do lado do cliente.
Entre as possíveis causas de timeouts de conexão estão um ALB internet-facing colocado em uma sub-rede privada, problemas de roteamento entre clientes e sub-redes do ALB, ou restrições impostas por Network ACLs/Security Groups da AWS.
Para erros de SSL handshake, use comandos do OpenSSL e do Curl para identificar os problemas e fique de olho na métrica do CloudWatch ClientTLSNegotiationErrorCount: aumentos indicam incompatibilidades de cifras ou falhas na verificação de certificados de cliente.
openssl s_client -connect
: curl -iv https://server:port
- Intermitente ou constante: descubra se o problema é intermitente ou persistente resolvendo o DNS do ALB e testando conexões com os IPs dele.
- Não esqueça do básico: Security Groups, Network ACLs e Route Tables podem causar timeouts. Garanta que todas as sub-redes do ALB tenham rotas adequadas para Internet Gateway em deployments internet-facing, ou roteamento correto para load balancers internos conforme a localização do usuário (Direct Connect, Transit Gateway, VPNs).
- Logging e monitoramento: erros de TCP/SSL não são registrados nos access logs, mas aparecem nos VPC flow logs e nos connection logs.
- Poucos usuários ou todos: avalie se os problemas afetam todos os usuários ou apenas localidades específicas; podem ter origem na rede interna do cliente ou em problemas de roteamento do ISP.
- O ALB não é adequado para conexões de longa duração: o ALB é provisionado, gerenciado e mantido pela AWS. Os IPs do ALB são dinâmicos e mudam de tempos em tempos. Isso pode acontecer quando o ALB precisa escalar para atender à demanda ou quando o host onde o software do ALB está implantado apresenta falhas. Como resultado, o ALB altera a configuração de hardware e rede para se recuperar das falhas. Conexões de longa duração mais cedo ou mais tarde vão cair. Considere o NLB para esse caso de uso.
- Clientes respeitando o TTL do DNS: agora que sabemos que o ALB pode mudar seus endereços IP, os clientes que se conectam a ele precisam respeitar/re-resolver o DNS para buscar os valores mais recentes. Se os clientes mantiverem a entrada de DNS em cache por muito tempo ou tiverem IPs hardcoded, um dia a conexão vai cair.
Erros relacionados a HTTP
Aplicação respondendo com um código de erro HTTP 500.
Erros HTTP, como os códigos de status 4xx e 5xx, indicam problemas nas requisições do cliente ou nas respostas do servidor. Para a lista completa de respostas de erro HTTP, consulte o link aqui. Em geral:
- Erros 4xx: problemas no lado do cliente, como bad requests ou acesso não autorizado.
- Erros 5xx: problemas no lado do servidor, como falhas na aplicação ou configurações incorretas.
A coisa pode complicar um pouco quando você tem um intermediário como o ALB fazendo o proxy das requisições do cliente para a aplicação de backend.
O primeiro passo é identificar o erro HTTP específico que o usuário está reportando. Muitas vezes, essa informação aparece no navegador ou no aplicativo do lado do cliente. Quando não está tão evidente, dá para usar as developer tools para descobrir o código de erro. Em aplicativos móveis, onde as opções de depuração no cliente são limitadas, verificar o elb_status_code nos access logs do ALB traz detalhes precisos sobre o erro encontrado.
O próximo passo mais importante do troubleshooting é isolar a origem do erro — descobrir se ele vem do ALB ou do próprio backend.
Para identificar códigos de resposta de erro HTTP gerados pelo target, verifique se há aumentos nas métricas do CloudWatch HTTPCode_Target_4XX_Count e HTTPCode_Target_5XX_Count. Se o erro veio do ALB, você verá aumentos nas métricas HTTPCode_ELB_4XX_Count e HTTPCode_ELB_5XX_Count. Para uma análise mais detalhada, examine as entradas dos access logs em busca de elb_status_code e target_status_code para chegar ao código de erro exato.
Cenário 1: se tanto
elb_status_codequantotarget_status_codecontêm códigos de erro e eles coincidem, a resposta de erro HTTP veio do target, e o ALB apenas repassou o erro ao usuário.Cenário 2: se
elb_status_codecontém um código de erro mastarget_status_codeestá como "-", a resposta de erro HTTP veio do ALB, indicando que o target não respondeu com um código de erro HTTP.
http 2024-04-15T13:52:50.757968Z app/my-ALB/dc6cc9188 192.168.145.39:2347 10.0.0.1:80 -1 -1 -1 502 - 94 326 "GET http://example.com:80 HTTP/1.1" "curl/7.51.0" - - arn:aws:elasticloadbalancing:us-east-1:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337262-36d228ad5d99923122bbe354"
No access log acima, o elb_status_code está em 502 e o target_status_code aparece como "-". Além disso, os campos request_processing_time, target_processing_time e response_processing_time estão todos em -1. Isso significa que o load balancer não conseguiu estabelecer uma conexão TCP nem completar um SSL handshake com o target registrado, fazendo com que o ALB gerasse o erro 502.
O ponto que quero destacar é que, mesmo o código de erro HTTP parecendo ter origem no ALB, o problema de fato está em outro lugar.
Para a lista completa de erros gerados pelo ALB e suas possíveis causas, consulte o link aqui. Embora não dê para cobrir todos os códigos de erro HTTP neste post, vale destacar os erros HTTP 502 e HTTP 504 originados pelo ALB, pois estão entre os problemas mais comuns que encontrei ao ajudar clientes.
Isole todos os possíveis cenários de HTTP 502 gerados pelo ALB: https://repost.aws/knowledge-center/elb-alb-troubleshoot-502-errors
Isole todos os possíveis cenários de HTTP 504 gerados pelo ALB: https://repost.aws/knowledge-center/504-error-alb
O uso de recursos do backend, a configuração do servidor web e as dependências externas têm um papel importante e podem levar a erros 502/504 intermitentes ou constantes. Este post da AWS lista alguns comandos úteis para analisar e debugar a saúde do backend.
Independentemente de quem gera o erro HTTP, vale rastrear as requisições de ponta a ponta. Logar o X-Amzn-Trace-Id permite rastrear requisições pelo seu ALB e pelos servidores web. Comparando o header único nos access logs do ALB e do backend, você ganha visibilidade completa de cada requisição tratada pelo ALB.
Por fim, lembre-se sempre de fazer as perguntas certas: o erro está afetando um único usuário ou muitos? É intermitente ou constante? Existe algum padrão? Envolve uma URI/host específico ou vários? Acontece em um único target ou em vários?
Latência inesperada
Latência é o tempo que a aplicação leva para responder às requisições do usuário. Uma latência alta pode comprometer seriamente o desempenho e a experiência do usuário na sua aplicação.
Seção de rede das developer tools do navegador exibindo diferentes timers de conexão.
No troubleshooting de problemas de latência, é importante descobrir se o problema está na Camada 3/4 (TCP/IP) ou na Camada 7 (Aplicação) e se a causa é o ALB ou a aplicação de backend.
O comando a seguir envia requisições HTTP para um servidor de backend em http://backendip:port, descarta as respostas e imprime várias métricas de tempo e o código de status HTTP de cada requisição. Isso ajuda a medir o desempenho e a saúde da aplicação, trazendo detalhes sobre tempo de conexão, tempo de redirecionamento e duração total da requisição. Rode o comando separadamente contra os servidores de backend e contra o domínio do ALB para identificar qualquer anomalia de tempo.
for ((i = 1; i <= 10; i++)); do curl -w "http_code:%{http_code}\t time_connect=%{time_connect}\t time_redirect=%{time_redirect}\t time_pretransfer=%{time_pretransfer}\t time_starttransfer=%{time_starttransfer}\t time_total=%{time_total}\n\n" -o /dev/null -k -s http://backendip:port -o /dev/null ; done
ALB ou Backend: a métrica TargetResponseTime do CloudWatch mede o tempo desde quando uma requisição HTTP sai do load balancer até quando a resposta chega do target. Essa métrica indica a latência do backend. Se você notar picos nas estatísticas de média ou máxima, a latência inesperada provavelmente vem do backend.
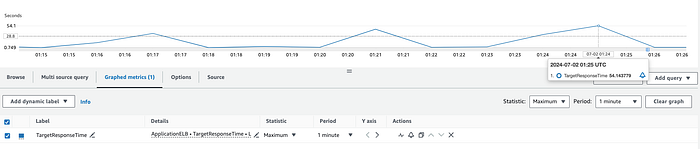
Backend não otimizado respondendo à requisição HTTP após cerca de 54 segundos.
Para investigar mais a fundo o tempo de processamento de cada requisição, examine os campos request_processing_time e target_processing_time dos access logs do ALB, além do tempo de processamento do backend registrado nos logs do servidor web.
request_processing_time — o tempo desde quando o load balancer recebeu a requisição do cliente até enviá-la ao target.
target_processing_time — o tempo desde quando o load balancer enviou a requisição ao target até o target começar a enviar os headers de resposta.
A análise dessas métricas vai te ajudar a identificar exatamente onde está o gargalo de latência.
Idealmente, o tempo de resposta registrado no backend (tempo de processamento do backend) deve ser equivalente ao target_processing_time. Caso contrário, a diferença representa a latência de rede entre o ALB e o backend. Como mencionado, um target_processing_time alto pode indicar um backend sobrecarregado ou não otimizado, ou problemas com dependências externas.
Por outro lado, um request_processing_time alto aponta para problemas no próprio ALB. Considere a latência que pode ser introduzida por requisições de backchannel para o AWS WAF e provedores de identidade ao realizar autenticação de usuário no ALB.
Resumo
Este post explora as boas práticas para fazer o troubleshooting dos AWS ALBs, com foco em problemas comuns como conectividade, erros relacionados a HTTP e latência inesperada. Ele defende uma abordagem estruturada, junto com utilitários de linha de comando e ferramentas nativas de observabilidade da AWS, para isolar e identificar as causas raiz desses problemas. Em posts futuros, vamos nos aprofundar em recursos específicos do ALB e nas metodologias para fazer o troubleshooting deles.
Se quiser saber mais ou tiver interesse nos nossos serviços, é só entrar em contato. Você pode falar com a gente aqui.