本記事は第1回の続編です。第1回では、本番規模のIoTデバイス群を安全にオンボーディングし、IoT CoreとPub/Sub経由でGoogle Cloud環境にテレメトリデータをストリーミングする方法を解説しました。
IoTデバイスの登録、お疲れさまでした。では、次のステップに進みましょう。
次に目指すべきは、データの大規模なストレージ、分析、可視化/ダッシュボード機能を備えたシステムを設計することです。

そのためには、大規模なデータ処理に耐えうるデータフローアーキテクチャを、あらかじめしっかり設計しておく必要があります。本記事では、その実装手順をハンズオン形式で解説します。
概要
本記事は以下のセクションで構成されています。
- データシンクへのバッチロード
- データの保存と分析
- データウェアハウス内データの可視化
第1回とは異なり、本記事の作業はすべてGCPのWebコンソール上で完結できます。必要なのは基本的なSQLの知識のみです。
本記事で取り上げるのは、以下のフルマネージドかつ自動スケーリング対応のGoogle Cloudサービスです。
- Pub/Sub — サーバーレスのメッセージキュー
- Dataflow — ストリーム/バッチデータ処理エンジン
- BigQuery — サーバーレスのデータウェアハウス
- Data Studio — データ可視化/ダッシュボード作成サービス
データシンクへのバッチロード
メッセージの到着を確認する
IoTレジストリへのデバイスのオンボーディングが完了し、IoT Coreへのデータストリーミングが始まっていれば、GCPのIoTメインダッシュボードでメッセージが安定して届いている様子を確認できるはずです。
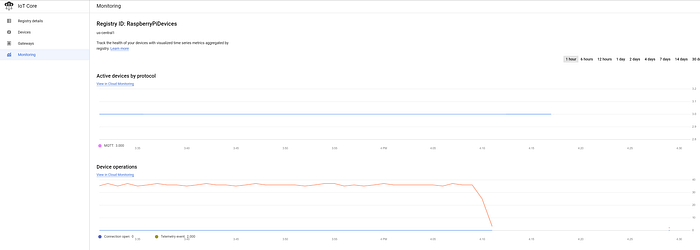
3台のデバイスが正常に接続され、5秒ごとに温度データをストリーミングしている様子
第1回で示したとおり、これらのメッセージはPub/Subトピック「temperature」にも届いています。
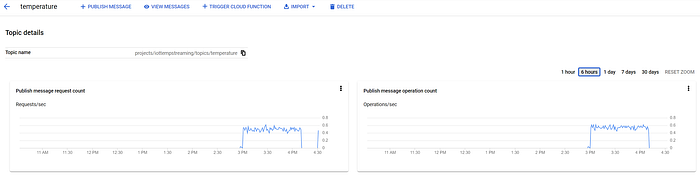
「temperature」トピックに届くPub/Subメッセージ
BigQueryへのストリーミング
これでGoogle Cloudにメッセージが届いていることを確認できました。次は、Pub/Subのメッセージをデータウェアハウスに転送し、コスト効率の高い長期保存と、容易にスケールできる分析基盤を整える必要があります。ここで登場するのがBigQueryです。
BigQueryはGoogle Cloudのフルマネージド・サーバーレス・自動スケーリング対応のデータウェアハウスで、コンピュートとストレージの両方をオンデマンド課金モデルで利用できます。IoTデータの保存・分析先として最適なデータシンクです。
では、Pub/SubのメッセージをどうやってBigQueryにストリーミングするのでしょうか。そこで使うのがDataflowです。
DataflowはApache BeamのGoogle Cloudマネージド版とも言える、フルマネージド・自動スケーリング対応のサービスで、サービス間のデータ移動を担います。データのフィルタリングや変換にも対応し、データベースやデータウェアハウスのようにロード処理に制約のあるサービスへ最適化されたバッチロードを行うこともできます。
DataflowにはGoogle Cloudが提供する複数のデフォルトテンプレートが用意されており、その中にはPub/SubからBigQueryへのテンプレートも含まれています。これにより、データ取り込みとデータ保存/分析サービスをコーディングなしで連携させられます。
Pub/Sub、Dataflow、BigQueryはいずれもフルマネージドで自動スケーリングに対応し、(Dataflowを除いて)サーバーレスでもあるため、開発時のテストからペタバイト規模の運用までシームレスに拡張できるエンドツーエンドのIoTデータ管理システムを構築できます。スケール時のインフラ管理もほぼ不要です。
では、これらのサービスを実際につないで動かしてみましょう。
Pub/Subサブスクリプションのセットアップ
Pub/SubからDataflowへのデータ移動を始める前に、Pub/Subトピックを購読するPub/Subサブスクリプションを作成しておきましょう。
なぜでしょうか。Pub/Subトピックに到着したメッセージは、Push方式では即座に購読者に送信され、トピックからは削除されます。一方Pull方式では、プロセスがメッセージを要求するまでサブスクリプション側に保持されます。Dataflowをサブスクリプションではなくトピックに直接接続することも可能ですが、その場合、Dataflowジョブがダウンしている間にトピックへ届いたメッセージは失われてしまいます。
これに対し、トピックを購読するPub/SubサブスクリプションにDataflowを接続すれば、ダウンタイム中もメッセージを失わずに済みます。Dataflowジョブが一時的に中断しても、未処理のIoTメッセージはPub/Subサブスクリプションに保持されたまま、Dataflowジョブが再開してプルし始めるのを待ちます。
つまり、Pub/SubトピックにPub/Subサブスクリプションを設けることで、下流のデータ取り込みサービスに障害が起きても影響を受けにくい、堅牢なデータアーキテクチャを構築できるのです。
Pub/Subでサブスクリプションを作成する手順:
- 「サブスクリプション」に移動
- 「サブスクリプションを作成」をクリックし、サブスクリプション名を「temperature_sub」とする
- Pub/Subトピック「temperature」を購読対象に設定
- その他のオプションはデフォルトのままにする
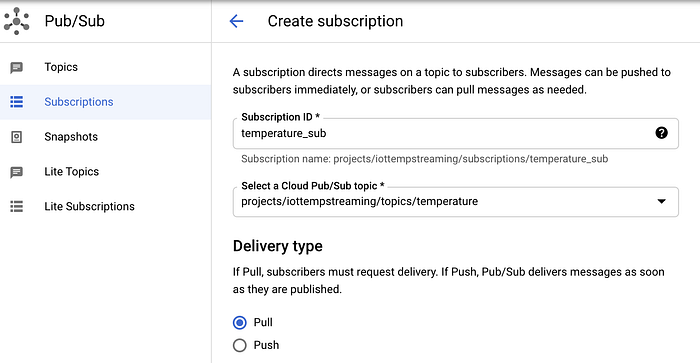
Pub/Subトピック「temperature」に対するPub/Subサブスクリプション「temperature_sub」の作成
作成後、サブスクリプションをクリックして「Pull」を押すと、メッセージが流れ込んでくる様子を確認できます。
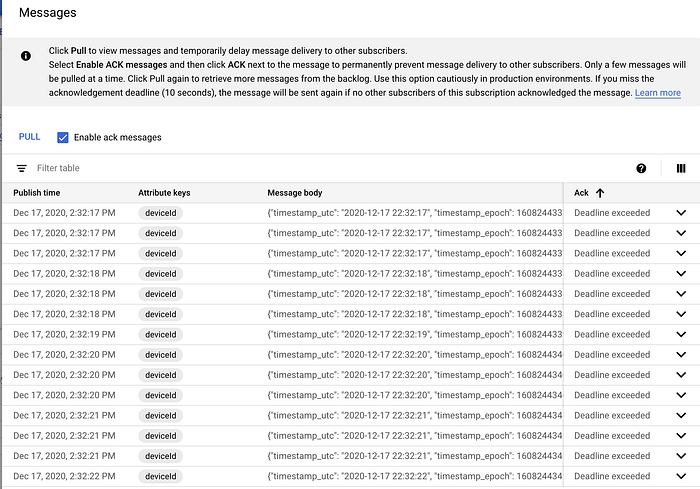
Pub/Subサブスクリプションに流入するメッセージの例
データの保存と分析
Pub/Subサブスクリプションでメッセージを受信できる状態になったので、Pub/SubメッセージをBigQueryへ移すDataflowジョブを作成する準備がほぼ整いました。その前に、Dataflowからのデータを受け取るテーブルをBigQueryに作成しておきましょう。
BigQueryテーブルのセットアップ
BigQueryに移動し、「データセットを作成」をクリックして、データセット名を「sensordata」とします。その他のオプションはデフォルトのままで構いません。
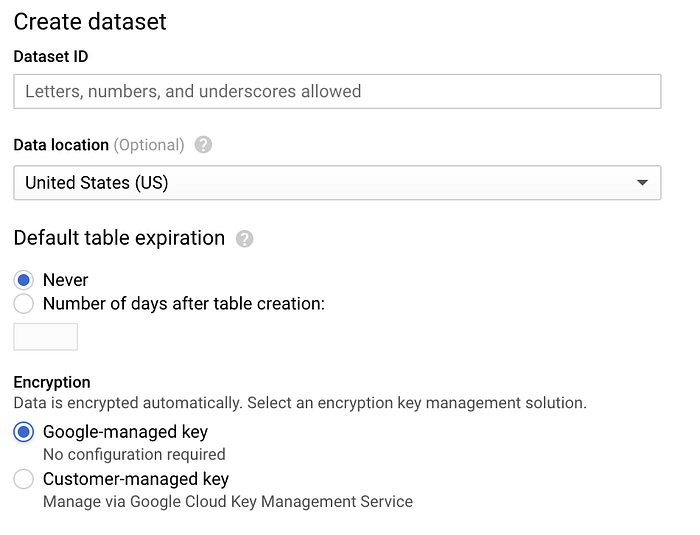
BigQueryデータセット作成画面
データセットを作成したら、それを選択して「テーブルを作成」をクリックし、新しいテーブル名を「temperature」とします。一般的なクエリパターンに対応できるよう、以下のスクリーンショットに示すスキーマ、パーティショニング、クラスタリングのオプションを必ず指定してください。
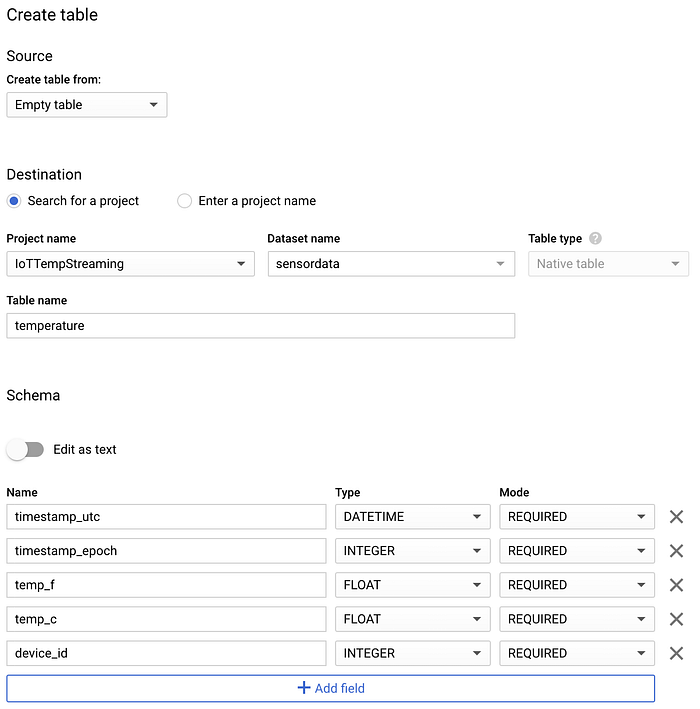
新規「temperature」BigQueryテーブルのスキーマ
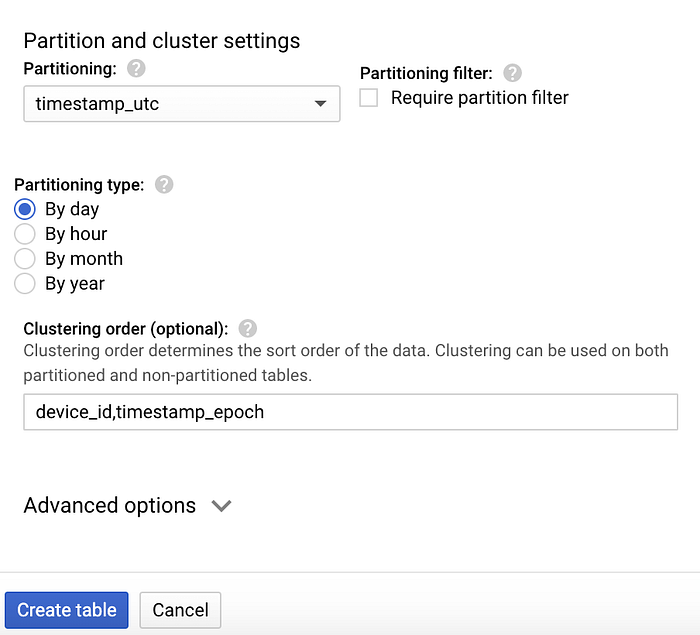
「temperature」テーブルのパーティショニングおよびクラスタリングオプション
正しく作成できれば、新しい空のテーブルは以下のように表示されます。
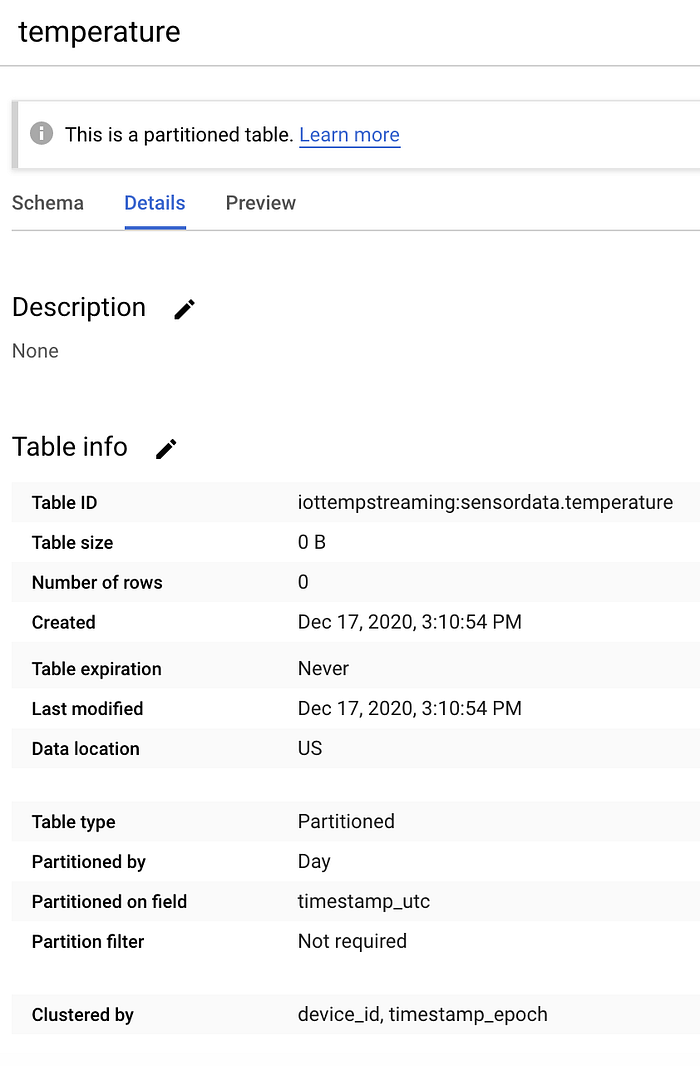
「sensordata」データセット内の空の「temperature」BigQueryテーブル
このテーブルにデータを移したあと、IoTで頻出するクエリパターン、すなわち「特定の時間枠(例:当日の1時間ウィンドウ)」かつ「特定のデバイス」に該当するデータの分析を実演します。
上記のテーブル設計がこうしたクエリに最適な理由は次のとおりです:
- UTCタイムスタンプフィールドでパーティショニングすることで、日付指定のクエリが該当しない日のDateTimeパーティションをスキャンせずに済む
- パーティション内ではdeviceIdとエポックタイムスタンプでクラスタリング(ソート)するため、特定の日付パーティション内の特定のデバイス・時間枠のデータを効率的に取得できる
これらのクエリを実行するには、テーブルにデータが必要です。さっそくDataflowジョブを動かしましょう。
Dataflowのセットアップ
現時点で、Pub/Subサブスクリプションにメッセージが溜まっており、それを受け入れる準備の整ったBigQueryテーブルがあります。あとは両者をつなぐETLの「のり」が必要です。Pub/SubもBigQueryもフルマネージド・自動スケーリング・サーバーレスなので、ETLツールにも同じ性質を求めたいところです。
Dataflowは(ほぼ)この要件を満たします。マーケティング上は3つすべてを兼ね備えていると謳われていますが、実際には完全なサーバーレスではありません。使用するインスタンスのタイプとサイズ、自動スケーリングの最小/最大インスタンス数、各インスタンスに割り当てる一時ディスク領域のサイズなどを指定する必要があります。インスタンス自体やスケーリングの判断を運用する必要はありませんが、これらのスペックは自分で指定しなければなりません。この点は、インフラ設定なしで自動スケールするPub/SubやBigQueryとは対照的です。
完全なサーバーレスではないものの、Pub/SubからBigQueryへのETL要件にDataflowはぴったりです。GCPには多数のデフォルトDataflowジョブテンプレートが用意されており、Pub/SubからBigQueryへのワークフローに対応するテンプレートもあるため、扱いも簡単です。IoTデータのスループットが時間とともに増加するのに合わせて自動スケーリングの最大許容インスタンス数を引き上げる程度で、Dataflowを支えるインフラの管理に煩わされることは基本的にないでしょう。
基本を押さえたところで、Dataflowジョブを実装してみましょう。Dataflowに移動し、「テンプレートからジョブを作成」をクリックして、以下の手順を実行します。
- ジョブ名を「pubsub-temp-to-bq」とする
- デフォルトのストリーミングテンプレート「Pub/Sub Subscription to BigQuery」を選択
- Pub/Subサブスクリプションのフルネームを入力
- BigQueryテーブルのフルIDを入力
- DataflowがBigQueryへのバッチロード処理の一環として一時データを保管できるCloud Storageバケットの場所を入力
- その他のオプションはデフォルトのままにする。通常は「詳細オプション」を展開し、使用するマシンタイプとサイズ、自動スケーリングの最小/最大マシン数、マシンあたりのディスクサイズなどを指定しますが、テスト目的であればデフォルトのままで構いません。
Dataflowジョブの作成画面は以下のようになります。
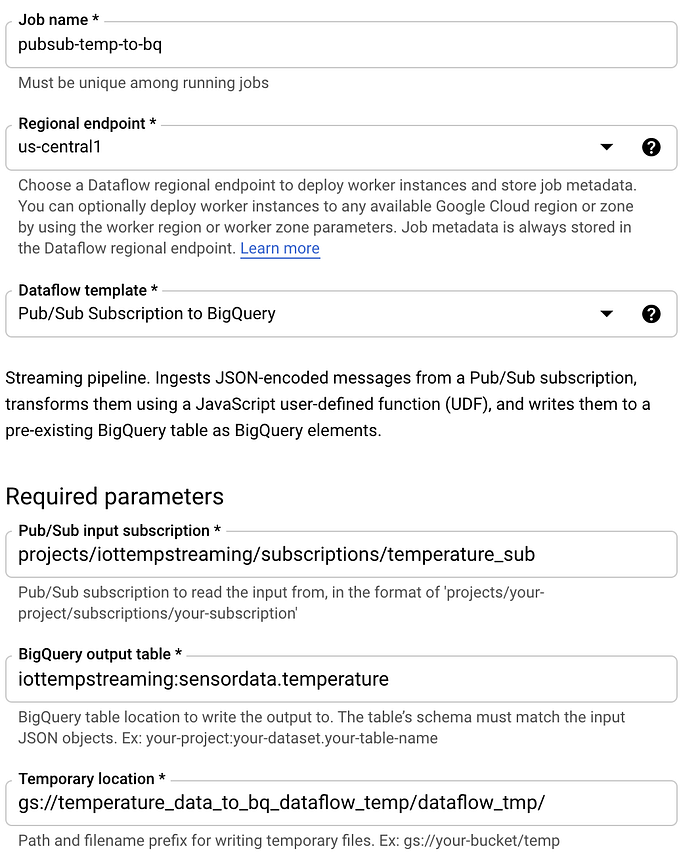
「作成」をクリックし、基盤インフラが起動して稼働を始めるまで数分待つと、Pub/Subサブスクリプションから送信先のBigQueryテーブルへとデータが流れ込む様子を確認できます。
第1回で紹介したPython製の温度ストリーミングスクリプトは、1秒あたり1レコードのペースでデータを送信します。したがって、以下のDataflowの有向非巡回グラフ(DAG)では、1秒あたりx個の要素がストリーミングされる様子が確認できるはずです(xはテストに使用しているデバイス台数)。今回の例では3台のデバイスがストリーミングしています。
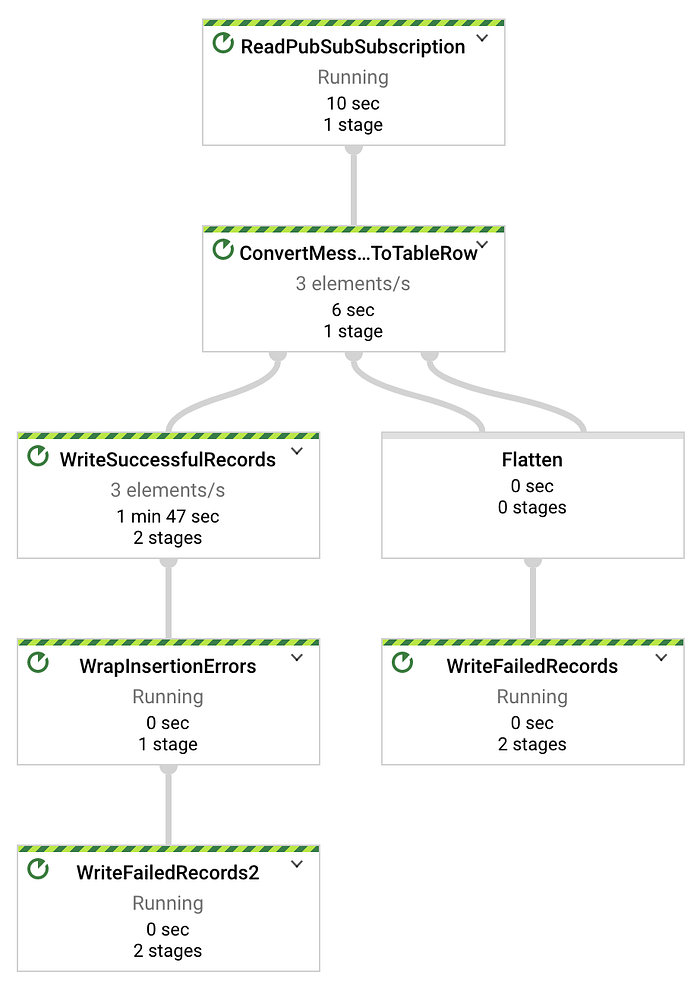
DataflowジョブによりPub/SubからBigQueryへ正常にストリーミングされるメッセージ
Dataflowジョブが稼働中で、Pub/SubサブスクリプションのデータがBigQueryに正常にストリーミングされていることを確認できたら、BigQueryで以下のような形式のクエリを実行することで、リアルタイムにテーブルへ届くデータを確認できます。
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
LIMIT 10
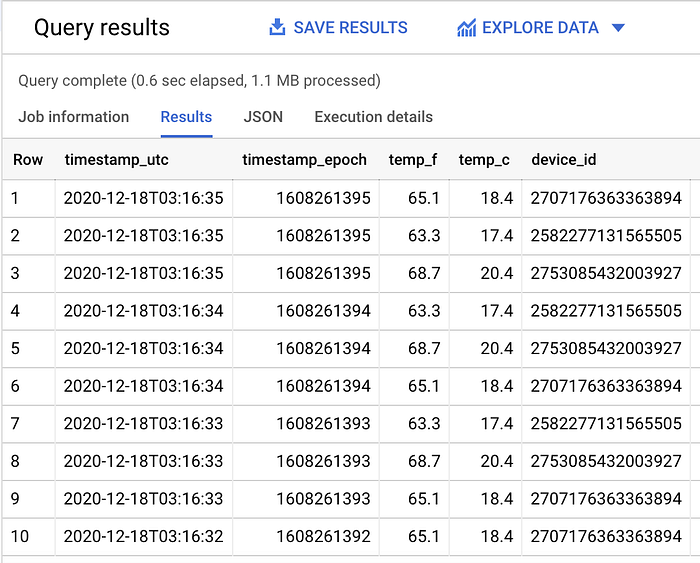
日付フィルタのWHERE句を外すとスキャン対象のデータ量が増えることから、パーティションフィルタリングが機能していることがわかります。
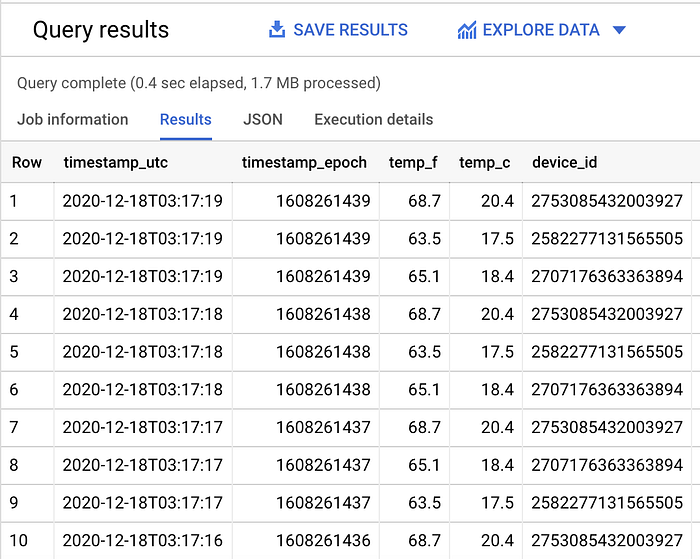
今回のサンプルデータセットでは、フィルタありで1.1MB(上記参照)、フィルタなしで1.7MB(下記参照)がスキャンされました。
SELECT *
FROM `iottempstreaming.sensordata.temperature`
ORDER BY timestamp_epoch DESC
LIMIT 10
続いて、過去1時間における各センサーの平均・最小・最大温度を見てみましょう。
SELECT
device_id,
ROUND(AVG(temp_f), 1) AS temp_f_avg,
MIN(temp_f) AS temp_f_min,
MAX(temp_f) AS temp_f_max
FROM `iottempstreaming.sensordata.temperature`
WHERE timestamp_utc > DATETIME_ADD(CURRENT_DATETIME(), INTERVAL -60 MINUTE)
GROUP BY device_id
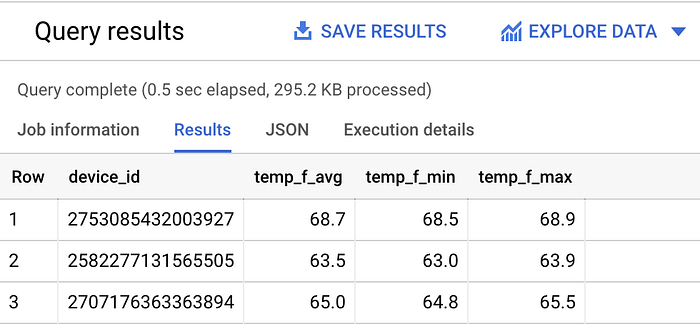
温度ストリーミングデバイスごとの各種統計値
これで、データの取り込みから分析バックエンドまで、エンドツーエンドでフルマネージドなデータワークフローが構築できました。本記事を締めくくる前に、このデータがData Studioでいかに簡単に可視化できるかを見ておきましょう。
データウェアハウス内データの可視化
まずはBigQueryで、特定の日のすべてのデータ行を取得する以下のようなクエリを実行します。
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
「クエリ結果」の右側にある「データを探索」をクリックし、続いて「Data Studioで探索」をクリックします。
これで、先ほどクエリしたデータをまとめたテーブルが読み込まれます。ただしデフォルトでは、1秒あたりのレコード総数を集計しただけの、あまり面白みのないテーブルが表示されます。
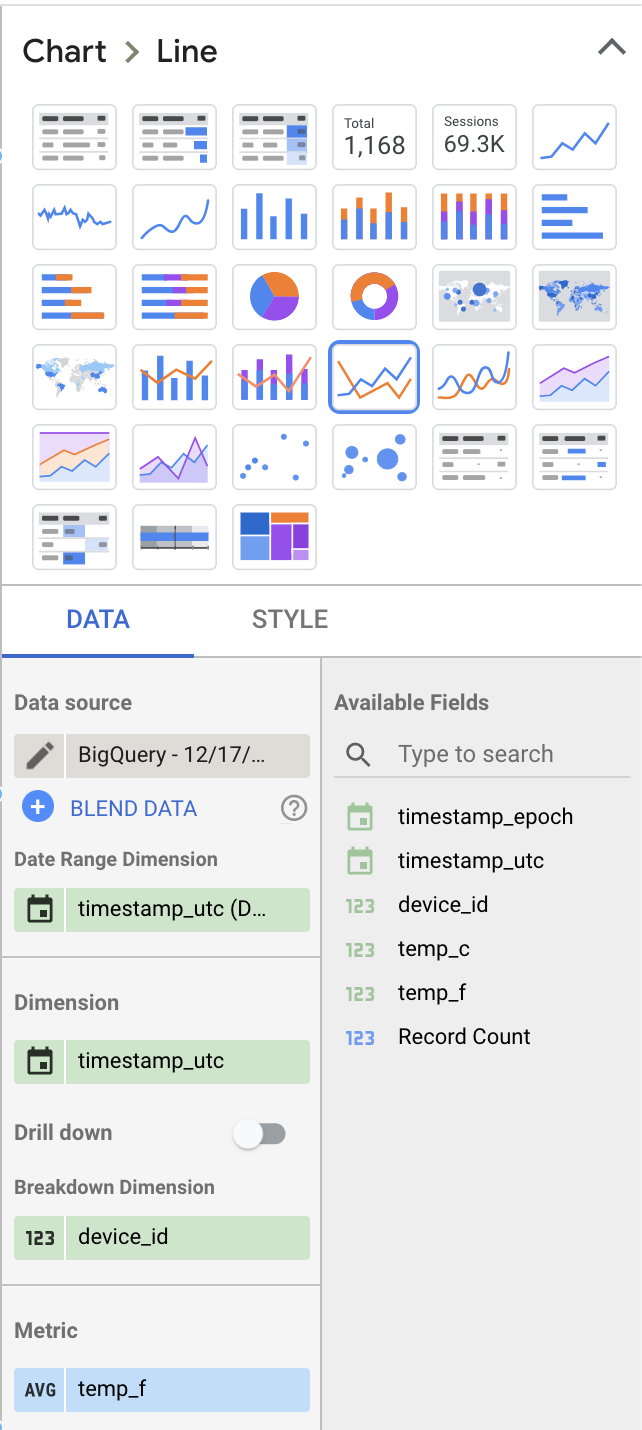
右側のデータセクションでいくつかの値を変更し、もう少し見ごたえのある内容にしましょう:
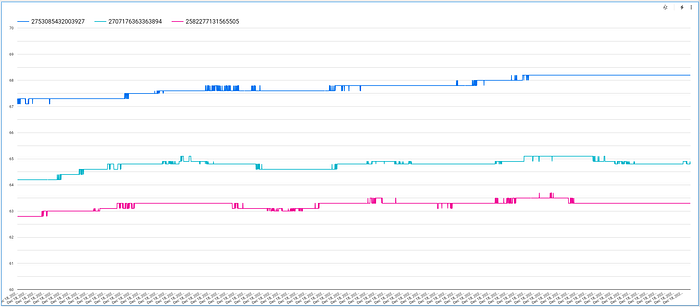
- 可視化タイプを「テーブル」ではなく「折れ線グラフ」に変更
- 表示するメトリクスから「Record Count」を削除し、代わりに「temp_f」を追加。デフォルトの「SUM」は忘れずに「AVG」に変更する
- 内訳ディメンションとして「device_id」を追加
これらの設定により、ダッシュボードのレイアウトは以下のようになるはずです。
このグラフはデバイスごとの時系列の温度値を表示しますが、Y軸の最小値がデフォルトでゼロになるため、自動スケーリングが適切でない場合があります。これを修正するには、「スタイル」タブをクリックし、「左Y軸」のオプションまでスクロールして、適切な値に変更します。

必要に応じて、グラフに表示できるデータポイントの数も増やしておきましょう。
これらの設定が完了すれば、時間とともに変動するデバイスごとの温度値をスクロールしながら確認できる、美しくインタラクティブなグラフが完成します。
次回予告:機械学習
第3回では、このBigQueryデータセット上で実用的な機械学習モデルを構築し、リアルタイムに予測を生成する方法を解説します。どうぞお楽しみに。