Este artículo es la continuación de la Parte Uno, donde repasamos cómo incorporar de forma segura una flota de dispositivos IoT a escala de producción que envía datos de telemetría a tu entorno de Google Cloud mediante IoT Core y Pub/Sub.
¡Felicitaciones! Ya registraste varios dispositivos IoT… ¿y ahora qué?
Tu siguiente objetivo debería ser diseñar un sistema que permita el almacenamiento, la analítica y la visualización/dashboarding de tus datos a gran escala.

Para lograrlo, hay que diseñar con anticipación una arquitectura de flujo de datos capaz de soportar operaciones a esa escala. Este artículo te guía paso a paso para hacerlo.
Panorama general
Esta guía se divide en las siguientes secciones:
- Carga por lotes hacia los data sinks
- Almacenamiento y análisis de datos
- Visualización de los datos almacenados
A diferencia de la primera parte, todo lo que veremos aquí se puede hacer íntegramente desde la consola web de GCP. Solo se requiere experiencia básica en SQL.
Vamos a hablar de los siguientes servicios de Google Cloud, todos totalmente administrados y con escalado automático:
- Pub/Sub: una cola de mensajes serverless
- Dataflow: un motor de procesamiento de datos en streaming y por lotes
- BigQuery: un data warehouse serverless
- Data Studio: un servicio de visualización de datos y creación de dashboards
Carga por lotes hacia los data sinks
Verifica que estén llegando los mensajes
Si ya incorporaste dispositivos al registro de IoT y empezaste a enviar datos al IoT Core, deberías ver un flujo constante de mensajes en el dashboard principal de IoT en GCP:
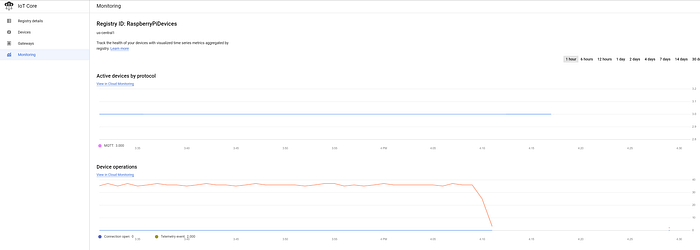
Tres dispositivos conectados con éxito que envían datos de temperatura cada cinco segundos
Como se mostró en la Parte Uno, estos mensajes también están llegando a tu topic de Pub/Sub 'temperature':
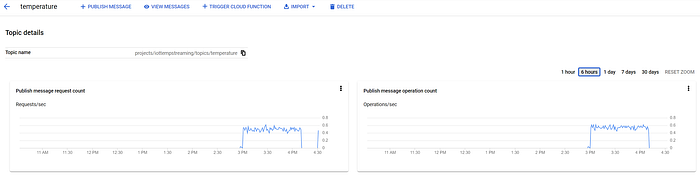
Mensajes de Pub/Sub llegando al topic 'temperature'
Streaming hacia BigQuery
Bien: los mensajes ya están llegando a Google Cloud. El siguiente paso es mover esos mensajes de Pub/Sub a un data warehouse, donde los datos puedan residir con una retención a largo plazo y a buen costo, y al mismo tiempo permitir analítica fácilmente escalable. Aquí entra BigQuery.
BigQuery, el data warehouse totalmente administrado, serverless y con escalado automático de Google Cloud, te permite pagar tanto por cómputo como por almacenamiento bajo un modelo de precios bajo demanda, lo que lo convierte en un excelente data sink para almacenar y analizar nuestros datos de IoT.
Pero ¿cómo enviamos los mensajes de Pub/Sub a BigQuery? Con Dataflow.
Dataflow, la versión totalmente administrada y con escalado automático de Apache Beam que ofrece Google Cloud, está diseñada para mover datos de un servicio a otro. Te da la posibilidad de filtrar y transformar los datos de manera opcional, además de optimizar la carga por lotes hacia servicios con límites en las operaciones de carga, como bases de datos y soluciones de data warehousing.
Dataflow incluye varias plantillas predeterminadas creadas por Google Cloud, entre ellas una de Pub/Sub a BigQuery, así que no hace falta escribir código para conectar la ingesta de datos con los servicios de almacenamiento y analítica.
Como Pub/Sub, Dataflow y BigQuery son servicios totalmente administrados y con escalado automático, y (con la excepción de Dataflow) también serverless, es posible armar un sistema de gestión de datos de IoT de extremo a extremo que escala fácilmente desde pruebas de desarrollo hasta operaciones a escala de petabytes, prácticamente sin necesidad de gestionar infraestructura a medida que se escala.
¡Veamos todos estos servicios conectados en acción!
Configuración de la suscripción de Pub/Sub
Antes de empezar a mover datos de Pub/Sub a Dataflow, conviene crear una suscripción de Pub/Sub asociada al topic.
¿Por qué? Los mensajes que llegan a un topic de Pub/Sub se envían inmediatamente a los suscriptores del topic (con una estrategia Push) y luego se eliminan del topic. En cambio, los suscriptores pueden retener los mensajes hasta que un proceso los solicite (con una estrategia Pull). Es posible conectar Dataflow directamente a un topic en lugar de a una suscripción, pero si ese job de Dataflow llegara a caerse, los mensajes que llegaran al topic durante la caída se perderían.
En cambio, al conectar Dataflow a una suscripción de Pub/Sub asociada al topic, evitas que los mensajes se pierdan durante una caída. Si un job de Dataflow se interrumpiera temporalmente, todos los mensajes de IoT que aún no se hayan procesado quedarían en la suscripción de Pub/Sub, esperando a que el job de Dataflow vuelva a tomarlos.
Una suscripción de Pub/Sub asociada a un topic genera una arquitectura de datos resiliente ante interrupciones en los servicios de ingesta downstream.
Para crear una suscripción dentro de Pub/Sub:
- Ve a Subscriptions
- Haz clic en "Create Subscription" y nombra tu suscripción "temperature_sub"
- Suscríbela al topic de Pub/Sub "temperature"
- Deja las demás opciones con sus valores predeterminados
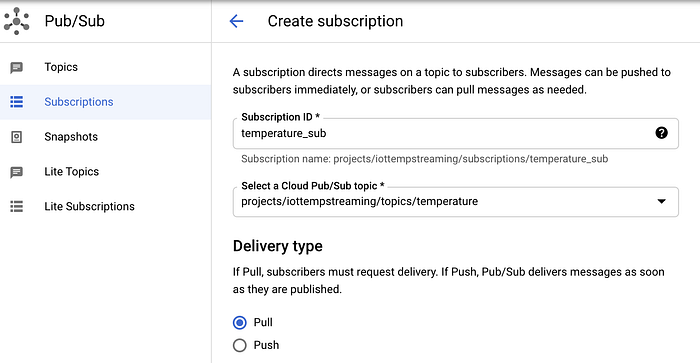
Creación de la suscripción de Pub/Sub 'temperature_sub' al topic 'temperature'
Una vez creada, si haces clic en la suscripción y luego en "Pull", deberías ver los mensajes empezando a llegar:
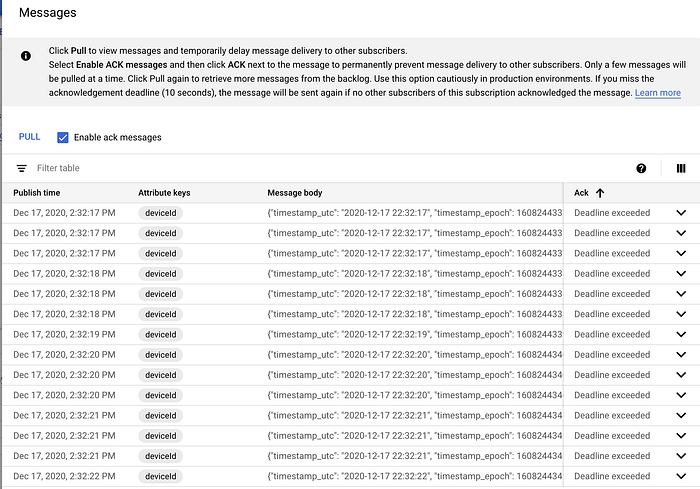
Ejemplo de mensajes llegando a la suscripción de Pub/Sub
Almacenamiento y análisis de datos
Ahora que tenemos una suscripción de Pub/Sub recibiendo mensajes, estamos casi listos para crear un job de Dataflow que los mueva a BigQuery. Antes de configurarlo, hay que crear una tabla en BigQuery donde aterricen los datos provenientes de Dataflow.
Configuración de la tabla en BigQuery
Ve a BigQuery, haz clic en "Create Dataset" y nombra tu dataset 'sensordata', dejando las demás opciones con sus valores predeterminados:
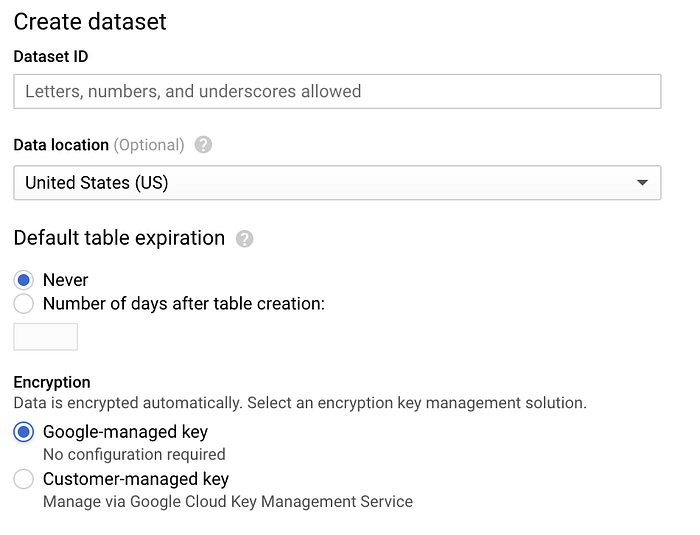
Pantalla de creación del Dataset en BigQuery
Una vez creado el dataset, selecciónalo, haz clic en "Create table" y nombra la nueva tabla "temperature". Asegúrate de incluir el esquema y las opciones de partitioning y clustering que se muestran en las capturas siguientes, ya que soportan patrones comunes de consulta:
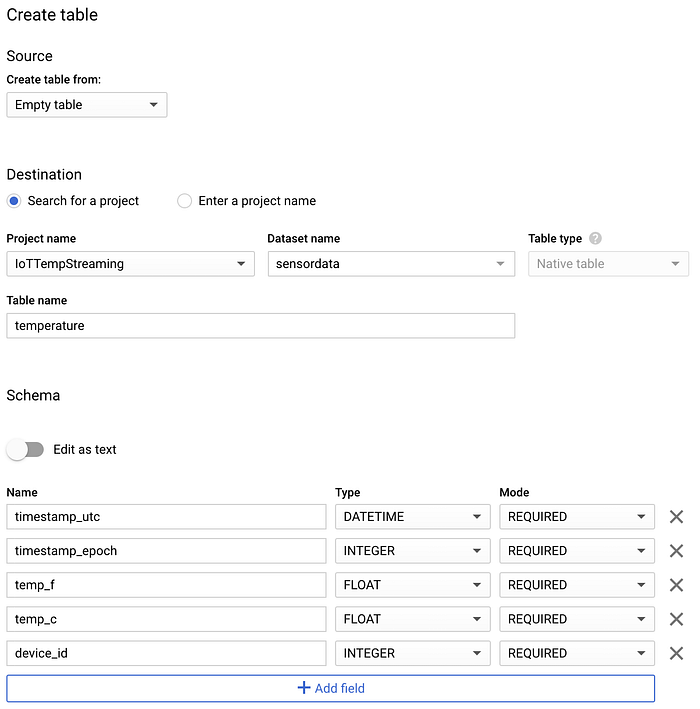
Esquema de la nueva tabla 'temperature' en BigQuery
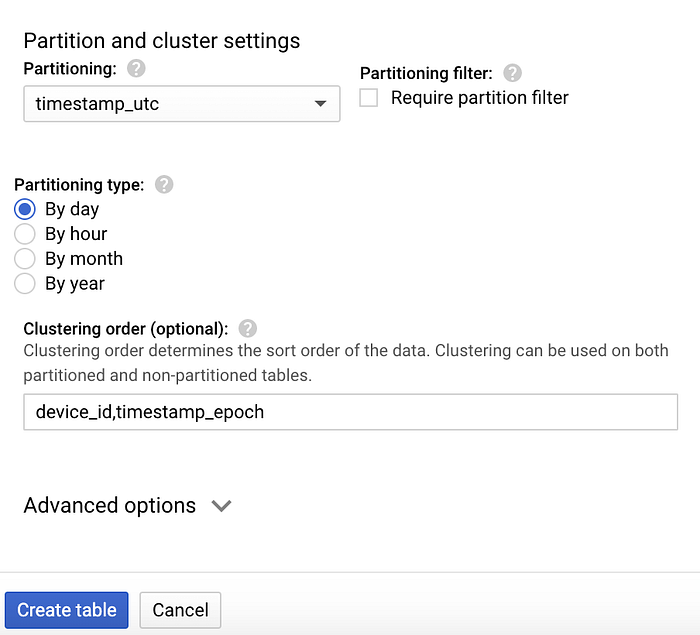
Opciones de partitioning y clustering para la tabla 'temperature'
Si la creaste correctamente, tu nueva tabla vacía se verá así:
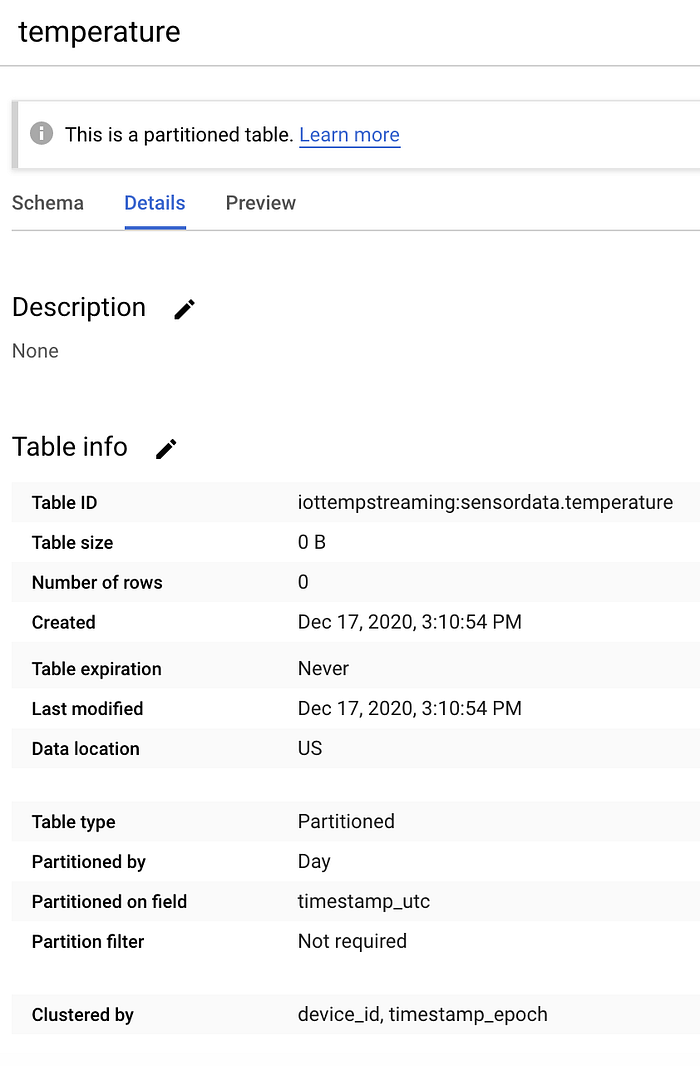
Una tabla 'temperature' vacía en BigQuery dentro del dataset 'sensordata'
Una vez que movamos los datos a la tabla, vamos a mostrar un patrón común de consultas IoT: hacer analítica sobre datos que coincidan con un rango de tiempo específico (por ejemplo, una ventana de una hora del día actual) y para un dispositivo en particular.
El diseño de tabla mostrado arriba es ideal para este tipo de consultas porque:
- El partitioning sobre el campo de timestamp UTC permite que las consultas filtradas por fecha eviten escanear particiones de DateTime correspondientes a días que no coinciden
- Dentro de una partición, el clustering (ordenamiento) por deviceId y timestamp epoch permite recuperar de manera más óptima los datos para un dispositivo y un rango de tiempo específicos dentro de esa partición de fecha.
Para escribir esas consultas, necesitamos datos en la tabla. ¡Pongamos en marcha ese job de Dataflow!
Configuración de Dataflow
Ya tenemos mensajes en una suscripción de Pub/Sub esperando para moverse a otro lado, y una tabla de BigQuery lista para recibirlos. Lo que falta es el pegamento ETL que conecte ambos. Como Pub/Sub y BigQuery son servicios totalmente administrados, con escalado automático y serverless, lo ideal es que la herramienta ETL también tenga esas características.
Dataflow cumple (en gran parte) con esos requisitos. El marketing alrededor de Dataflow afirma que cumple los tres, pero en realidad no es completamente serverless. Sí debes especificar los tipos y tamaños de instancia que se usarán, los recuentos mínimo y máximo de instancias entre los que puede oscilar el escalado automático, y cuánto espacio temporal en disco necesitará cada instancia. Nunca administras esas instancias ni decides cuándo escalan, pero sí debes proporcionar esas especificaciones. Esto contrasta con Pub/Sub y BigQuery, que escalan automáticamente sin ninguna configuración de infraestructura.
A pesar de no ser completamente serverless, Dataflow encaja perfectamente con nuestro requerimiento de ETL de Pub/Sub a BigQuery. Además es fácil de usar, sobre todo porque GCP ofrece muchas plantillas predeterminadas de jobs de Dataflow, incluida una que soporta el flujo de Pub/Sub a BigQuery. Más allá de tener que aumentar el máximo permitido de instancias del escalado automático a medida que tu throughput de datos IoT crezca con el tiempo, en teoría nunca tendrás que preocuparte por administrar la infraestructura que potencia Dataflow.
Con lo básico ya entendido, pasemos a implementar un job de Dataflow. Ve a Dataflow, haz clic en "Create Job from Template" y sigue estos pasos:
- Nombra el job 'pubsub-temp-to-bq'
- Usa la plantilla de streaming predeterminada 'Pub/Sub Subscription to BigQuery'
- Ingresa el nombre completo de la suscripción de Pub/Sub
- Ingresa el ID completo de la tabla de BigQuery
- Indica una ubicación de bucket en Cloud Storage donde puedan almacenarse datos temporales como parte del proceso de Dataflow para la carga por lotes en BigQuery
- Deja las demás opciones con sus valores predeterminados. Normalmente abrirías Advanced Options y especificarías parámetros como el tipo y tamaño de máquina a utilizar, los valores mínimo/máximo de máquinas para el escalado automático y el tamaño de disco por máquina. Sin embargo, para fines de prueba, pueden quedar en sus valores por defecto.
Tu pantalla de creación del job de Dataflow debería verse así:
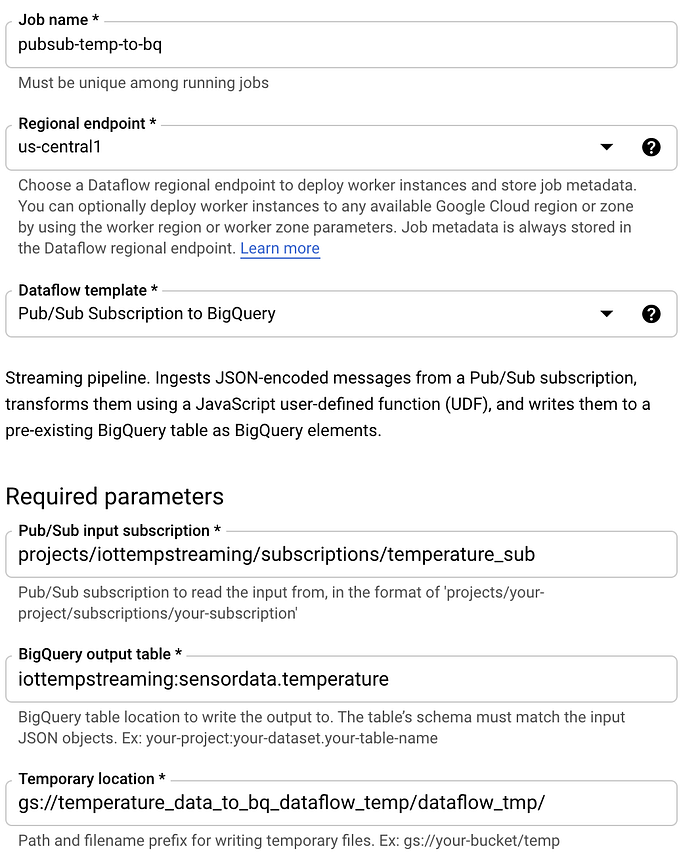
Después de hacer clic en "Create" y esperar unos minutos a que la infraestructura subyacente se levante y empiece a ejecutarse, verás los datos fluyendo desde la suscripción de Pub/Sub hacia la tabla de destino en BigQuery.
El script de Python para streaming de temperatura provisto en la Parte Uno envía datos a un ritmo de un registro por segundo. Por lo tanto, en el grafo acíclico dirigido (DAG) de Dataflow que se muestra abajo, deberías ver x elementos por segundo, donde x es la cantidad de dispositivos con los que estás probando. En mi caso, hay tres dispositivos enviando datos:
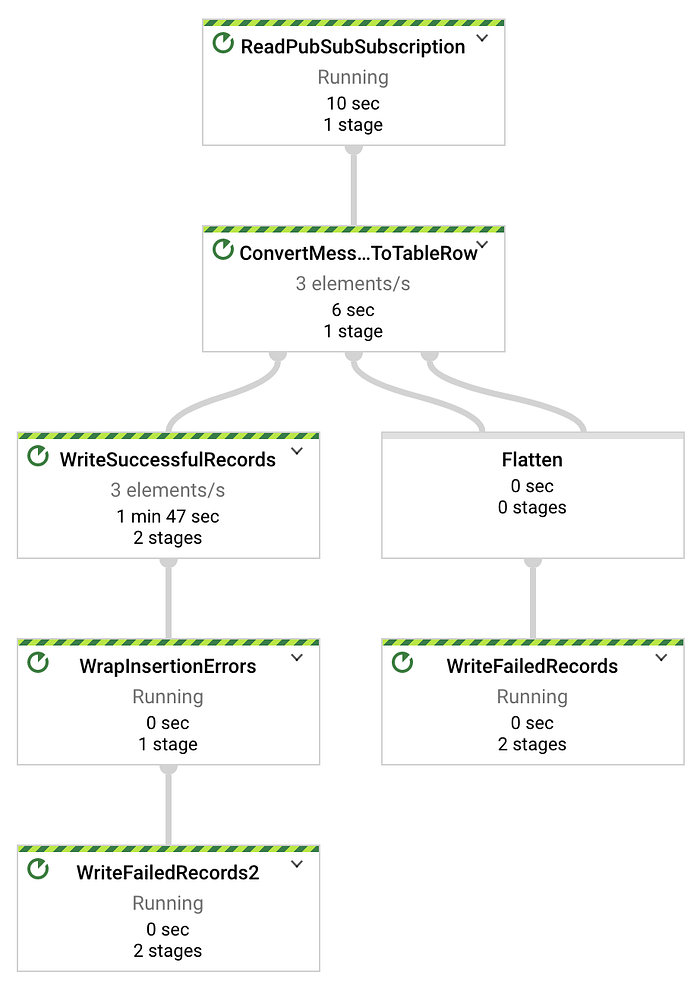
Mensajes transmitidos exitosamente desde Pub/Sub hacia BigQuery mediante un job de Dataflow
Una vez que el job de Dataflow esté activo y enviando con éxito los datos de la suscripción de Pub/Sub a BigQuery, puedes ejecutar una consulta con el siguiente formato en BigQuery y ver los datos llegando a la tabla en tiempo real:
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
LIMIT 10
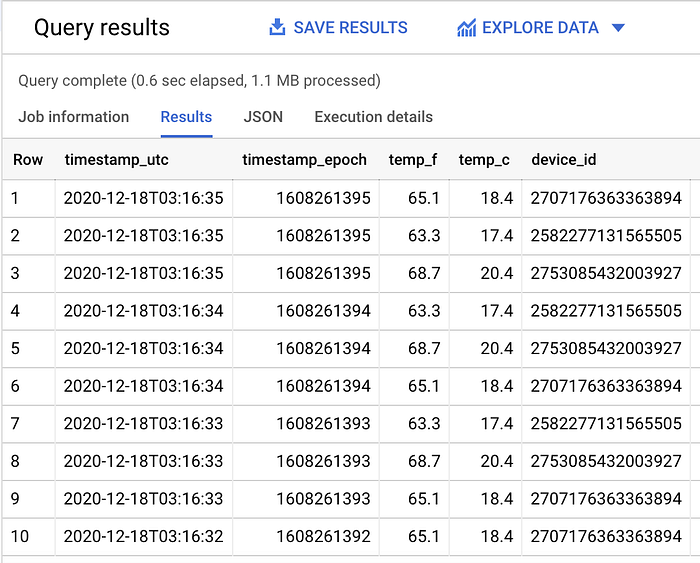
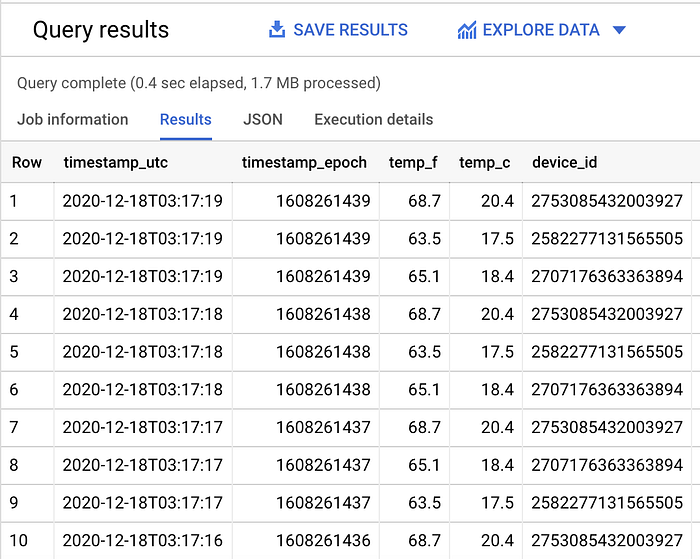
Vemos que el filtrado por partición está funcionando, ya que se escanean más datos en total cuando se quita la cláusula WHERE que filtra por día.
Con mi dataset de ejemplo, se escanean 1,1 MB de datos filtrados (como se ve arriba) y 1,7 MB de datos sin filtrar (como se muestra abajo):
SELECT *
FROM `iottempstreaming.sensordata.temperature`
ORDER BY timestamp_epoch DESC
LIMIT 10
Veamos cuáles son los valores promedio, mínimo y máximo de temperatura de cada sensor en la última hora:
SELECT
device_id,
ROUND(AVG(temp_f), 1) AS temp_f_avg,
MIN(temp_f) AS temp_f_min,
MAX(temp_f) AS temp_f_max
FROM `iottempstreaming.sensordata.temperature`
WHERE timestamp_utc > DATETIME_ADD(CURRENT_DATETIME(), INTERVAL -60 MINUTE)
GROUP BY device_id
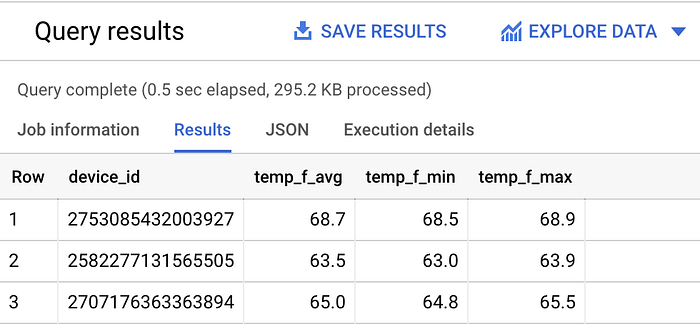
Distintas estadísticas para cada dispositivo de streaming de temperatura
¡Felicitaciones! Acabas de armar un flujo de datos totalmente administrado de extremo a extremo, desde la ingesta hasta el backend de analítica. Antes de cerrar este recorrido, veamos rápidamente lo fácil que resulta visualizar estos datos con Data Studio.
Visualización de los datos almacenados
Empieza ejecutando en BigQuery una consulta similar a la siguiente, que toma todas las filas de un día en particular:
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
A la derecha de "Query Results", haz clic en "Explore Data" y luego en "Explore with Data Studio":
Esto cargará una tabla que resume los datos que acabamos de consultar. Sin embargo, por defecto mostrará una tabla bastante poco interesante con el total de registros recibidos por segundo.
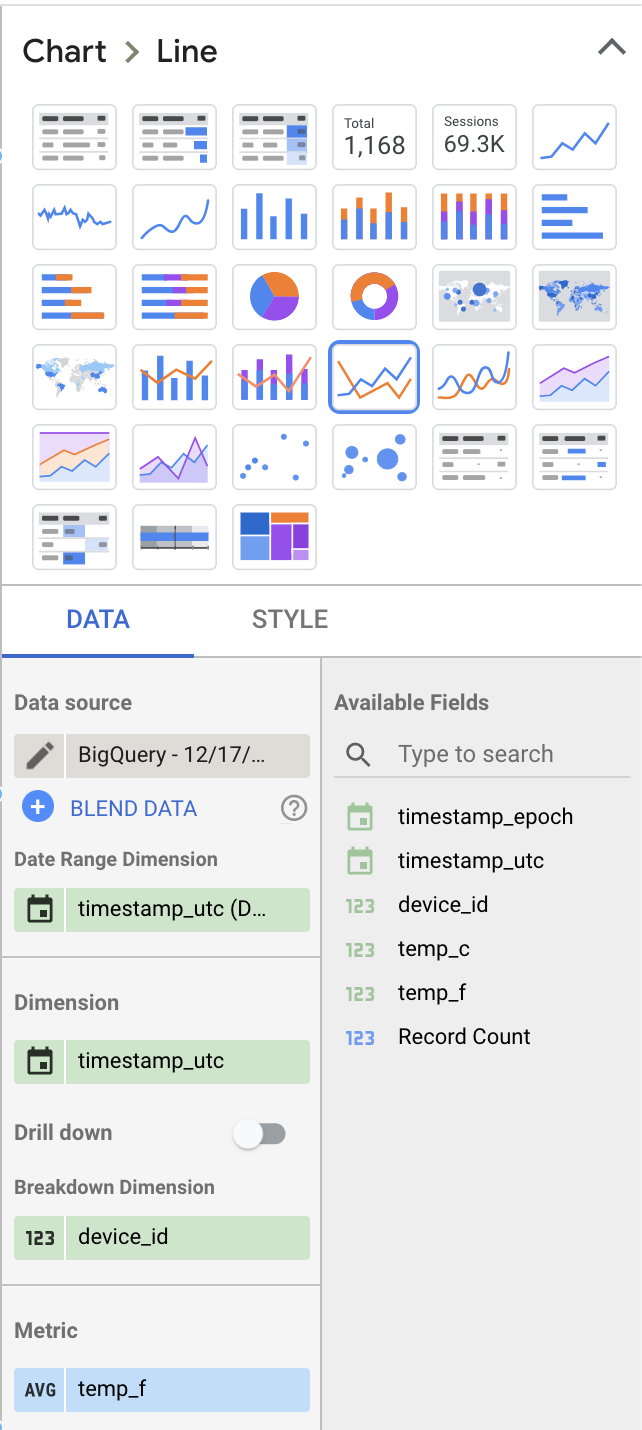
Cambiemos algunos valores en la sección Data del lado derecho para volverla más interesante:
- Selecciona "Line Chart" como tipo de visualización en lugar de "Table"
- Quita "Record Count" como métrica visualizada y reemplázala por "temp_f". Acuérdate de cambiar la métrica predeterminada "SUM" por "AVG".
- Agrega "device_id" como dimensión de desglose
Tus selecciones deberían dar una configuración del dashboard parecida a esta:
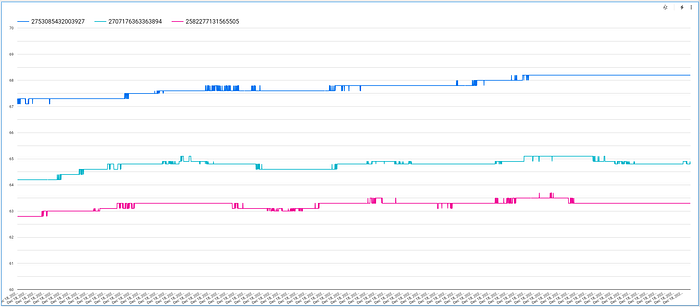
El gráfico resultante mostrará los valores de temperatura de cada dispositivo a lo largo del tiempo, pero puede que no se autoescale bien, ya que el valor mínimo predeterminado del eje Y será cero. Para corregirlo, haz clic en la pestaña "Style", desplázate hasta la opción "Left Y-Axis" y cámbialos a valores razonables:

Quizá también te interese aumentar la cantidad de puntos de datos que pueden mostrarse en el gráfico:
Con estos ajustes, deberías tener un gráfico interactivo y atractivo que te permite recorrer los valores de temperatura de los dispositivos a medida que fluctúan en el tiempo:
Lo que viene: Machine Learning
No te pierdas la tercera parte, donde vamos a construir un modelo funcional de machine learning sobre este dataset de BigQuery y lo usaremos para generar predicciones en tiempo real.