Questo articolo prosegue la Parte Uno, in cui abbiamo visto come effettuare in modo sicuro l'onboarding di una flotta di dispositivi IoT su scala produttiva che inviano dati di telemetria in streaming verso il proprio ambiente Google Cloud tramite IoT Core e Pub/Sub.
Complimenti! Ha registrato con successo diversi dispositivi IoT: e adesso?
L'obiettivo successivo è progettare un sistema in grado di archiviare, analizzare e visualizzare i dati su larga scala, anche tramite dashboard.

Per riuscirci serve progettare per tempo un'architettura del flusso dati che regga operazioni di queste dimensioni. Questo articolo le offre una guida pratica, passo dopo passo.
Panoramica
L'articolo è suddiviso nelle seguenti sezioni:
- Caricamento in batch verso i data sink
- Archiviazione e analisi dei dati
- Visualizzazione dei dati nel data warehouse
A differenza della prima parte, tutto ciò che vedremo qui può essere realizzato interamente dalla console web di GCP. È sufficiente un'esperienza di base con SQL.
Tratteremo i seguenti servizi Google Cloud completamente gestiti e con scalabilità automatica:
- Pub/Sub — una coda di messaggi serverless
- Dataflow — un motore di elaborazione dati in streaming e in batch
- BigQuery — un data warehouse serverless
- Data Studio — un servizio di visualizzazione dei dati e creazione di dashboard
Caricamento in batch verso i data sink
Verificare che i messaggi stiano arrivando
Se ha completato l'onboarding dei dispositivi nel registro IoT e ha avviato lo streaming dei dati verso IoT Core, dovrebbe vedere un flusso costante di messaggi in arrivo dal dashboard principale di GCP IoT:
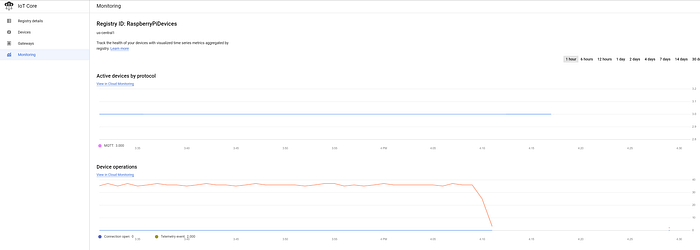
Tre dispositivi connessi correttamente che inviano in streaming i dati di temperatura ogni cinque secondi
Come illustrato nella Parte Uno, questi messaggi arrivano anche nel topic Pub/Sub 'temperature':
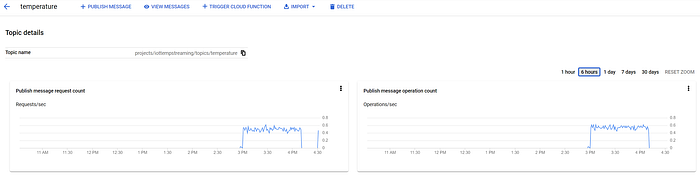
Messaggi Pub/Sub in arrivo nel topic 'temperature'
Streaming verso BigQuery
Bene: i messaggi stanno arrivando in Google Cloud. Il passo successivo è spostare i messaggi Pub/Sub in un data warehouse, dove i dati possano risiedere ai fini di una conservazione a lungo termine economicamente vantaggiosa e di analisi facilmente scalabili. Entra in gioco BigQuery.
BigQuery, il data warehouse di Google Cloud completamente gestito, serverless e con scalabilità automatica, consente di pagare sia compute sia storage con un modello tariffario on-demand: una scelta ideale come data sink per archiviare e analizzare i nostri dati IoT.
Ma come si effettua lo streaming dei messaggi Pub/Sub in BigQuery? Con Dataflow.
Dataflow, la versione completamente gestita e con scalabilità automatica di Apache Beam offerta da Google Cloud, è pensata per trasferire dati da un servizio all'altro. Permette, in via opzionale, di filtrare e trasformare i dati e di ottimizzare il caricamento in batch verso servizi che hanno limiti sulle operazioni di caricamento, come database e soluzioni di data warehousing.
Dataflow include diversi template predefiniti creati da Google Cloud, tra cui un template Pub/Sub-to-BigQuery: non serve quindi scrivere alcuna riga di codice per collegare i servizi di ingestione e quelli di archiviazione e analisi dei dati.
Dato che Pub/Sub, Dataflow e BigQuery sono tutti servizi completamente gestiti e con scalabilità automatica — oltre che serverless, con l'eccezione di Dataflow — è possibile costruire un sistema end-to-end di gestione dei dati IoT che scala senza difficoltà dai test in fase di sviluppo fino a operazioni dell'ordine dei petabyte, praticamente senza alcuna gestione dell'infrastruttura man mano che la scala cresce.
Vediamo all'opera tutti questi servizi collegati tra loro.
Configurazione della Pub/Sub Subscription
Prima di iniziare a spostare i dati da Pub/Sub a Dataflow, conviene creare una Pub/Sub subscription collegata al topic Pub/Sub.
Perché? I messaggi che raggiungono un topic Pub/Sub vengono inviati immediatamente ai sottoscrittori del topic (con strategia Push) e quindi eliminati dal topic. I sottoscrittori, invece, possono trattenere i messaggi finché un processo non li richiede (con strategia Pull). È possibile collegare Dataflow direttamente a un topic anziché a una subscription, ma se un job Dataflow di questo tipo subisse un'interruzione, i messaggi che arrivano al topic durante il downtime andrebbero persi.
Collegando invece Dataflow a una Pub/Sub subscription a sua volta collegata al topic, si evita la perdita di messaggi durante eventuali interruzioni. Se un job Dataflow venisse temporaneamente interrotto, tutti i messaggi IoT non ancora elaborati resterebbero nella Pub/Sub subscription, in attesa che il job riprenda a recuperarli.
Una Pub/Sub subscription collegata a un topic Pub/Sub crea un'architettura dati resiliente alle interruzioni dei servizi di ingestione a valle.
Per creare una subscription in Pub/Sub:
- Vada su Subscriptions
- Clicchi su "Create Subscription" e assegni alla subscription il nome "temperature_sub"
- La sottoscriva al topic Pub/Sub "temperature"
- Lasci le altre opzioni con i valori predefiniti
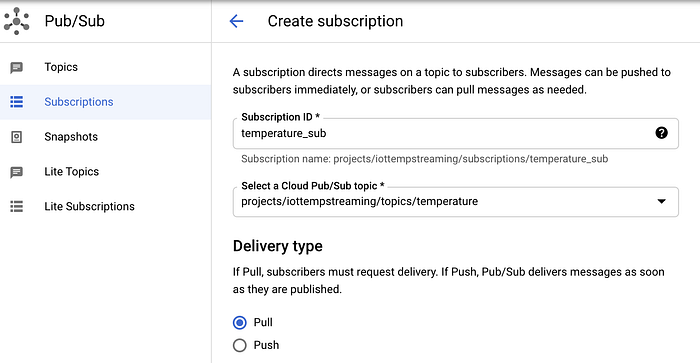
Creazione della Pub/Sub subscription 'temperature_sub' collegata al topic Pub/Sub 'temperature'
Una volta creata, cliccando sulla subscription e poi su "Pull" dovrebbe vedere i messaggi iniziare a fluire:
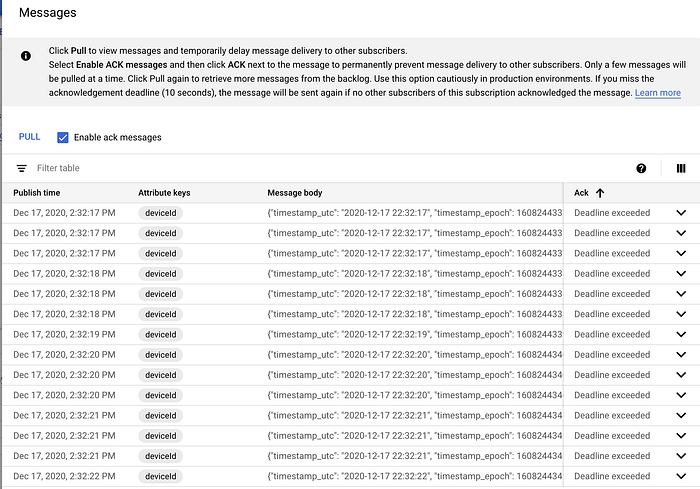
Esempio di messaggi in streaming verso la Pub/Sub subscription
Archiviazione e analisi dei dati
Ora che abbiamo una Pub/Sub subscription che riceve i messaggi, siamo quasi pronti a creare un job Dataflow per spostarli in BigQuery. Prima, però, dobbiamo creare in BigQuery la tabella di destinazione dei dati provenienti da Dataflow.
Configurazione della tabella BigQuery
Vada in BigQuery, clicchi su "Create Dataset" e assegni al dataset il nome 'sensordata', lasciando le altre opzioni con i valori predefiniti:
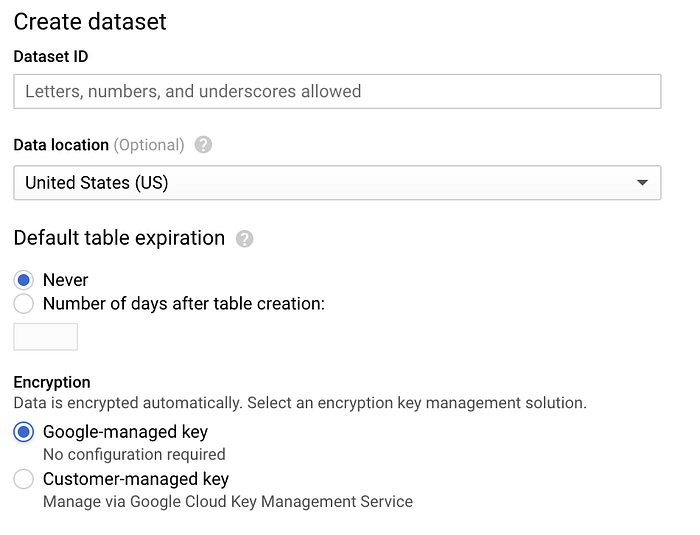
Schermata di creazione del dataset BigQuery
Una volta creato il dataset, lo selezioni, clicchi su "Create table" e assegni alla nuova tabella il nome "temperature". Si assicuri di includere lo schema e le opzioni di partitioning e clustering mostrate negli screenshot qui sotto: sono pensate proprio per supportare i pattern di query più comuni.
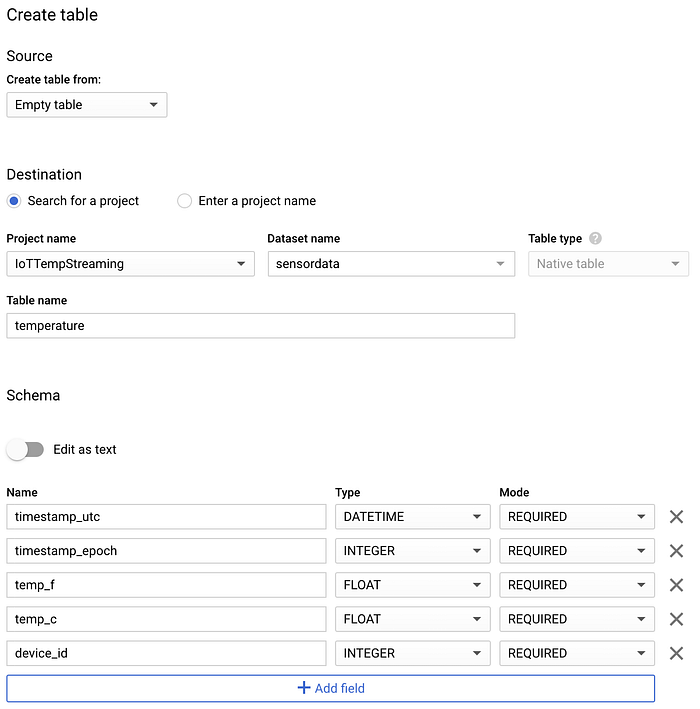
Schema della nuova tabella BigQuery 'temperature'
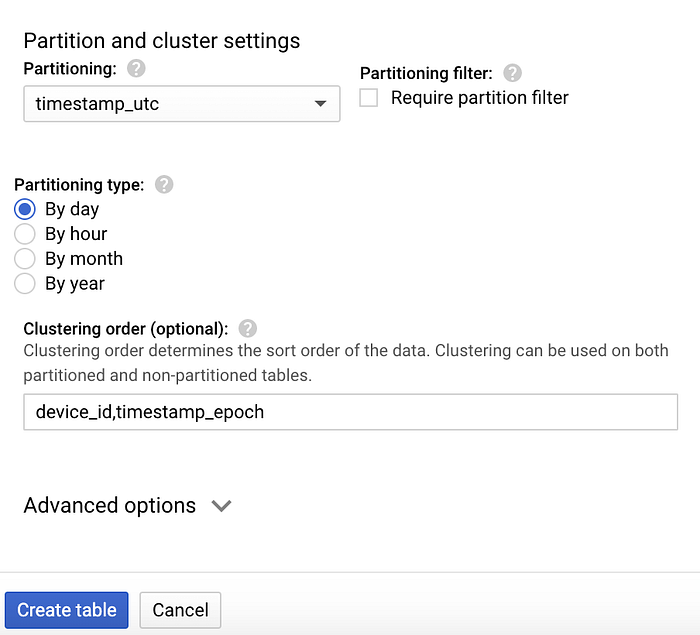
Opzioni di partitioning e clustering per la tabella 'temperature'
Se la creazione è andata a buon fine, la nuova tabella vuota apparirà come segue:
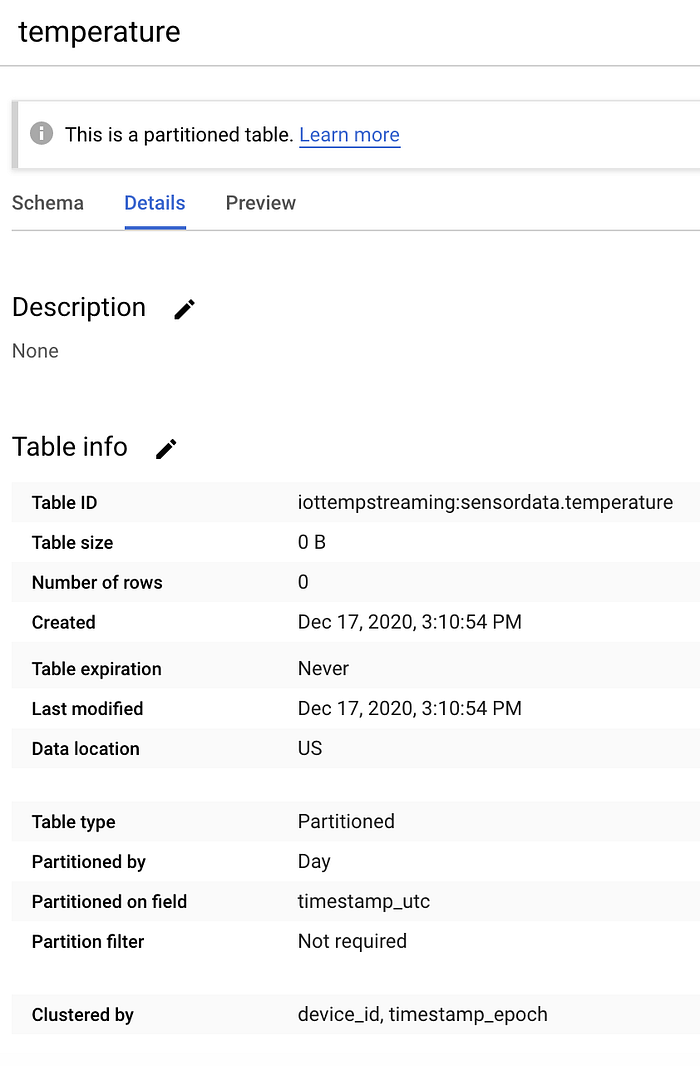
Una tabella BigQuery 'temperature' vuota all'interno del dataset 'sensordata'
Una volta caricati i dati nella tabella, mostreremo un pattern di query IoT molto comune: eseguire analisi sui dati relativi a un intervallo temporale specifico (ad esempio una finestra di un'ora del giorno corrente) e a uno specifico dispositivo.
Il design della tabella mostrato sopra è ideale per questo tipo di query perché:
- il partitioning sul campo timestamp UTC consente alle query con filtro per data di evitare la scansione delle partizioni DateTime relative ai giorni non corrispondenti;
- all'interno di una partizione, il clustering (ordinamento) su deviceId e timestamp epoch permette un recupero più efficiente dei dati per uno specifico dispositivo e intervallo temporale all'interno di quella particolare partizione di data.
Per scrivere queste query servono dati nella tabella. Avviamo dunque il job Dataflow.
Configurazione di Dataflow
Al momento abbiamo messaggi accumulati in una Pub/Sub subscription, in attesa di essere spostati altrove, e una tabella BigQuery pronta a riceverli. Quello che serve adesso è il "collante" ETL che metta in comunicazione i due. Poiché sia Pub/Sub sia BigQuery sono servizi completamente gestiti, con scalabilità automatica e serverless, idealmente vogliamo uno strumento ETL con le stesse caratteristiche.
Dataflow risponde (quasi) a tutti questi requisiti. Il marketing di Dataflow lo presenta in questo modo, ma in realtà non è completamente serverless. È necessario specificare tipi e dimensioni delle istanze utilizzate, il numero minimo e massimo di istanze tra cui può oscillare lo scaling automatico e lo spazio disco temporaneo richiesto da ciascuna istanza. Non si gestiscono mai direttamente queste istanze né la logica con cui decidono di scalare, ma occorre comunque fornire queste specifiche. Una differenza rispetto a Pub/Sub e BigQuery, che scalano automaticamente senza alcuna configurazione dell'infrastruttura.
Pur non essendo completamente serverless, Dataflow è la soluzione perfetta per il nostro requisito ETL Pub/Sub-to-BigQuery. È anche semplice da usare, soprattutto considerando che GCP offre numerosi template predefiniti per i job Dataflow, incluso uno per il workflow Pub/Sub-to-BigQuery. A parte la necessità di alzare il numero massimo di istanze consentite dallo scaling automatico man mano che il throughput dei dati IoT cresce nel tempo, in teoria non dovrà mai preoccuparsi di gestire l'infrastruttura che alimenta Dataflow.
Chiariti i fondamentali, implementiamo un job Dataflow. Vada in Dataflow, clicchi su "Create Job from Template" e segua questi passaggi:
- Assegni al job il nome 'pubsub-temp-to-bq'
- Utilizzi il template di streaming predefinito 'Pub/Sub Subscription to BigQuery'
- Inserisca il nome completo della Pub/Sub subscription
- Inserisca l'ID completo della tabella BigQuery
- Indichi un percorso bucket di Cloud Storage in cui Dataflow possa conservare i dati temporanei nell'ambito del processo di caricamento batch in BigQuery
- Lasci le altre opzioni con i valori predefiniti. In genere si espandono le Advanced Options per indicare parametri come il tipo e la dimensione della macchina, i valori min/max dello scaling automatico e la dimensione del disco per ciascuna macchina. Per i test, però, si possono lasciare i valori predefiniti.
La schermata di creazione del job Dataflow dovrebbe apparire così:
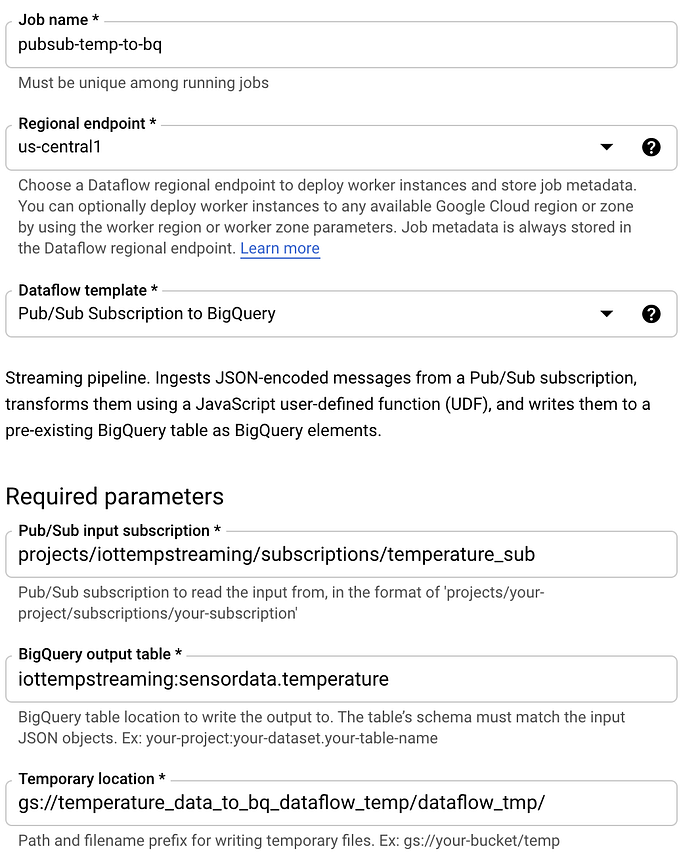
Dopo aver cliccato su "Create" e atteso qualche minuto perché l'infrastruttura sottostante venga avviata, vedrà i dati fluire dalla Pub/Sub subscription alla tabella BigQuery di destinazione.
Lo script Python di streaming della temperatura fornito nella Parte Uno trasmette al ritmo di un record al secondo. Quindi, nel Directed Acyclic Graph (DAG) di Dataflow mostrato sotto, dovrebbe vedere x elementi in streaming al secondo, dove x è il numero di dispositivi con cui sta facendo i test. Nel mio caso sono tre i dispositivi in streaming:
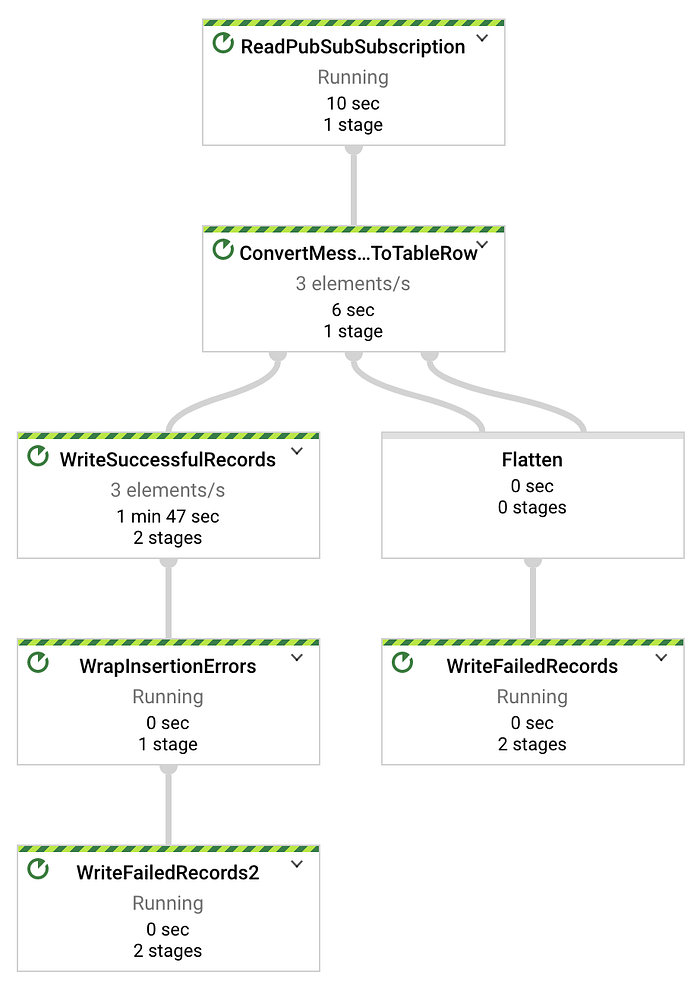
Messaggi inviati con successo da Pub/Sub a BigQuery tramite un job Dataflow
Quando il job Dataflow risulta attivo e sta inviando correttamente i dati della Pub/Sub subscription a BigQuery, può eseguire una query del seguente tipo in BigQuery e vedere i dati arrivare nella tabella in tempo reale:
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
LIMIT 10
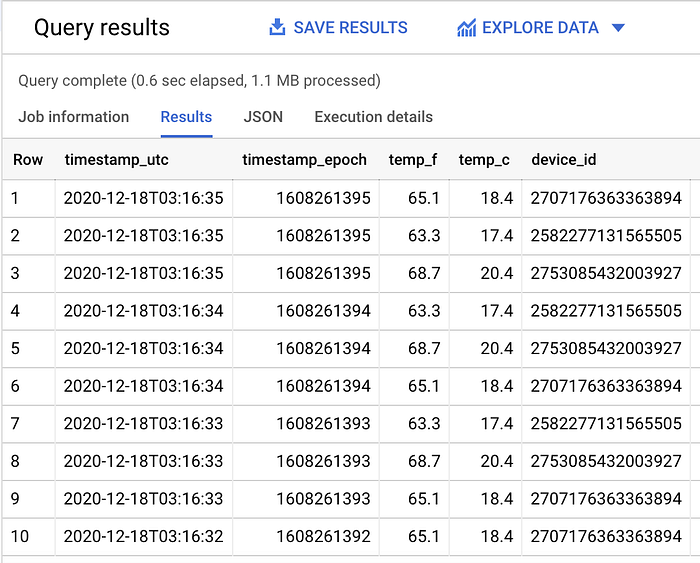
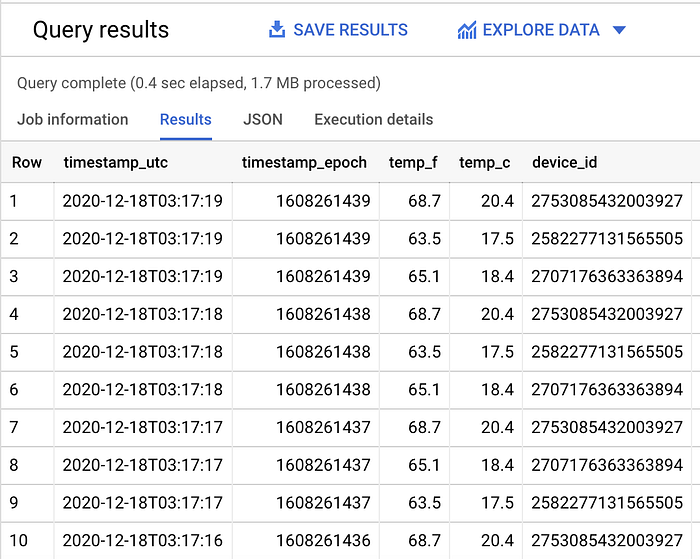
Si vede che il filtraggio per partizione sta funzionando: rimuovendo la clausola WHERE che filtra per giorno, viene scansionata una quantità totale di dati maggiore.
Nel mio dataset di esempio vengono scansionati 1,1 MB di dati filtrati (come si vede sopra) e 1,7 MB di dati non filtrati (mostrato sotto):
SELECT *
FROM `iottempstreaming.sensordata.temperature`
ORDER BY timestamp_epoch DESC
LIMIT 10
Vediamo ora i valori medio, minimo e massimo della temperatura per ciascun sensore nell'ultima ora:
SELECT
device_id,
ROUND(AVG(temp_f), 1) AS temp_f_avg,
MIN(temp_f) AS temp_f_min,
MAX(temp_f) AS temp_f_max
FROM `iottempstreaming.sensordata.temperature`
WHERE timestamp_utc > DATETIME_ADD(CURRENT_DATETIME(), INTERVAL -60 MINUTE)
GROUP BY device_id
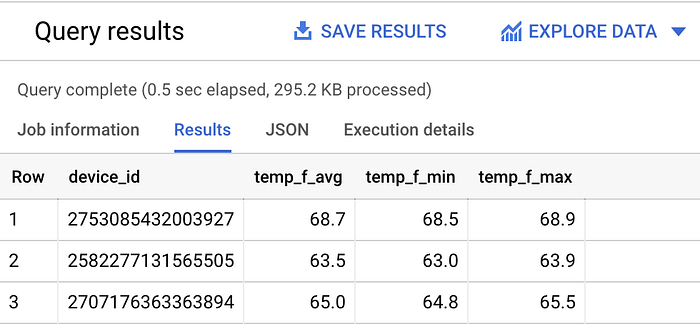
Diverse statistiche per ciascun dispositivo che invia in streaming la temperatura
Complimenti! Ha appena configurato un workflow di dati completamente gestito end-to-end, dall'ingestione fino al backend analitico. Prima di concludere questa guida, vediamo rapidamente quanto sia semplice visualizzare questi dati con Data Studio.
Visualizzazione dei dati nel data warehouse
Inizi eseguendo in BigQuery una query simile alla seguente, che recupera tutte le righe di dati di un determinato giorno:
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
A destra di "Query Results", clicchi su "Explore Data" e poi su "Explore with Data Studio":
Verrà caricata una tabella che riepiloga i dati appena interrogati. Per impostazione predefinita, però, mostrerà una tabella poco interessante con il numero totale di record trasmessi al secondo.
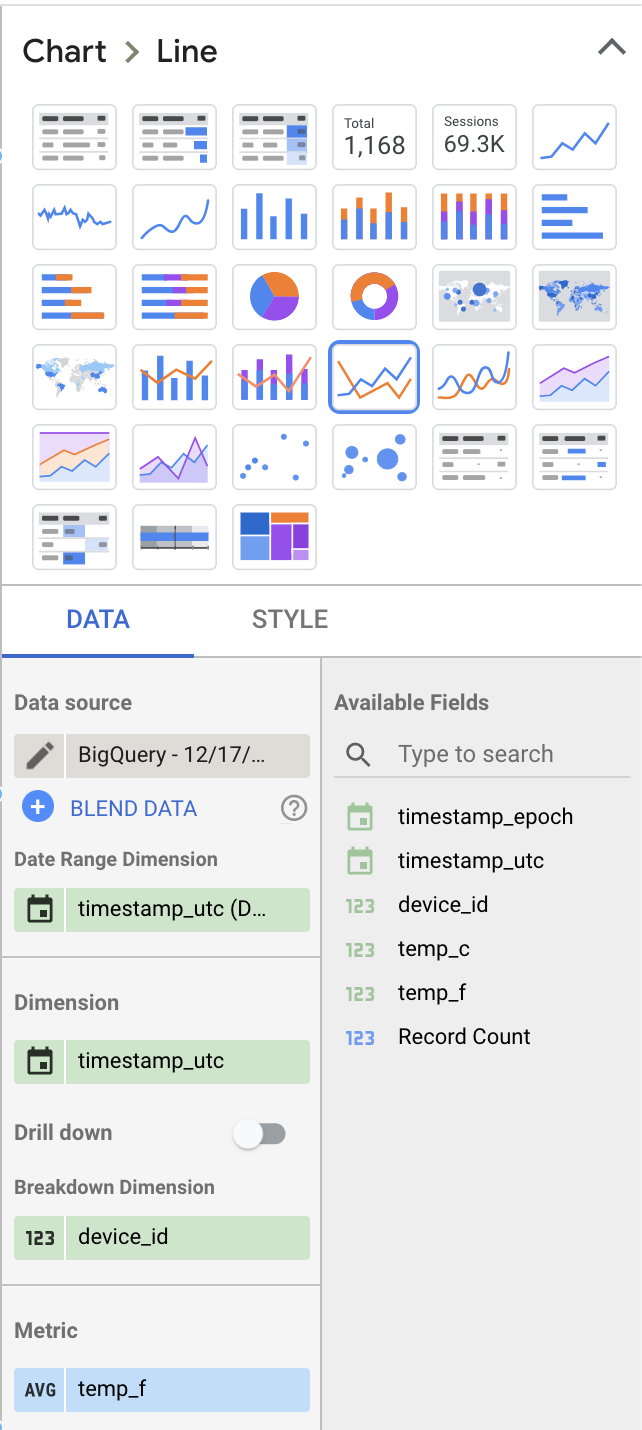
Modifichiamo qualche valore nella sezione Data sulla destra per renderla più interessante:
- Selezioni "Line Chart" come tipo di visualizzazione anziché "Table"
- Rimuova "Record Count" come metrica visualizzata e la sostituisca con "temp_f". Ricordi di cambiare la metrica predefinita "SUM" in "AVG".
- Aggiunga "device_id" come dimensione di breakout
Le sue scelte dovrebbero produrre impostazioni di layout del dashboard simili a queste:
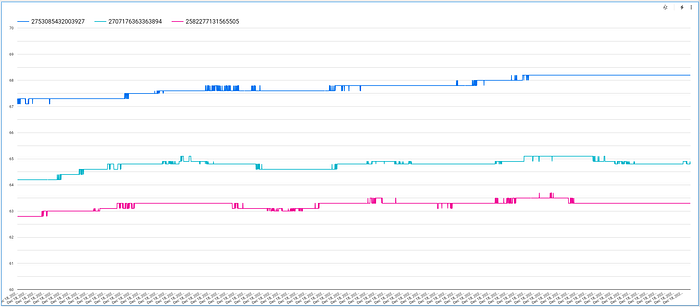
Il grafico così generato mostrerà i valori di temperatura di ciascun dispositivo nel tempo, ma potrebbe non essere ben proporzionato, perché di default il valore minimo dell'asse Y è zero. Per correggere l'aspetto, clicchi sulla scheda "Style", scorra fino all'opzione "Left Y-Axis" e imposti valori più ragionevoli:

Potrebbe inoltre voler aumentare il numero di punti dati visualizzabili sul grafico:
Con queste modifiche otterrà un grafico interattivo e curato nella resa, che le permetterà di scorrere i valori di temperatura di ciascun dispositivo nel loro andamento nel tempo:
Prossimo appuntamento: Machine Learning
Non perda la terza parte, in cui costruiremo un modello di machine learning funzionante su questo dataset BigQuery e lo useremo per generare previsioni in tempo reale.