Dieser Beitrag knüpft an Teil eins an, in dem wir gezeigt haben, wie Sie eine Flotte von IoT-Geräten im Produktionsmaßstab sicher anbinden und Telemetriedaten über IoT Core und Pub/Sub in Ihre Google-Cloud-Umgebung streamen.
Glückwunsch! Sie haben mehrere IoT-Geräte erfolgreich registriert – und wie geht es jetzt weiter?
Im nächsten Schritt gilt es, ein System zu entwerfen, das Speicherung, Analyse und Visualisierung bzw. Dashboarding Ihrer Daten in großem Maßstab ermöglicht.

Dafür müssen Sie frühzeitig eine Datenflussarchitektur planen, die solch umfangreiche Datenoperationen trägt. Dieser Artikel führt Sie praxisnah durch genau diesen Prozess.
Überblick
Der Artikel ist in folgende Abschnitte gegliedert:
- Batch-Loading in Daten-Sinks
- Speicherung und Analyse der Daten
- Visualisierung der gespeicherten Daten
Anders als in Teil eins lässt sich alles, was hier beschrieben wird, vollständig über die Web-Konsole der GCP umsetzen. Grundlegende SQL-Kenntnisse genügen.
Folgende vollständig verwalteten und automatisch skalierenden Google-Cloud-Dienste kommen zum Einsatz:
- Pub/Sub – eine serverlose Message Queue
- Dataflow – eine Engine für Stream- und Batch-Datenverarbeitung
- BigQuery – ein serverloses Data Warehouse
- Data Studio – ein Dienst zur Datenvisualisierung und Dashboard-Erstellung
Batch-Loading in Daten-Sinks
Prüfen, ob Nachrichten ankommen
Wenn Sie Geräte erfolgreich in der IoT-Registry registriert haben und Daten an den IoT Core streamen, sollten Sie im zentralen GCP-IoT-Dashboard einen kontinuierlichen Strom eingehender Nachrichten sehen:
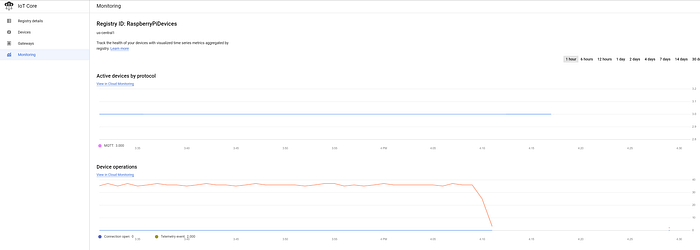
Drei erfolgreich verbundene Geräte streamen alle fünf Sekunden Temperaturdaten
Wie in Teil eins gezeigt, treffen diese Nachrichten auch in Ihrem Pub/Sub-Topic "temperature" ein:
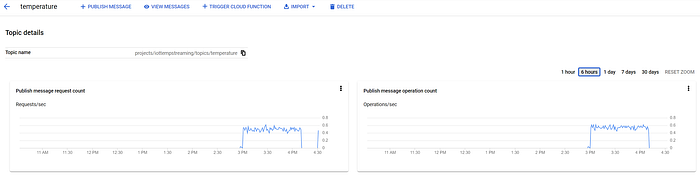
Pub/Sub-Nachrichten gehen im Topic "temperature" ein
Streaming nach BigQuery
Sehr gut – die Nachrichten erreichen Google Cloud. Als Nächstes überführen wir die Pub/Sub-Nachrichten in ein Data Warehouse, in dem die Daten kosteneffizient langfristig gespeichert und flexibel ausgewertet werden können. Auftritt: BigQuery.
BigQuery, das vollständig verwaltete, serverlose und automatisch skalierende Data Warehouse von Google Cloud, rechnet Compute und Storage nach einem On-Demand-Modell ab und ist damit ein idealer Daten-Sink, um unsere IoT-Daten zu speichern und zu analysieren.
Aber wie streamen wir Pub/Sub-Nachrichten nach BigQuery? Mit Dataflow.
Dataflow, die vollständig verwaltete und automatisch skalierende Variante von Apache Beam in Google Cloud, ist darauf ausgelegt, Daten von einem Dienst in einen anderen zu übertragen. Optional können Sie Daten filtern und transformieren sowie Batch-Loads optimal in Dienste mit begrenzter Ladekapazität wie Datenbanken oder Data-Warehouse-Lösungen einspielen.
Dataflow bringt zahlreiche von Google Cloud bereitgestellte Standard-Templates mit, darunter eines von Pub/Sub nach BigQuery – Datenaufnahme und Speicher- bzw. Analysedienste lassen sich damit ganz ohne Coding verbinden.
Da Pub/Sub, Dataflow und BigQuery sämtlich vollständig verwaltete und automatisch skalierende Dienste sind – und mit Ausnahme von Dataflow zudem serverlos – lässt sich ein durchgängiges IoT-Datenmanagement-System aufbauen, das mühelos vom Entwicklungstest bis in den Petabyte-Bereich skaliert. Während des Skalierens fällt dabei praktisch kein Infrastrukturaufwand an.
Sehen wir uns das Zusammenspiel dieser Dienste in der Praxis an!
Pub/Sub-Subscription einrichten
Bevor wir Daten von Pub/Sub nach Dataflow verschieben, sollten wir eine Pub/Sub-Subscription anlegen, die das entsprechende Topic abonniert.
Warum? Nachrichten, die ein Pub/Sub-Topic erreichen, werden sofort an die Topic-Abonnenten ausgeliefert (per Push-Strategie) und anschließend aus dem Topic entfernt. Subscriptions hingegen halten Nachrichten vor, bis ein Prozess sie abruft (per Pull-Strategie). Sie könnten Dataflow zwar direkt mit einem Topic verbinden – fällt der Dataflow-Job dann aber aus, gehen alle Nachrichten verloren, die in dieser Zeit im Topic eingehen.
Verbinden Sie Dataflow stattdessen mit einer Subscription, die das Topic abonniert, vermeiden Sie Nachrichtenverluste bei Ausfällen. Wird ein Dataflow-Job vorübergehend unterbrochen, bleiben alle noch nicht verarbeiteten IoT-Nachrichten in der Pub/Sub-Subscription liegen und warten, bis Dataflow sie wieder abholt.
Eine Pub/Sub-Subscription auf ein Pub/Sub-Topic schafft eine Datenarchitektur, die auch gegenüber Ausfällen nachgelagerter Aufnahmedienste robust bleibt.
So legen Sie eine Subscription in Pub/Sub an:
- Wechseln Sie zu "Subscriptions".
- Klicken Sie auf "Create Subscription" und benennen Sie die Subscription mit "temperature_sub".
- Verknüpfen Sie sie mit dem Pub/Sub-Topic "temperature".
- Belassen Sie die übrigen Optionen auf den Standardwerten.
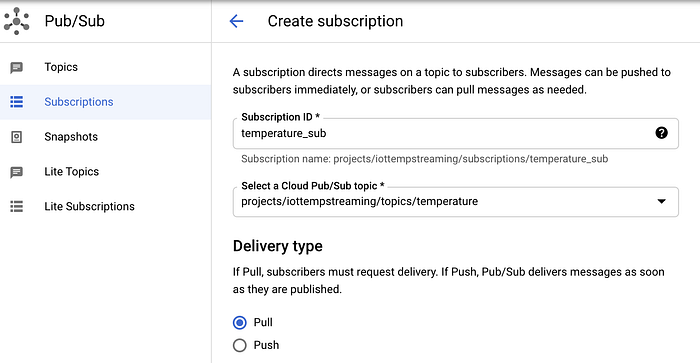
Anlegen der Pub/Sub-Subscription "temperature_sub" zum Pub/Sub-Topic "temperature"
Sobald die Subscription angelegt ist, klicken Sie sie an und wählen Sie "Pull". Anschließend sollten die ersten Nachrichten eintreffen:
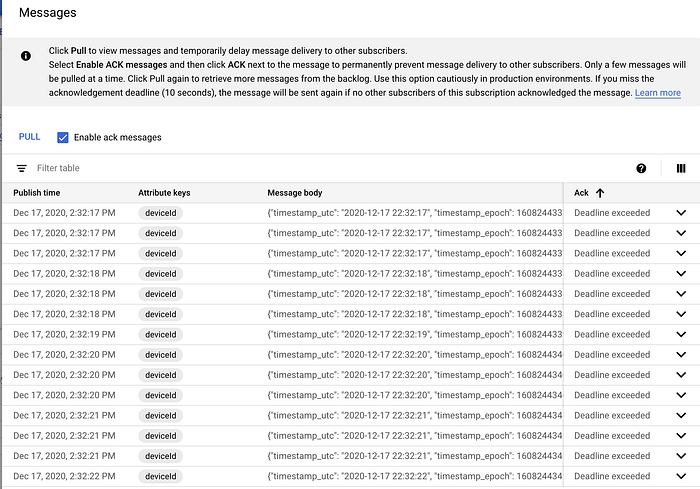
Beispielnachrichten, die in der Pub/Sub-Subscription eingehen
Speicherung und Analyse der Daten
Mit einer empfangsbereiten Pub/Sub-Subscription sind wir fast so weit, einen Dataflow-Job einzurichten, der die Nachrichten nach BigQuery überträgt. Vorher legen wir in BigQuery noch die Tabelle an, in der die Daten aus Dataflow landen sollen.
BigQuery-Tabelle einrichten
Wechseln Sie zu BigQuery, klicken Sie auf "Create Dataset" und benennen Sie das Dataset mit "sensordata". Die übrigen Optionen behalten ihre Standardwerte:
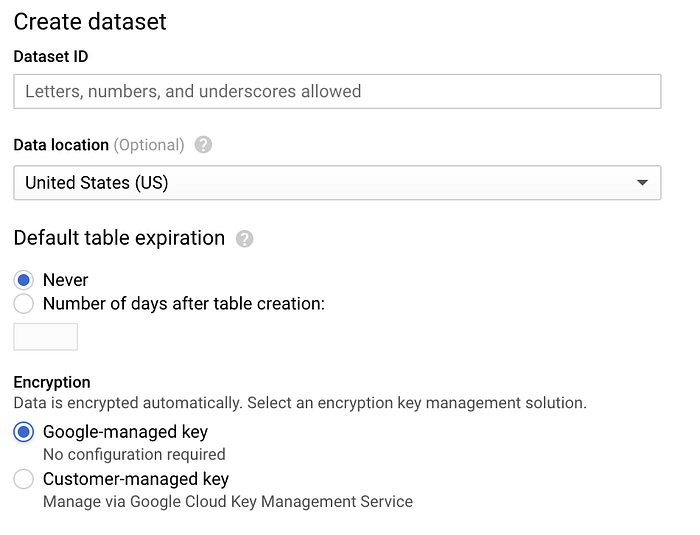
Dialog zur Anlage eines BigQuery-Datasets
Wählen Sie das angelegte Dataset aus, klicken Sie auf "Create table" und nennen Sie die neue Tabelle "temperature". Übernehmen Sie unbedingt die in den Screenshots unten gezeigten Schema-, Partitionierungs- und Clustering-Optionen – sie unterstützen typische Abfragemuster:
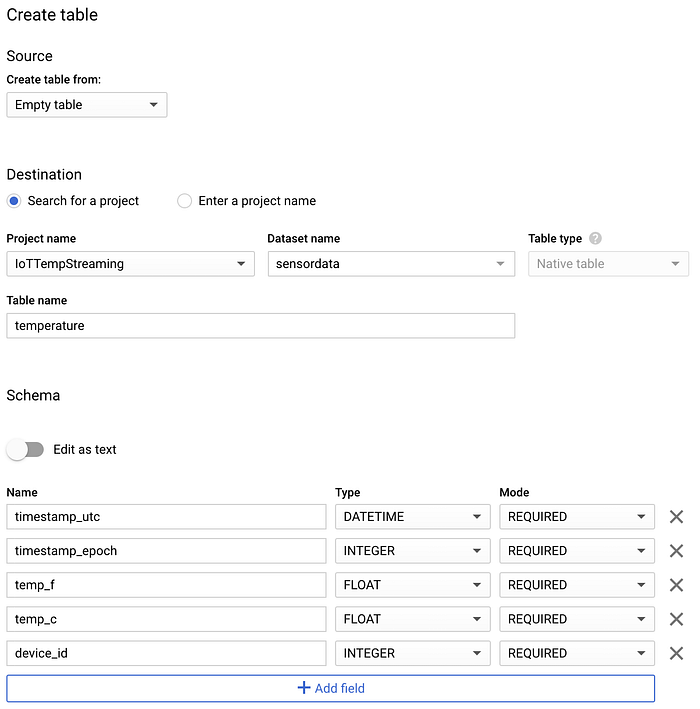
Schema der neuen BigQuery-Tabelle "temperature"
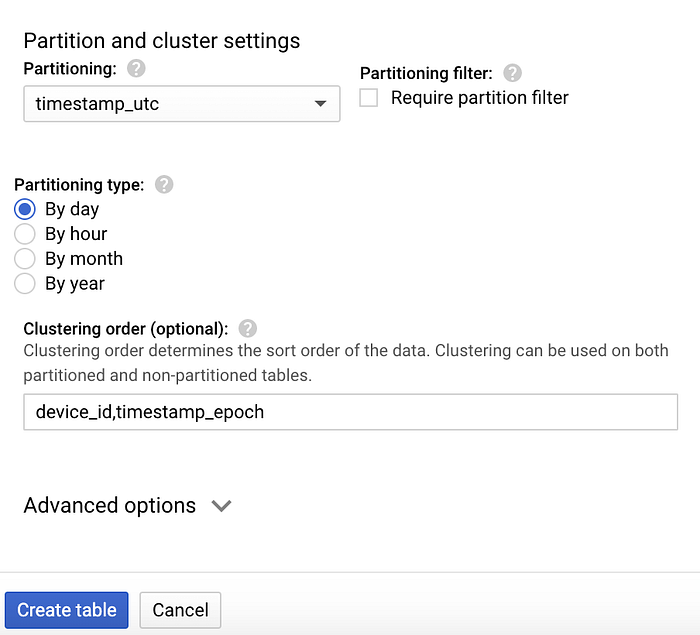
Partitionierungs- und Clustering-Optionen für die Tabelle "temperature"
Wenn alles korrekt angelegt wurde, sieht Ihre neue, leere Tabelle so aus:
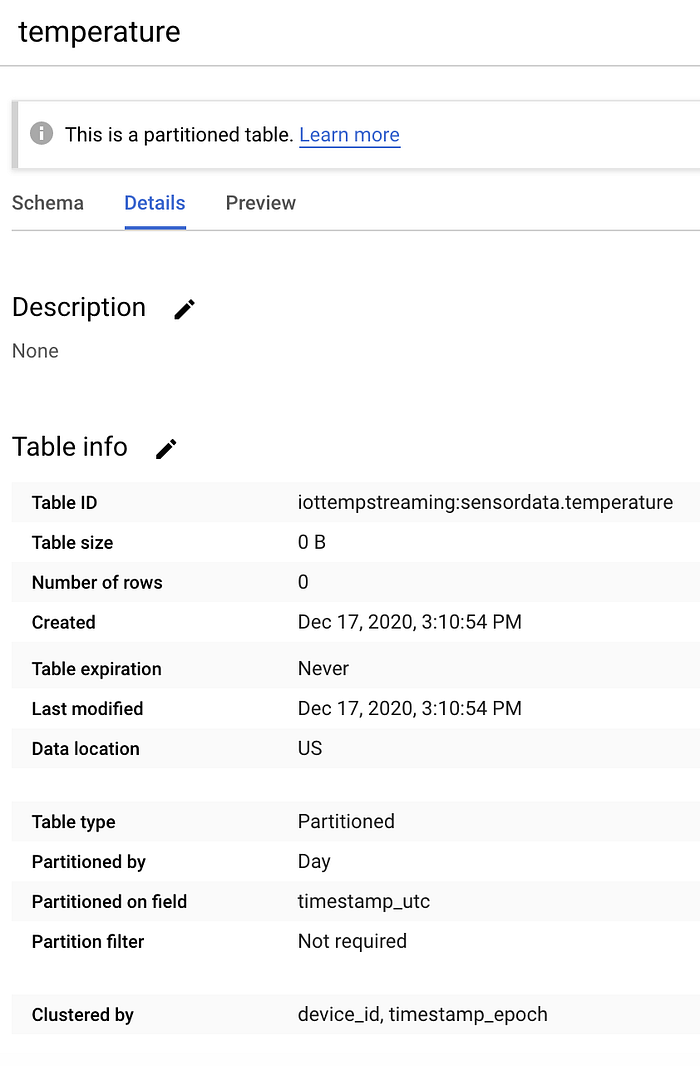
Eine leere BigQuery-Tabelle "temperature" im Dataset "sensordata"
Sobald Daten in der Tabelle liegen, demonstrieren wir ein typisches IoT-Abfragemuster: Auswertungen für ein bestimmtes Zeitfenster (etwa eine Stunde am aktuellen Tag) und ein bestimmtes Gerät.
Das oben gezeigte Tabellendesign ist aus folgenden Gründen ideal für solche Abfragen:
- Durch die Partitionierung über das UTC-Timestamp-Feld umgehen datumsspezifische Abfragen das Scannen von DateTime-Partitionen nicht passender Tage.
- Innerhalb einer Partition ermöglicht das Clustering (Sortierung) nach deviceId und Epoch-Timestamp einen besonders effizienten Datenabruf für ein bestimmtes Gerät und Zeitfenster innerhalb der jeweiligen Tagespartition.
Damit wir solche Abfragen schreiben können, brauchen wir Daten in der Tabelle. Bringen wir den Dataflow-Job ans Laufen!
Dataflow einrichten
Aktuell warten Nachrichten in einer Pub/Sub-Subscription darauf, weiterverarbeitet zu werden, und eine BigQuery-Tabelle steht bereit, sie aufzunehmen. Was uns noch fehlt, ist das ETL-Bindeglied zwischen beiden. Da Pub/Sub und BigQuery vollständig verwaltet, automatisch skalierend und serverlos sind, brauchen wir idealerweise auch ein ETL-Werkzeug mit denselben Eigenschaften.
Dataflow erfüllt diese Anforderungen weitgehend. Im Marketing wird der Dienst zwar als Komplettpaket beworben, in Wahrheit ist er aber nicht vollständig serverlos. Sie müssen Instanztyp und -größe festlegen, ebenso die Min-/Max-Grenzen, zwischen denen das Auto-Scaling die Instanzanzahl variieren darf, sowie den temporären Plattenspeicher pro Instanz. Sie verwalten diese Instanzen und ihr Skalierungsverhalten zwar nicht selbst, müssen die Vorgaben aber dennoch machen. Pub/Sub und BigQuery skalieren dagegen ganz ohne Infrastrukturkonfiguration.
Auch wenn Dataflow nicht vollständig serverlos ist, passt der Dienst perfekt zu unserer ETL-Anforderung von Pub/Sub nach BigQuery. Hinzu kommt, dass GCP zahlreiche vorgefertigte Dataflow-Job-Templates bietet – darunter eines für den Workflow von Pub/Sub nach BigQuery. Abgesehen davon, dass Sie das Auto-Scaling-Maximum mit zunehmendem IoT-Datendurchsatz gelegentlich anheben müssen, brauchen Sie sich theoretisch nie um die Infrastruktur hinter Dataflow zu kümmern.
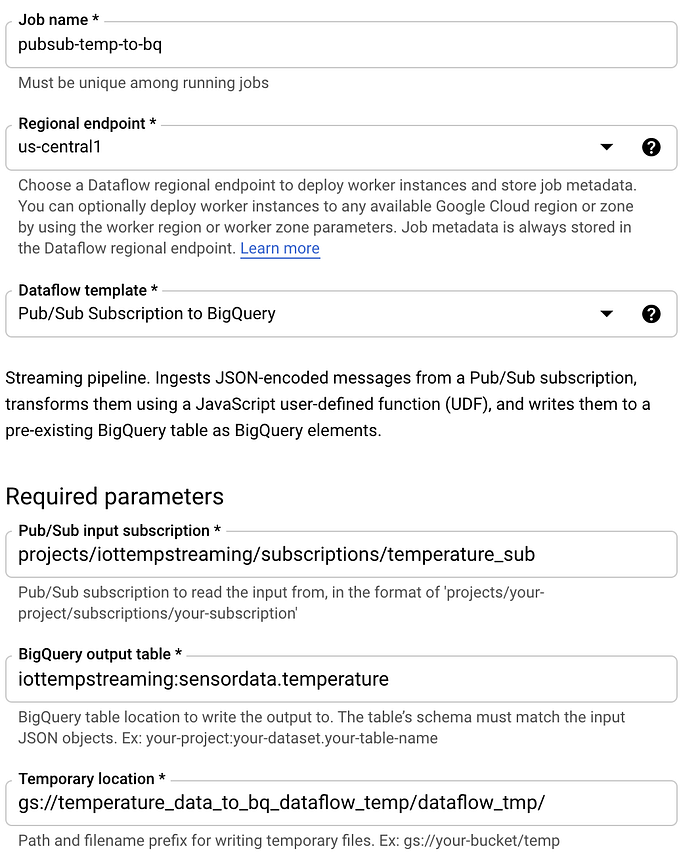
Mit den Grundlagen im Gepäck legen wir nun einen Dataflow-Job an. Wechseln Sie zu Dataflow, klicken Sie auf "Create Job from Template" und gehen Sie wie folgt vor:
- Benennen Sie den Job mit "pubsub-temp-to-bq".
- Verwenden Sie das Standard-Streaming-Template "Pub/Sub Subscription to BigQuery".
- Tragen Sie den vollständigen Namen der Pub/Sub-Subscription ein.
- Tragen Sie die vollständige BigQuery-Tabellen-ID ein.
- Geben Sie einen Cloud-Storage-Bucket an, in dem während des Batch-Loadings nach BigQuery temporäre Daten abgelegt werden können.
- Belassen Sie die übrigen Optionen auf ihren Standardwerten. Üblicherweise würden Sie unter "Advanced Options" Parameter wie Maschinentyp und -größe, die Min-/Max-Werte des Auto-Scalings sowie die Festplattengröße pro Maschine festlegen. Für Testzwecke reichen jedoch die Standardwerte.
Ihr Dialog zur Erstellung des Dataflow-Jobs sollte dann so aussehen:
Nach einem Klick auf "Create" und ein paar Minuten Wartezeit, bis die zugrunde liegende Infrastruktur hochgefahren ist, sehen Sie, wie Daten aus der Pub/Sub-Subscription in die Ziel-Tabelle in BigQuery fließen.
Das in Teil eins bereitgestellte Python-Skript zum Streamen von Temperaturdaten erzeugt einen Datensatz pro Sekunde. Im unten gezeigten Directed Acyclic Graph (DAG) von Dataflow sehen Sie also x Elemente pro Sekunde, wobei x der Anzahl der getesteten Geräte entspricht. In meinem Fall streamen drei Geräte:
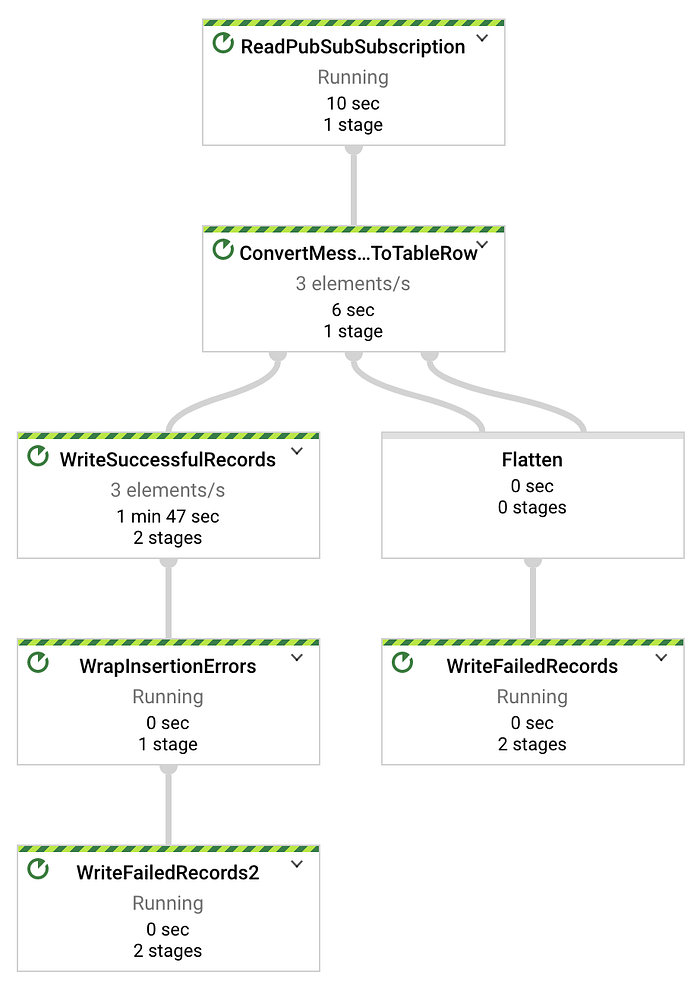
Nachrichten, die per Dataflow-Job erfolgreich von Pub/Sub nach BigQuery gestreamt werden
Sobald der Dataflow-Job läuft und Daten aus der Pub/Sub-Subscription nach BigQuery überträgt, können Sie in BigQuery eine Abfrage in folgender Form ausführen und Echtzeitdaten in der Tabelle einsehen:
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
LIMIT 10
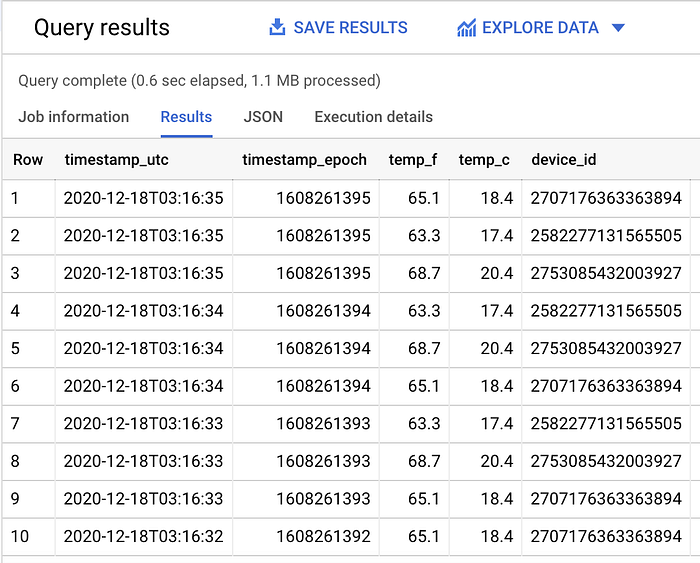
Dass die Partitionsfilterung greift, erkennen Sie daran, dass ohne die Tages-WHERE-Klausel insgesamt mehr Daten gescannt werden.
In meinem Beispiel-Dataset werden 1,1 MB gefilterte Daten gescannt (siehe oben) und 1,7 MB ungefilterte Daten (siehe unten):
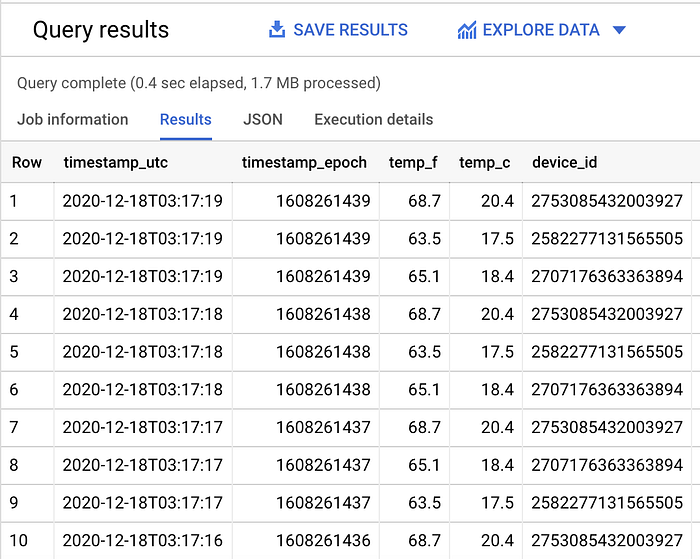
SELECT *
FROM `iottempstreaming.sensordata.temperature`
ORDER BY timestamp_epoch DESC
LIMIT 10
Sehen wir uns die Durchschnitts-, Mindest- und Höchsttemperaturen je Sensor in der letzten Stunde an:
SELECT
device_id,
ROUND(AVG(temp_f), 1) AS temp_f_avg,
MIN(temp_f) AS temp_f_min,
MAX(temp_f) AS temp_f_max
FROM `iottempstreaming.sensordata.temperature`
WHERE timestamp_utc > DATETIME_ADD(CURRENT_DATETIME(), INTERVAL -60 MINUTE)
GROUP BY device_id
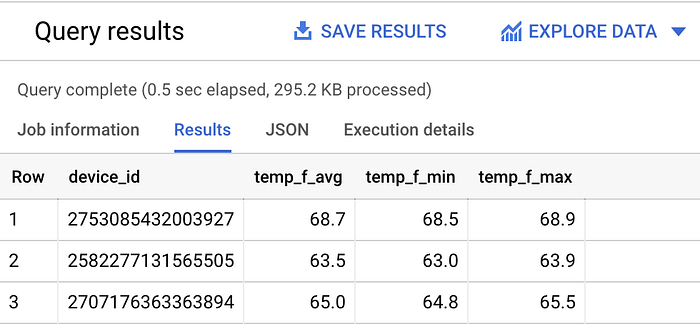
Verschiedene Kennzahlen je Temperatur-Streaming-Gerät
Glückwunsch! Sie haben gerade einen durchgängig vollständig verwalteten Daten-Workflow eingerichtet – von der Datenaufnahme bis zum Analyse-Backend. Bevor wir abschließen, werfen wir noch einen kurzen Blick darauf, wie einfach sich diese Daten mit Data Studio visualisieren lassen.
Visualisierung der gespeicherten Daten
Führen Sie zunächst in BigQuery eine Abfrage wie die folgende aus, die alle Datensätze eines bestimmten Tages liefert:
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
Klicken Sie rechts neben "Query Results" auf "Explore Data" und anschließend auf "Explore with Data Studio":
Daraufhin wird eine Tabelle geladen, die die soeben abgefragten Daten zusammenfasst. In der Standardansicht zeigt sie allerdings recht wenig Spannendes – nämlich die Gesamtzahl der pro Sekunde gestreamten Datensätze.
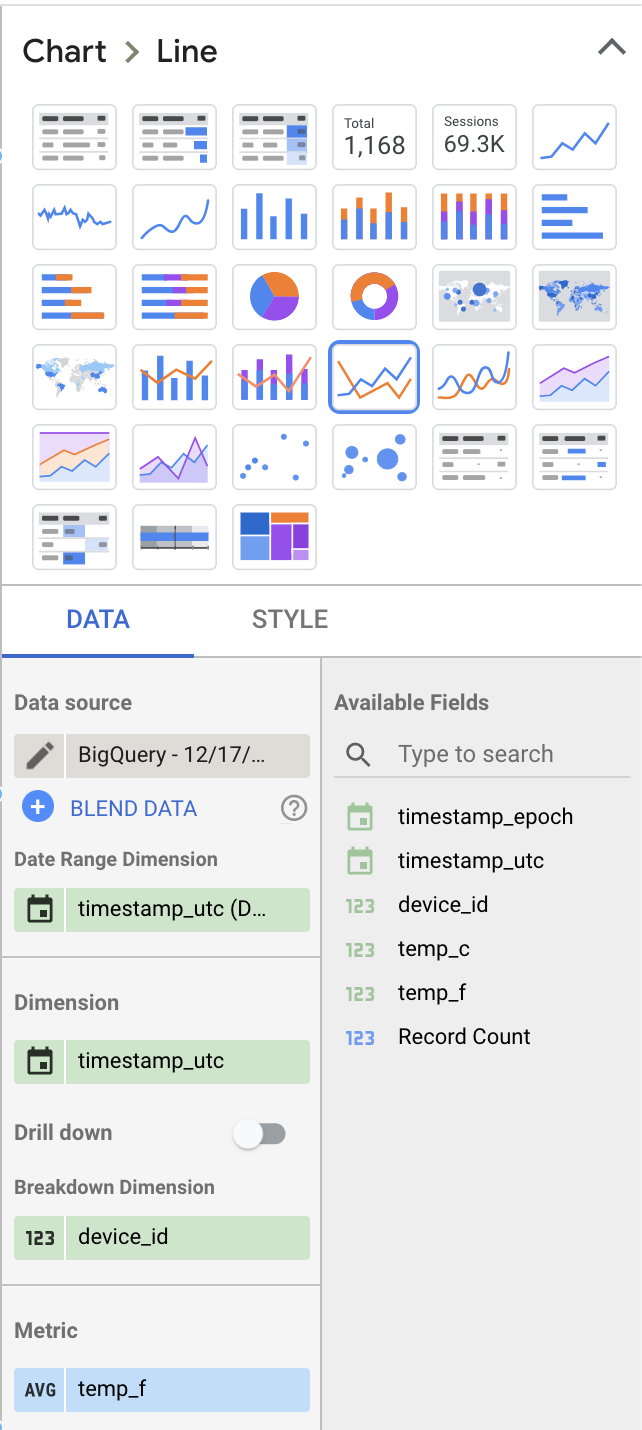
Passen wir auf der rechten Seite im Bereich "Data" einige Werte an, damit es interessanter wird:
- Wählen Sie als Visualisierungstyp "Line Chart" statt "Table".
- Entfernen Sie "Record Count" als angezeigte Metrik und ersetzen Sie sie durch "temp_f". Stellen Sie die Standardmetrik dabei von "SUM" auf "AVG" um.
- Fügen Sie "device_id" als Aufschlüsselungs-Dimension hinzu.
Ihre Einstellungen sollten in etwa so aussehen:
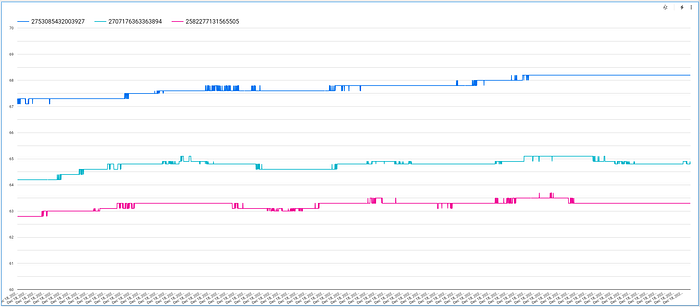
Das Diagramm zeigt nun die Temperaturwerte je Gerät im Zeitverlauf, ist aber möglicherweise schlecht skaliert, da der Mindestwert der y-Achse standardmäßig bei null liegt. Wechseln Sie auf den Tab "Style", scrollen Sie zur Option "Left Y-Axis" und passen Sie die Werte sinnvoll an:

Sie können zudem die Anzahl der im Diagramm darstellbaren Datenpunkte erhöhen:
Mit diesen Anpassungen erhalten Sie ein ansprechendes, interaktives Diagramm, in dem Sie die Temperaturwerte der Geräte im Zeitverlauf bequem durchscrollen können:
Als Nächstes: Machine Learning
Bleiben Sie dran für Teil drei: Dort bauen wir auf diesem BigQuery-Dataset ein funktionierendes Machine-Learning-Modell auf und nutzen es, um Vorhersagen in Echtzeit zu erzeugen.