Este post dá continuidade à Parte Um, em que mostramos como conectar com segurança uma frota de dispositivos IoT em escala de produção que transmite dados de telemetria para o seu ambiente Google Cloud via IoT Core e Pub/Sub.
Parabéns! Você registrou vários dispositivos IoT — e agora?
O próximo passo é desenhar um sistema que ofereça armazenamento, análise e visualização/dashboarding em larga escala dos seus dados.

Para isso, é preciso planejar com antecedência uma arquitetura de fluxo de dados que dê conta de operações dessa magnitude. Este artigo traz um passo a passo prático para fazer exatamente isso.
Visão geral
Este conteúdo está dividido nas seguintes seções:
- Carga em lote para os data sinks
- Armazenamento e análise de dados
- Visualização dos dados armazenados
Diferentemente da Parte Um, tudo o que veremos aqui pode ser feito inteiramente pelo console web do GCP. Basta uma noção básica de SQL.
Vamos abordar os seguintes serviços do Google Cloud, totalmente gerenciados e com auto-scaling:
- Pub/Sub — uma fila de mensagens serverless
- Dataflow — um motor de processamento de dados em stream e em lote
- BigQuery — um data warehouse serverless
- Data Studio — um serviço de visualização de dados e criação de dashboards
Carga em lote para os data sinks
Confirme se as mensagens estão chegando
Se você cadastrou os dispositivos no registro do IoT e começou a transmitir dados ao IoT Core, deve ver um fluxo constante de mensagens chegando no dashboard principal de IoT do GCP:
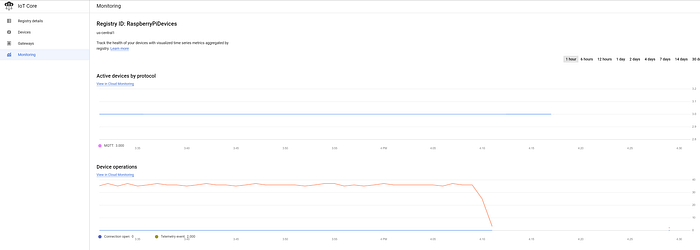
Três dispositivos conectados com sucesso, transmitindo dados de temperatura a cada cinco segundos
Como mostrado na Parte Um, essas mensagens também chegam ao seu tópico Pub/Sub ‘temperature’:
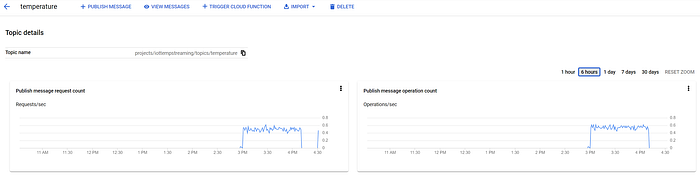
Mensagens Pub/Sub chegando ao tópico ‘temperature’
Streaming para o BigQuery
Ótimo — as mensagens estão chegando ao Google Cloud. Agora precisamos levar essas mensagens do Pub/Sub para um data warehouse, onde os dados podem ficar armazenados com bom custo-benefício no longo prazo e ainda permitir análises facilmente escaláveis. É aí que entra o BigQuery.
O BigQuery, data warehouse totalmente gerenciado, serverless e com auto-scaling do Google Cloud, permite pagar tanto por compute quanto por armazenamento sob demanda, o que faz dele um ótimo data sink para guardar e analisar nossos dados de IoT.
Mas como transmitir mensagens do Pub/Sub para o BigQuery? Com o Dataflow.
O Dataflow, versão totalmente gerenciada e com auto-scaling do Apache Beam no Google Cloud, foi feito para mover dados de um serviço para outro. Ele permite filtrar e transformar os dados de forma opcional, além de fazer cargas em lote otimizadas para serviços com limite de operações de carga, como bancos de dados e soluções de data warehousing.
O Dataflow já vem com vários templates padrão criados pelo próprio Google Cloud, inclusive um Pub/Sub-para-BigQuery, então não é preciso escrever uma linha de código para conectar a ingestão aos serviços de armazenamento e análise.
Como Pub/Sub, Dataflow e BigQuery são totalmente gerenciados e com auto-scaling — e (com exceção do Dataflow) também serverless —, dá para construir um sistema de gerenciamento de dados IoT ponta a ponta que escala com facilidade do teste em desenvolvimento até operações na escala de petabytes — praticamente sem precisar gerenciar infraestrutura conforme o crescimento.
Vamos ver todos esses serviços conectados em ação!
Configuração da assinatura Pub/Sub
Antes de mover dados do Pub/Sub para o Dataflow, devemos criar uma assinatura Pub/Sub vinculada ao tópico Pub/Sub.
Por quê? Mensagens que chegam a um tópico Pub/Sub são enviadas imediatamente aos assinantes (via estratégia Push) e, na sequência, removidas do tópico. Já os assinantes conseguem reter as mensagens até que algum processo as solicite (via estratégia Pull). É possível conectar o Dataflow direto a um tópico em vez de a uma assinatura, mas, se esse job de Dataflow ficar fora do ar, as mensagens que chegarem ao tópico durante a indisponibilidade serão perdidas.
Conectando o Dataflow a uma assinatura Pub/Sub que está inscrita no tópico, você evita perder mensagens em períodos de indisponibilidade. Se um job de Dataflow for interrompido temporariamente, todas as mensagens IoT ainda não processadas continuam na assinatura Pub/Sub, esperando o job voltar a consumi-las.
Uma assinatura Pub/Sub vinculada a um tópico Pub/Sub cria uma arquitetura de dados resiliente a interrupções nos serviços de ingestão downstream.
Para criar uma assinatura no Pub/Sub:
- Acesse Subscriptions,
- Clique em "Create Subscription" e dê o nome "temperature_sub" à assinatura
- Inscreva-a no tópico Pub/Sub "temperature"
- Mantenha as demais opções nos valores padrão
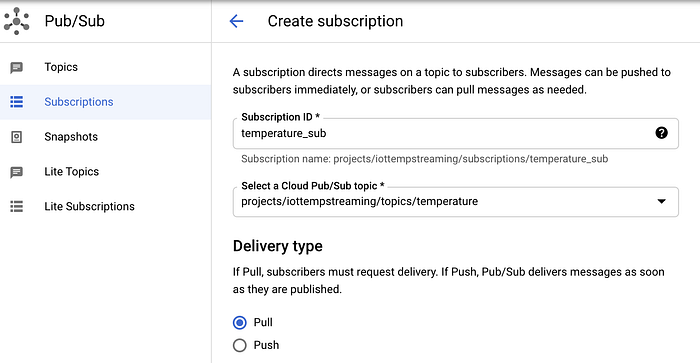
Criação da assinatura Pub/Sub ‘temperature_sub’ para o tópico Pub/Sub ‘temperature’
Depois de criada, ao clicar na assinatura e em "Pull" você verá as mensagens começarem a aparecer:
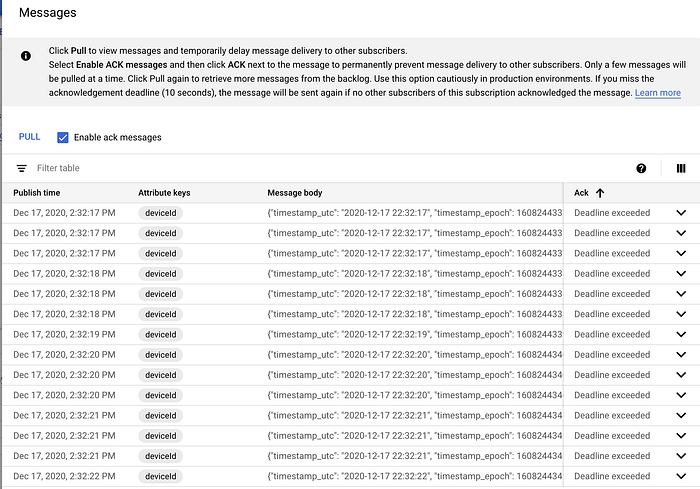
Exemplos de mensagens chegando à assinatura Pub/Sub
Armazenamento e análise de dados
Agora que temos uma assinatura Pub/Sub recebendo mensagens, estamos quase prontos para criar um job do Dataflow que leve essas mensagens para o BigQuery. Antes disso, precisamos criar uma tabela no BigQuery que vai receber os dados vindos do Dataflow.
Configuração da tabela no BigQuery
Acesse o BigQuery, clique em "Create Dataset" e dê o nome ‘sensordata’ ao dataset, mantendo as demais opções nos padrões:
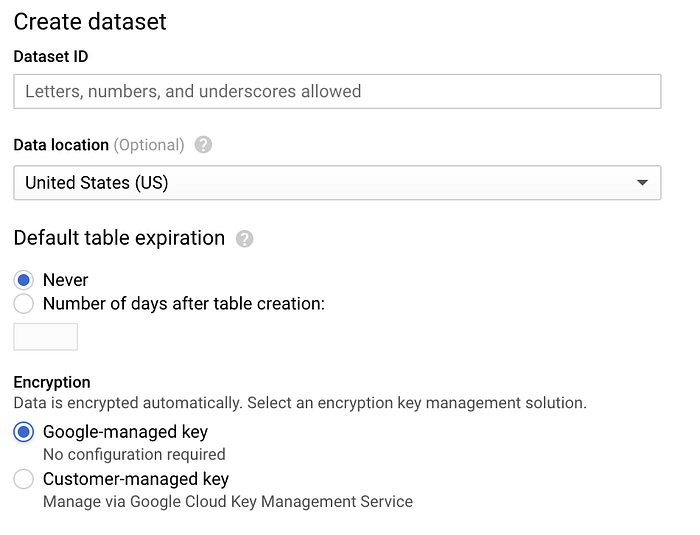
Tela de criação de dataset no BigQuery
Depois que o dataset for criado, selecione-o, clique em "Create table" e dê o nome "temperature" à nova tabela. Inclua o esquema, o particionamento e as opções de clustering mostrados nas imagens abaixo, pois eles atendem a padrões de consulta comuns:
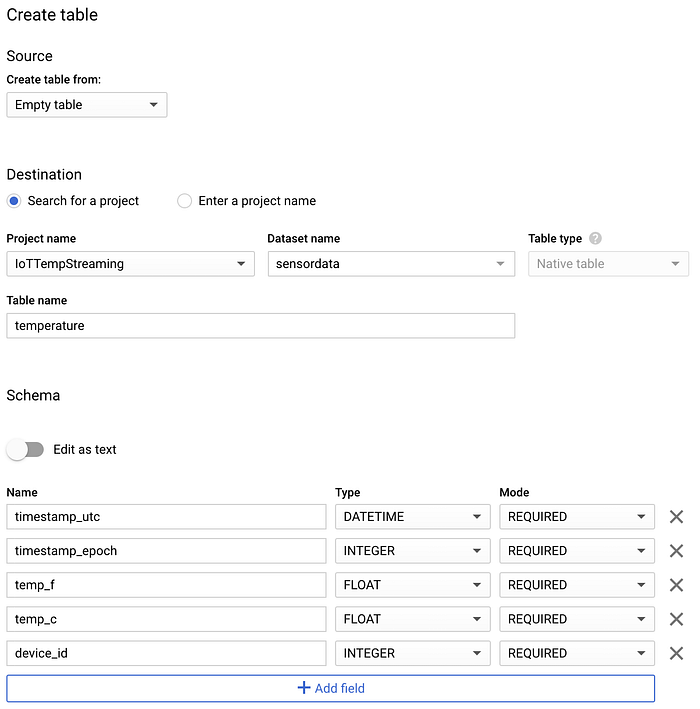
Esquema da nova tabela ‘temperature’ no BigQuery
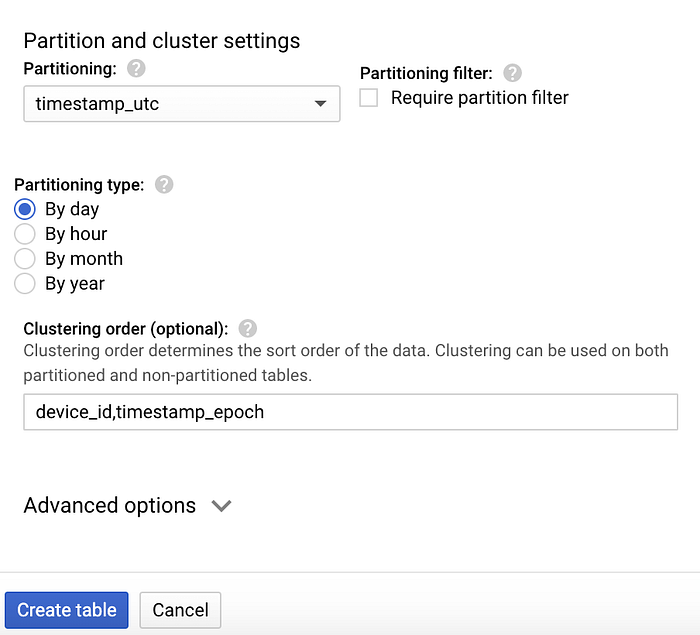
Opções de particionamento e clustering para a tabela ‘temperature’
Se tudo foi feito corretamente, sua nova tabela vazia deve ficar assim:
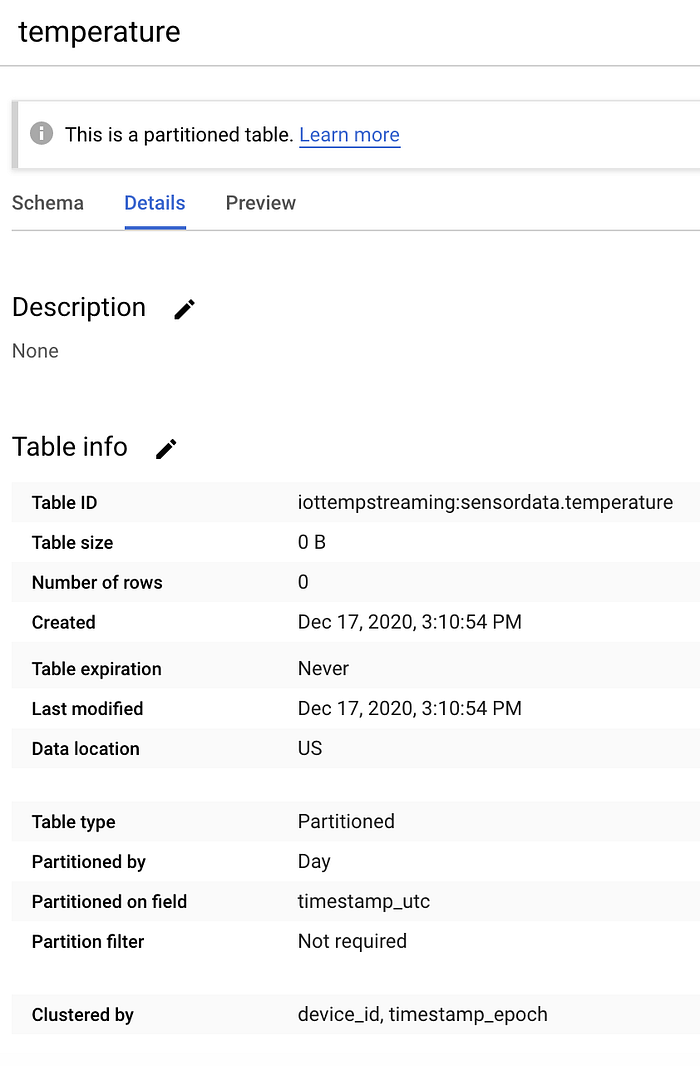
Uma tabela ‘temperature’ vazia no BigQuery, dentro do dataset ‘sensordata’
Depois que os dados forem carregados na tabela, vamos demonstrar um padrão de consulta comum em IoT: rodar análises sobre dados de uma janela de tempo específica (por exemplo, uma janela de uma hora no dia atual) e de um dispositivo específico.
O design de tabela mostrado acima é ideal para esse tipo de consulta porque:
- O particionamento pelo campo de timestamp UTC faz com que consultas filtradas por data não precisem varrer partições DateTime de dias que não correspondem ao filtro
- Dentro de uma partição, o clustering (ordenação) por deviceId e pelo timestamp epoch otimiza a recuperação dos dados de um dispositivo específico em um intervalo de tempo dentro daquela partição.
Para escrever essas consultas, precisamos de dados na tabela. Bora colocar o job do Dataflow no ar!
Configuração do Dataflow
Hoje temos mensagens em uma assinatura Pub/Sub esperando para serem movidas e uma tabela no BigQuery pronta para recebê-las. O que falta é o ETL que liga os dois. Como Pub/Sub e BigQuery são totalmente gerenciados, com auto-scaling e serverless, o ideal é uma ferramenta de ETL com essas mesmas características.
O Dataflow atende (quase totalmente) a esses requisitos. O marketing em torno do Dataflow afirma que ele tem as três características, mas, na prática, ele não é totalmente serverless. É preciso especificar os tipos e tamanhos das instâncias usadas, a contagem mínima e máxima de instâncias entre as quais o auto-scaling pode oscilar e quanto espaço temporário em disco cada instância vai precisar. Você nunca gerencia essas instâncias nem decide quando elas escalam, mas precisa fornecer essas configurações. Isso contrasta com Pub/Sub e BigQuery, que escalam automaticamente sem nenhuma configuração de infraestrutura.
Mesmo sem ser totalmente serverless, o Dataflow é uma escolha perfeita para o nosso ETL Pub/Sub-para-BigQuery. Ele também é fácil de usar, ainda mais porque o GCP oferece vários templates padrão de jobs do Dataflow, inclusive um que cobre o fluxo Pub/Sub-para-BigQuery. Tirando a necessidade de aumentar o limite máximo de instâncias do auto-scaling à medida que o throughput dos dados IoT cresce ao longo do tempo, em teoria você nunca vai precisar se preocupar em gerenciar a infraestrutura por trás do Dataflow.
Com o básico esclarecido, vamos implementar um job do Dataflow. Acesse o Dataflow, clique em "Create Job from Template" e siga estes passos:
- Dê o nome ‘pubsub-temp-to-bq’ ao job
- Use o template padrão de streaming ‘Pub/Sub Subscription to BigQuery’
- Informe o nome completo da assinatura Pub/Sub
- Informe o ID completo da tabela no BigQuery
- Informe um bucket do Cloud Storage onde dados temporários poderão ser armazenados como parte do processo do Dataflow para a carga em lote no BigQuery
- Mantenha as demais opções nos padrões. Normalmente, você expandiria as Advanced Options e definiria parâmetros como tipo e tamanho específicos da máquina, valores mínimo/máximo do auto-scaling e tamanho de disco por máquina. Mas, para fins de teste, dá para deixar nos padrões.
Sua tela de criação do job do Dataflow deve ficar parecida com esta:
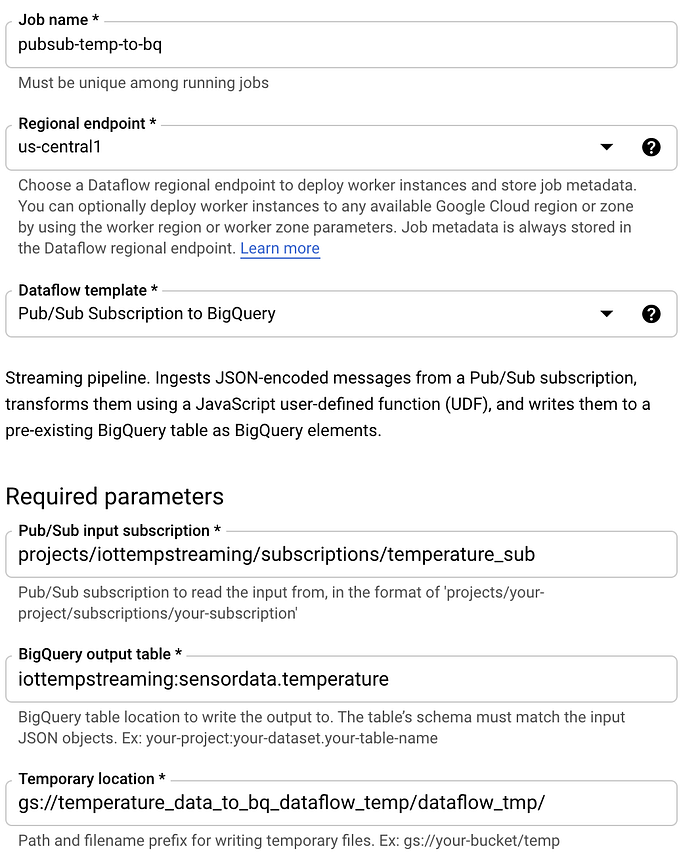
Depois de clicar em "Create" e esperar alguns minutos para a infraestrutura subjacente ser provisionada e começar a rodar, você verá os dados fluindo da assinatura Pub/Sub para a tabela de destino no BigQuery.
O script Python de streaming de temperatura disponibilizado na Parte Um envia um registro por segundo. Assim, no Directed Acyclic Graph (DAG) do Dataflow mostrado abaixo, você verá x elementos sendo transmitidos por segundo, em que x é o número de dispositivos em teste. No meu caso, são três dispositivos transmitindo:
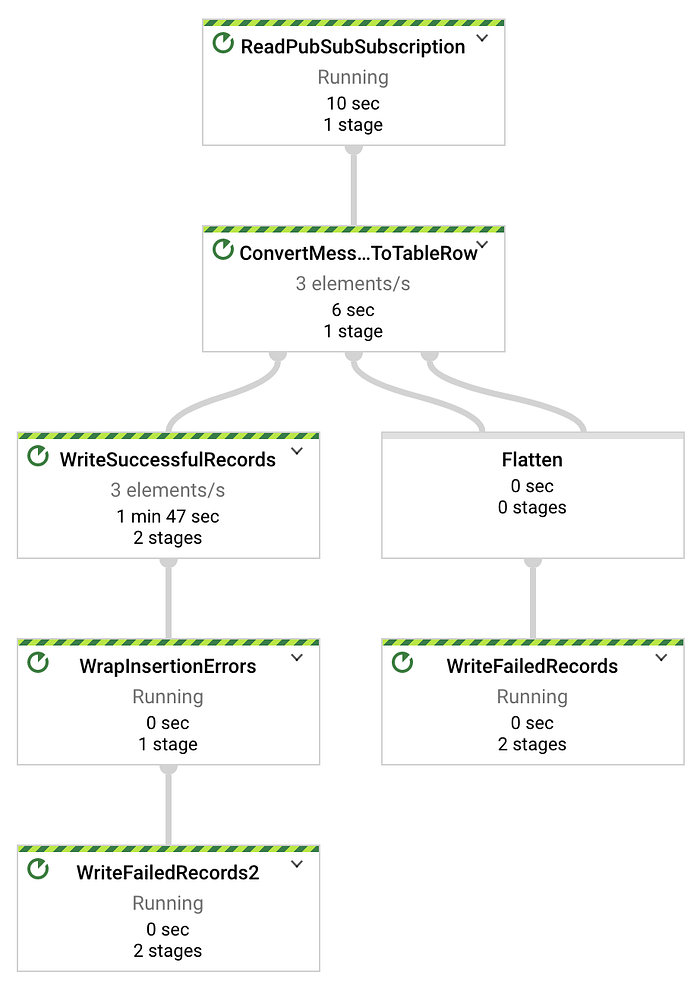
Mensagens sendo transmitidas com sucesso do Pub/Sub para o BigQuery via job do Dataflow
Quando confirmar que o job do Dataflow está ativo e transmitindo com sucesso os dados da assinatura Pub/Sub para o BigQuery, você pode rodar uma consulta no formato abaixo no BigQuery e ver os dados em tempo real chegando à tabela:
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
LIMIT 10
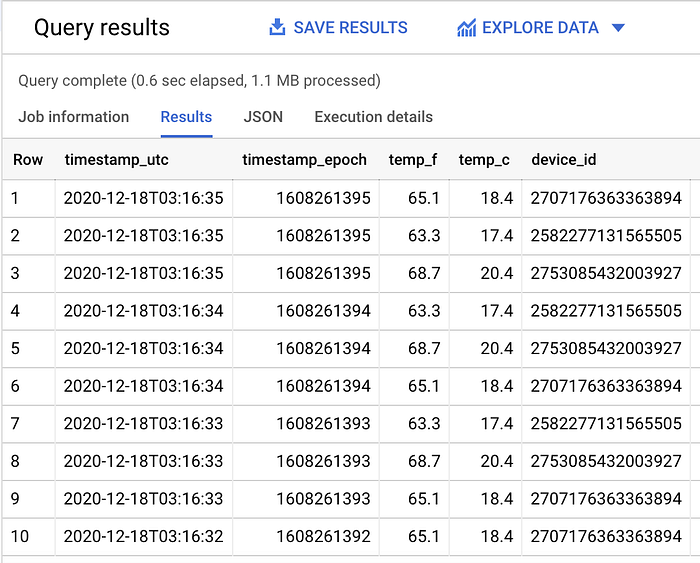
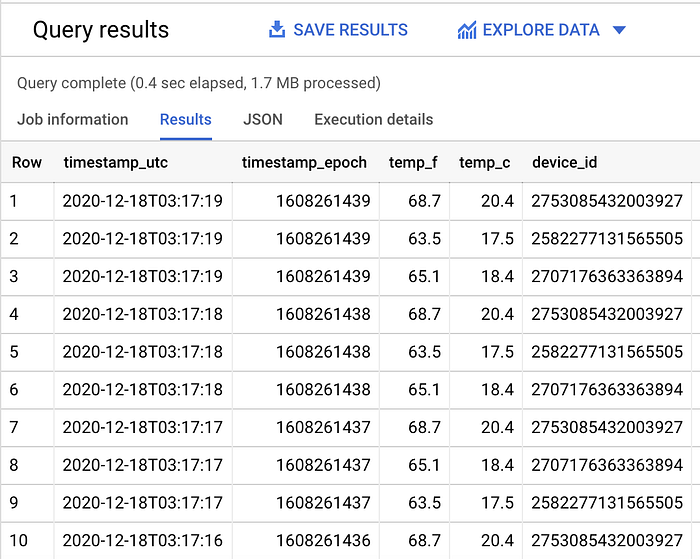
Dá para perceber que o filtro por partição está em ação: ao remover a cláusula WHERE que filtra por dia, mais dados no total são lidos.
No meu dataset de exemplo, são lidos 1,1 MB de dados filtrados (como visto acima) e 1,7 MB de dados sem filtro (mostrado abaixo):
SELECT *
FROM `iottempstreaming.sensordata.temperature`
ORDER BY timestamp_epoch DESC
LIMIT 10
Vamos ver os valores médio, mínimo e máximo de temperatura de cada sensor na última hora:
SELECT
device_id,
ROUND(AVG(temp_f), 1) AS temp_f_avg,
MIN(temp_f) AS temp_f_min,
MAX(temp_f) AS temp_f_max
FROM `iottempstreaming.sensordata.temperature`
WHERE timestamp_utc > DATETIME_ADD(CURRENT_DATETIME(), INTERVAL -60 MINUTE)
GROUP BY device_id
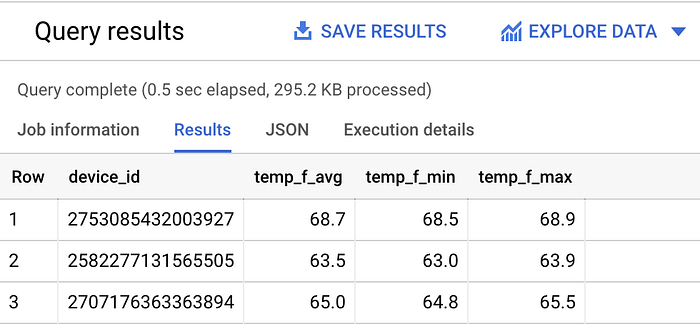
Estatísticas variadas para cada dispositivo de streaming de temperatura
Parabéns! Você acabou de montar um fluxo de dados totalmente gerenciado de ponta a ponta, da ingestão ao backend de analytics. Antes de encerrarmos este passo a passo, vamos ver rapidamente como esses dados podem ser visualizados de forma simples com o Data Studio.
Visualização dos dados armazenados
Comece executando no BigQuery uma consulta parecida com esta, que retorna todas as linhas de um dia específico:
SELECT *
FROM `iottempstreaming.sensordata.temperature`
WHERE DATE(timestamp_utc) = "2020-12-18"
ORDER BY timestamp_epoch DESC
À direita de "Query Results", clique em "Explore Data" e depois em "Explore with Data Studio":
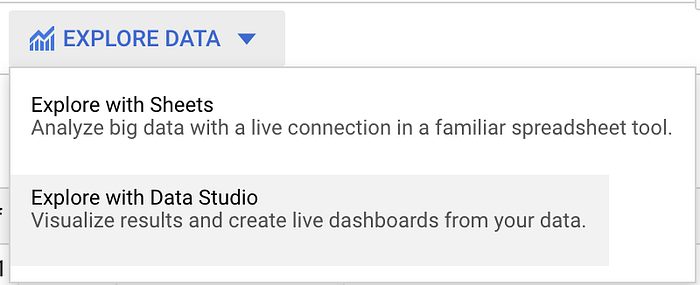
Isso vai abrir uma tabela com o resumo dos dados que acabamos de consultar. Por padrão, porém, ela traz uma tabela pouco interessante, mostrando apenas o total de registros transmitidos por segundo.
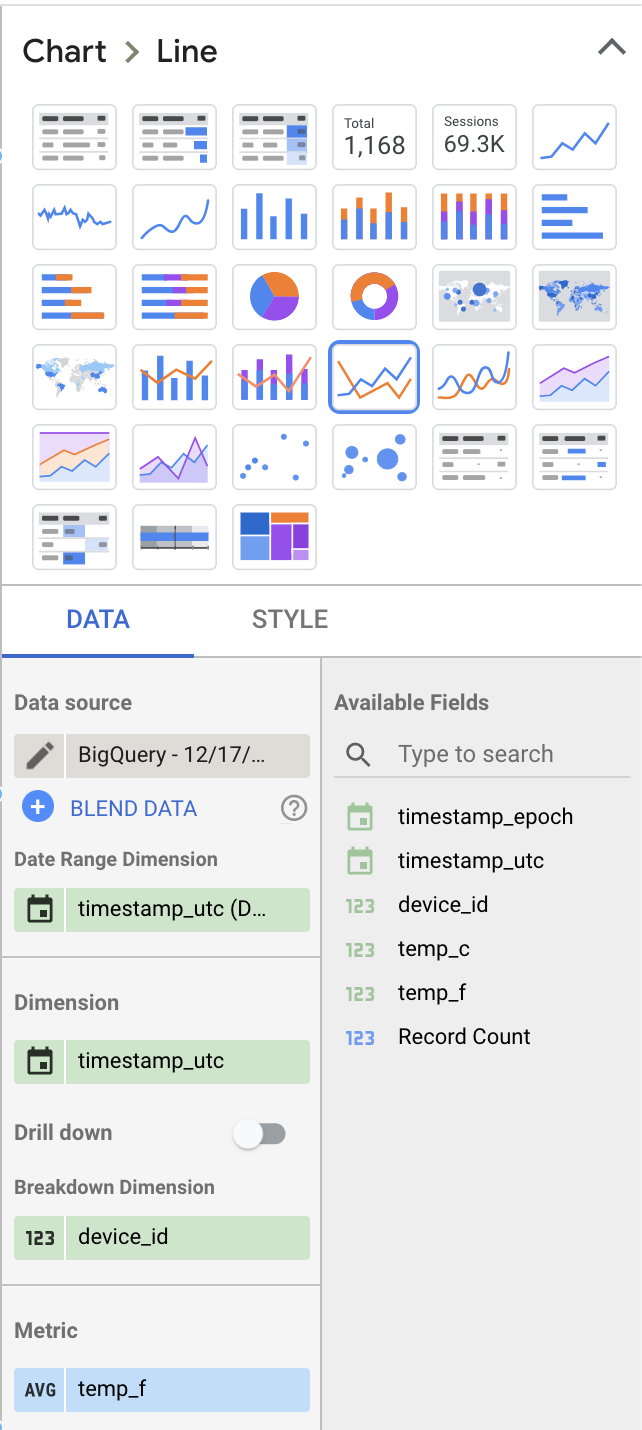
Vamos ajustar alguns valores na seção Data, à direita, para deixar a visualização mais interessante:
- Selecione "Line Chart" como tipo de visualização, no lugar de "Table"
- Remova "Record Count" como métrica e troque por "temp_f". Lembre-se de mudar a métrica padrão de "SUM" para "AVG".
- Adicione "device_id" como dimensão de agrupamento
Suas escolhas devem gerar configurações de layout do dashboard parecidas com estas:
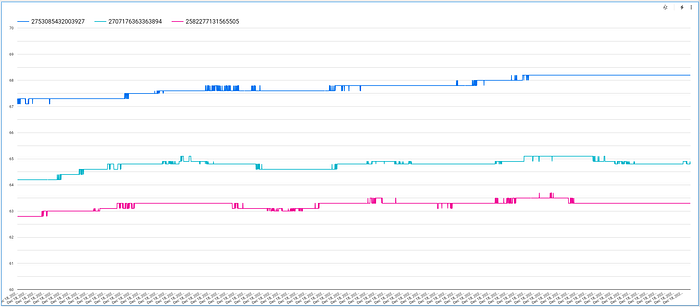
O gráfico resultante mostra os valores de temperatura por dispositivo ao longo do tempo, mas talvez não fique bem ajustado, já que o valor mínimo padrão do eixo Y é zero. Para corrigir, clique na aba "Style", role até a opção "Left Y-Axis" e ajuste para valores adequados:

Você também pode aumentar o número de pontos de dados exibidos no gráfico:
Com esses ajustes, você terá um gráfico bonito e interativo, no qual dá para navegar pelos valores de temperatura dos dispositivos enquanto eles oscilam ao longo do tempo:
A seguir: Machine Learning
Fique ligado na parte três, em que vamos construir um modelo funcional de machine learning sobre este dataset do BigQuery e usá-lo para gerar previsões em tempo real.