クラウド運用では、インフラの構築・保守といった技術面と同じくらいコスト管理が重要です。主要クラウドプロバイダーの一つであるAWSは、リレーショナルデータベース管理に強力なAmazon RDSを提供しています。しかし適切な監視と最適化を怠ると、想定外の請求額に膨らんでしまうことも珍しくありません。本記事では、RDSのコスト最適化レビュー用に作成したスクリプトをご紹介します。未使用のRDSリソースを可視化し、効率的にコストを削減するのに役立つはずです。
使われていないリソースという課題
Amazon RDSは、柔軟なスケーラビリティと高可用性を備えたマネージドデータベースサービスです。非常に便利な反面、必要以上のリソースを割り当ててRDSインスタンスを構築してしまうケースは少なくありません。こうしたインスタンスが積み重なると、クラウド予算をじわじわと圧迫する原因になります。
この問題への有効なアプローチが、RDSインスタンスの稼働状況を監視することです。CPU使用率やストレージ使用量といったメトリクスを追うことで把握できます。AWS CloudWatchはそのためのデータ収集ツールを揃えていますが、インスタンスごとにCloudWatchメトリクスを手作業で分析するのは手間がかかり、ミスも起こりがちです。そこで、スケーラビリティ・一貫性・再利用性を考慮して自動化することにしました。
"""Module to calculade RDS utilization"""
import string
from datetime import datetime, timezone, timedelta
import sys
import openpyxl
from openpyxl.styles import PatternFill, Font
import boto3
REGION = sys.argv[1] if len(sys.argv) > 1 else "us-east-1"
EXCEL_ROW_ITER = 2
column_headers = [\
"Instance",\
"Class",\
"Engine",\
"Engine version",\
"MultiAZ",\
"AZ",\
"Storage type",\
"Allocated Storage",\
"cpu < 25",\
"cpu 25-50",\
"cpu 50-74",\
"cpu > 75",\
"free storage < 25%",\
"free storage 25-50%",\
"free storage 50-74%",\
"free storage > 75%",\
]
red = PatternFill(patternType="solid", fgColor="FC2C03")
orange = PatternFill(patternType="solid", fgColor="E57909")
green = PatternFill(patternType="solid", fgColor="35FC03")
yellow = PatternFill(patternType="solid", fgColor="FCBA03")
wb = openpyxl.Workbook()
ws = wb["Sheet"]
def get_color(usage_type, usage_value):
"""Get color for utilization"""
if usage_type == "bl_25":
if 0 <= usage_value <= 25:
return green
if 25 <= usage_value <= 50:
return yellow
if 50 <= usage_value <= 75:
return red
if usage_value >= 75:
return red
if usage_type in ["bt_25_49", "bt_50_74"]:
if 0 <= usage_value <= 25:
return red
if 25 <= usage_value <= 50:
return orange
if 50 <= usage_value <= 75:
return yellow
if usage_value >= 75:
return green
if usage_type == "gt_75":
if 0 <= usage_value <= 25:
return yellow
if 25 <= usage_value <= 50:
return green
if 50 <= usage_value <= 75:
return orange
if usage_value >= 75:
return red
else:
return None
def fetch_metrics(db_instance_name, metricName):
"""Fetch metrics from cloudwatch"""
stats = cw.get_metric_statistics(
Namespace="AWS/RDS",
MetricName=metricName,
Dimensions=[\
{"Name": "DBInstanceIdentifier", "Value": db_instance_name},\
],
StartTime=datetime.now(timezone.utc) - timedelta(days=60),
EndTime=datetime.now(timezone.utc),
Period=3600,
Statistics=["Maximum"],
)
return stats
def add_row_to_excel(ws, row_data):
"""Write to excel"""
for cnt, data in enumerate(row_data):
ws[f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'] = data
if cnt == 8:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bl_25", data)
if cnt == 9:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_25_49", data)
if cnt == 10:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_50_74", data)
if cnt == 11:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("gt_75", data)
globals()["EXCEL_ROW_ITER"] += 1
# Initialize Boto3 clients
rds = boto3.client("rds", region_name=REGION)
cw = boto3.client("cloudwatch", region_name=REGION)
# Define column headers
for cnt, header in enumerate(column_headers):
cell_address = f"{string.ascii_uppercase[cnt]}1"
ws[cell_address] = header
ws[cell_address].font = Font(bold=True)
# Fetch RDS instances
response = rds.describe_db_instances()
print(f'Found {len(response["DBInstances"])} databases')
for instance_data in response["DBInstances"]:
db_instance_name = instance_data["DBInstanceIdentifier"]
db_type = instance_data["DBInstanceClass"]
db_storage = instance_data["AllocatedStorage"]
db_engine = instance_data["Engine"]
db_engine_version = instance_data["EngineVersion"]
db_multiaz = instance_data["MultiAZ"]
db_az = instance_data["AvailabilityZone"]
db_storage_type = instance_data["StorageType"]
if db_engine == "docdb":
continue # Skip docdb instances
print(f"Pulling information for {db_instance_name}")
cpu_metrics = fetch_metrics(db_instance_name, "CPUUtilization")
# Calculate usage percentages
usage_values = [d["Maximum"] for d in cpu_metrics["Datapoints"]]
cpu_usage_percentages = [\
round(\
sum(1 for value in usage_values if 25 * i <= value < 25 * (i + 1))\
/ len(usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(cpu_usage_percentages):
print(f"\tCPU {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
storage_usage_percentages = []
if db_storage_type != "aurora":
print("\tStorage found")
storage_metrics = fetch_metrics(db_instance_name, "FreeStorageSpace")
storage_usage_values = [d["Maximum"] for d in storage_metrics["Datapoints"]]
storage_usage_percentages = [\
round(\
sum(\
1\
for value in storage_usage_values\
if 25 * i\
<= value / (1024 * 1024 * 1024) / db_storage * 100\
< 25 * (i + 1)\
)\
/ len(storage_usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(storage_usage_percentages):
print(f"\tStorage {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
# Add data to Excel worksheet
row_data = (
[\
db_instance_name,\
db_type,\
db_engine,\
db_engine_version,\
db_multiaz,\
db_az,\
db_storage_type,\
db_storage,\
]
+ cpu_usage_percentages
+ storage_usage_percentages
)
add_row_to_excel(ws, row_data)
# Save the Excel workbook
wb.save("results.xlsx")
Pythonでコスト削減を自動化
低稼働のRDSインスタンスを洗い出す作業を効率化するために、汎用性が高く広く使われているPythonを活用します。
1. RDSインスタンス情報の取得
スクリプトはまずAWSに接続し、RDSインスタンスの情報を取得します。インスタンス名、タイプ、ストレージ容量など、必要なデータをまとめて収集します。
2. メトリクスデータの取得
続いて、AWS CloudWatchからCPU使用率とストレージ使用量のメトリクスを取得します。これらの値から、RDSインスタンスがどの程度活用されているかが見えてきます。
3. 使用率の算出
取得したメトリクスをもとに、CPUとストレージそれぞれの使用率を算出します。あらかじめ定めたしきい値に従って、低・中・高といった利用レベルに分類します。
4. データの可視化
スクリプトはデータを集めるだけでなく、収集した情報をExcelシートに整理して出力します。利用レベルに応じてセルを色分けするので、低稼働なリソースを一目で見つけられます。
スクリプトの使い方
このコスト削減スクリプトを最大限に活用するには、以下の手順に従ってください。
1. 前提条件
- お使いの環境にPythonがインストールされていることを確認します。
- 必要なPythonライブラリ
boto3とopenpyxlをインストールします。
pip3 install boto3 openpyxl
2. AWSの設定
- AWS認証情報がマシン上で正しく設定されていることを確認します。get-caller-identityコマンドを実行し、適切な権限を持つ正しいアカウントで作業しているかチェックしましょう。
aws sts get-caller-identity
{
"UserId": "AIDAV7DHVCA7557LUGTRA",
"Account": "410386763839",
"Arn": "arn:aws:iam::410386763839:user/bogdan"
}
3. スクリプトの実行
- 対象のAWSリージョンを引数として指定し、Pythonスクリプトを実行します(指定がない場合はデフォルトの「us-east-1」が使われます)。
python3 run.py us-east-2
4. Excelレポートの確認
- スクリプトは「results.xlsx」というExcelレポートを出力し、低稼働のRDSインスタンスを視覚的に強調表示します。このレポートを確認して、コスト削減の余地を見極めましょう。
5. アクションを起こす
- レポートをもとに、低稼働のRDSインスタンスのサイズ変更や停止を検討し、コスト削減につなげましょう。
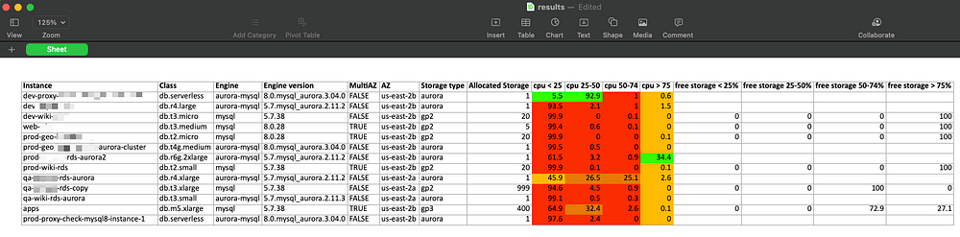
結果の読み解き方
このスクリプトは、過去60日間のCPUUtilizationメトリクスの最大値を1時間単位で取得し、0〜25、25〜50、50〜75、75〜100という4つの使用率バケットに振り分けます。
そのうえで、インスタンスの総稼働時間に対して各バケットが占める割合を算出します。
上のサンプル結果を見ると、ほとんどのデータベースが大半の時間でCPU負荷25%未満で動作していることがわかります。これらはダウンサイジング、統合、または停止の最有力候補です。
ストレージ使用量については、FreeStorageSpaceメトリクスを過去60日間1時間単位で取得し、プロビジョニング済みストレージ全体に対する割合を計算したうえで、対応する4つのバケットに振り分けます。
結果からは、いくつかのデータベースがプロビジョニング型ストレージ(gp2/gp3)を使っていることがわかります。中にはサンプリング時間の100%にわたって空き容量が75%以上あるものもあり、ストレージサイズを縮小できる明確なサインといえます。
AWSのコスト管理は、クラウドインフラ運用に欠かせない重要なテーマです。今回のPythonスクリプトを使えば、低稼働のRDSリソースを可視化する作業がぐっと楽になり、コスト削減の機会を見つけやすくなります。CloudWatchメトリクスの分析を自動化し、結果をExcelレポートにまとめることで、データに基づいた判断でAWS支出を最適化できます。
市販の監視ソリューションには及ばないものの、データを自由な切り口で分析し、好みの形で表示できる柔軟性が魅力です。次回はレポートにコスト関連の機能をさらに追加していく予定ですので、ぜひお楽しみに。