En el cloud computing, gestionar los costos es tan importante como los aspectos técnicos de desplegar y mantener la infraestructura. AWS, como uno de los principales proveedores de nube, ofrece servicios potentes como Amazon RDS para administrar bases de datos relacionales. Sin embargo, sin un monitoreo y una optimización adecuados, estos servicios pueden disparar la factura muy rápido. En este blog post comparto un script que escribí para revisiones de optimización de costos del servicio RDS, con el que podrás ganar visibilidad sobre los recursos de RDS sin uso y reducir costos de forma efectiva.
El reto de los recursos subutilizados
Amazon RDS es un servicio de base de datos administrado que ofrece escalabilidad sencilla y alta disponibilidad. Aunque esto resulta muy valioso, no es raro que se aprovisionen instancias de RDS con más recursos de los que realmente se necesitan. Con el tiempo, esas instancias se acumulan y se vuelven un gasto innecesario para tu presupuesto en la nube.
Una forma de atacar este problema es monitorear tus instancias de RDS para detectar la subutilización. Esto se logra haciendo seguimiento, entre otras métricas, al uso de CPU y al consumo de almacenamiento. AWS CloudWatch ofrece las herramientas necesarias para recopilar esos datos. Sin embargo, analizar manualmente las métricas de CloudWatch para cada instancia de RDS puede ser tedioso y propenso a errores, así que decidí automatizarlo, tanto por escalabilidad y consistencia como para poder reutilizarlo a futuro.
"""Module to calculade RDS utilization"""
import string
from datetime import datetime, timezone, timedelta
import sys
import openpyxl
from openpyxl.styles import PatternFill, Font
import boto3
REGION = sys.argv[1] if len(sys.argv) > 1 else "us-east-1"
EXCEL_ROW_ITER = 2
column_headers = [\
"Instance",\
"Class",\
"Engine",\
"Engine version",\
"MultiAZ",\
"AZ",\
"Storage type",\
"Allocated Storage",\
"cpu < 25",\
"cpu 25-50",\
"cpu 50-74",\
"cpu > 75",\
"free storage < 25%",\
"free storage 25-50%",\
"free storage 50-74%",\
"free storage > 75%",\
]
red = PatternFill(patternType="solid", fgColor="FC2C03")
orange = PatternFill(patternType="solid", fgColor="E57909")
green = PatternFill(patternType="solid", fgColor="35FC03")
yellow = PatternFill(patternType="solid", fgColor="FCBA03")
wb = openpyxl.Workbook()
ws = wb["Sheet"]
def get_color(usage_type, usage_value):
"""Get color for utilization"""
if usage_type == "bl_25":
if 0 <= usage_value <= 25:
return green
if 25 <= usage_value <= 50:
return yellow
if 50 <= usage_value <= 75:
return red
if usage_value >= 75:
return red
if usage_type in ["bt_25_49", "bt_50_74"]:
if 0 <= usage_value <= 25:
return red
if 25 <= usage_value <= 50:
return orange
if 50 <= usage_value <= 75:
return yellow
if usage_value >= 75:
return green
if usage_type == "gt_75":
if 0 <= usage_value <= 25:
return yellow
if 25 <= usage_value <= 50:
return green
if 50 <= usage_value <= 75:
return orange
if usage_value >= 75:
return red
else:
return None
def fetch_metrics(db_instance_name, metricName):
"""Fetch metrics from cloudwatch"""
stats = cw.get_metric_statistics(
Namespace="AWS/RDS",
MetricName=metricName,
Dimensions=[\
{"Name": "DBInstanceIdentifier", "Value": db_instance_name},\
],
StartTime=datetime.now(timezone.utc) - timedelta(days=60),
EndTime=datetime.now(timezone.utc),
Period=3600,
Statistics=["Maximum"],
)
return stats
def add_row_to_excel(ws, row_data):
"""Write to excel"""
for cnt, data in enumerate(row_data):
ws[f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'] = data
if cnt == 8:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bl_25", data)
if cnt == 9:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_25_49", data)
if cnt == 10:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_50_74", data)
if cnt == 11:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("gt_75", data)
globals()["EXCEL_ROW_ITER"] += 1
# Initialize Boto3 clients
rds = boto3.client("rds", region_name=REGION)
cw = boto3.client("cloudwatch", region_name=REGION)
# Define column headers
for cnt, header in enumerate(column_headers):
cell_address = f"{string.ascii_uppercase[cnt]}1"
ws[cell_address] = header
ws[cell_address].font = Font(bold=True)
# Fetch RDS instances
response = rds.describe_db_instances()
print(f'Found {len(response["DBInstances"])} databases')
for instance_data in response["DBInstances"]:
db_instance_name = instance_data["DBInstanceIdentifier"]
db_type = instance_data["DBInstanceClass"]
db_storage = instance_data["AllocatedStorage"]
db_engine = instance_data["Engine"]
db_engine_version = instance_data["EngineVersion"]
db_multiaz = instance_data["MultiAZ"]
db_az = instance_data["AvailabilityZone"]
db_storage_type = instance_data["StorageType"]
if db_engine == "docdb":
continue # Skip docdb instances
print(f"Pulling information for {db_instance_name}")
cpu_metrics = fetch_metrics(db_instance_name, "CPUUtilization")
# Calculate usage percentages
usage_values = [d["Maximum"] for d in cpu_metrics["Datapoints"]]
cpu_usage_percentages = [\
round(\
sum(1 for value in usage_values if 25 * i <= value < 25 * (i + 1))\
/ len(usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(cpu_usage_percentages):
print(f"\tCPU {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
storage_usage_percentages = []
if db_storage_type != "aurora":
print("\tStorage found")
storage_metrics = fetch_metrics(db_instance_name, "FreeStorageSpace")
storage_usage_values = [d["Maximum"] for d in storage_metrics["Datapoints"]]
storage_usage_percentages = [\
round(\
sum(\
1\
for value in storage_usage_values\
if 25 * i\
<= value / (1024 * 1024 * 1024) / db_storage * 100\
< 25 * (i + 1)\
)\
/ len(storage_usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(storage_usage_percentages):
print(f"\tStorage {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
# Add data to Excel worksheet
row_data = (
[\
db_instance_name,\
db_type,\
db_engine,\
db_engine_version,\
db_multiaz,\
db_az,\
db_storage_type,\
db_storage,\
]
+ cpu_usage_percentages
+ storage_usage_percentages
)
add_row_to_excel(ws, row_data)
# Save the Excel workbook
wb.save("results.xlsx")
Automatizar la reducción de costos con Python
Para agilizar la identificación de instancias de RDS subutilizadas, podemos apoyarnos en Python, un lenguaje de programación versátil y muy extendido.
1. Obtener los datos de las instancias de RDS
El script empieza por conectarse a AWS y traer los datos de tus instancias de RDS. Recopila información clave como nombres de instancia, tipos, almacenamiento y más.
2. Recopilar datos de métricas
Después, el script consulta AWS CloudWatch para obtener métricas de uso de CPU y de almacenamiento. Esas métricas dan una idea clara de qué tan bien se están aprovechando tus instancias de RDS.
3. Calcular los porcentajes de utilización
Con las métricas recopiladas, el script calcula los porcentajes de utilización tanto de CPU como de almacenamiento. Esos porcentajes se clasifican en distintos niveles de uso (por ejemplo, bajo, moderado, alto) según umbrales predefinidos.
4. Visualizar los datos
El script no se queda en recopilar datos; también arma una hoja de cálculo de Excel con la información obtenida. Usa celdas con código de colores para resaltar las instancias según su nivel de uso, lo que permite detectar de un vistazo los recursos subutilizados.
Cómo poner el script en práctica
Para sacarle el máximo provecho a este script de ahorro de costos, sigue estos pasos:
1. Requisitos previos
- Asegúrate de tener Python instalado en tu sistema.
- Instala las librerías de Python necesarias:
boto3yopenpyxl.
pip3 install boto3 openpyxl
2. Configuración de AWS
- Verifica que tus credenciales de AWS estén bien configuradas en tu equipo. Ejecuta el comando get-caller-identity y confirma que estás en la cuenta correcta y con los permisos adecuados.
aws sts get-caller-identity
{
"UserId": "AIDAV7DHVCA7557LUGTRA",
"Account": "410386763839",
"Arn": "arn:aws:iam::410386763839:user/bogdan"
}
3. Ejecuta el script
- Ejecuta el script de Python pasando como argumento la región de AWS deseada (o deja la predeterminada "us-east-1").
python3 run.py us-east-2
4. Revisa el reporte de Excel
- El script genera un reporte de Excel llamado "results.xlsx" que resalta visualmente las instancias de RDS subutilizadas. Revísalo para detectar oportunidades de ahorro.
5. Toma acción
- Con base en el reporte, evalúa redimensionar o dar de baja las instancias de RDS subutilizadas para reducir costos.
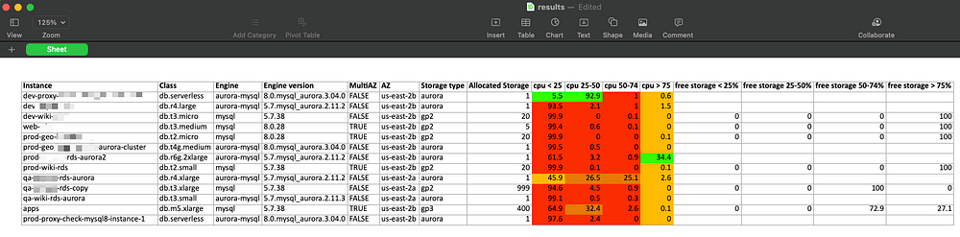
Cómo interpretar los resultados
El script obtiene la métrica máxima de CPUUtilization de los últimos 60 días, en intervalos de 1 hora, y la distribuye en 4 rangos de uso: 0–25, 25–50, 50–75 y 75–100.
Después calcula el porcentaje de horas totales en cada rango respecto al total de horas en operación de la instancia.
En los resultados de muestra de arriba se observa que la mayoría de las bases de datos pasa la mayor parte del tiempo por debajo del 25% de carga de CPU: son las primeras candidatas para reducir tamaño, consolidar o dar de baja.
Para el almacenamiento, obtiene la métrica FreeStorageSpace de los últimos 60 días en intervalos de 1 hora, calcula su porcentaje sobre el almacenamiento total aprovisionado y lo distribuye en 4 rangos correspondientes.
Se aprecia que algunas bases de datos están utilizando almacenamiento aprovisionado (gp2/gp3). En varias de ellas, durante el 100% de las horas muestreadas, queda 75% o más de almacenamiento libre. Es un indicador claro de que el tamaño del almacenamiento puede reducirse en esas bases de datos.
Gestionar los costos de AWS es un aspecto esencial de la administración de la infraestructura en la nube. Este script de Python simplifica el proceso de ganar visibilidad sobre los recursos de RDS subutilizados y facilita detectar oportunidades de ahorro. Al automatizar el análisis de las métricas de CloudWatch y visualizar los resultados en un reporte de Excel, puedes tomar decisiones basadas en datos para optimizar tu gasto en AWS.
Si bien no se compara con soluciones de monitoreo listas para usar, te da la flexibilidad de segmentar y analizar los datos como quieras, además de presentarlos a tu manera. En la próxima entrega sumaré más funcionalidades relacionadas con costos al reporte, así que mantente atento.