Na computação em nuvem, controlar custos é tão importante quanto os aspectos técnicos de implantar e manter a infraestrutura. A AWS, uma das principais provedoras do mercado, oferece serviços robustos como o Amazon RDS para gerenciar bancos de dados relacionais. Mas, sem monitoramento e otimização adequados, esses serviços podem facilmente gerar contas inesperadas. Neste post, compartilho um script que escrevi para revisões de otimização de custos do RDS, que ajuda a ter visibilidade sobre recursos subutilizados e a reduzir custos de forma eficaz.
O desafio dos recursos subutilizados
O Amazon RDS é um serviço de banco de dados gerenciado que entrega escalabilidade e alta disponibilidade com facilidade. Por mais valioso que isso seja, é comum ver usuários provisionando instâncias do RDS com muito mais recursos do que precisam. Com o tempo, essas instâncias se acumulam e viram um peso desnecessário no orçamento de nuvem.
Uma forma de lidar com isso é monitorar a subutilização das suas instâncias do RDS, acompanhando o uso de CPU, de armazenamento e outras métricas. O AWS CloudWatch oferece as ferramentas para coletar esses dados. Só que analisar manualmente as métricas do CloudWatch para cada instância do RDS é demorado e sujeito a erros — por isso decidi automatizar tudo, pensando em escalabilidade, consistência e reaproveitamento futuro.
"""Module to calculade RDS utilization"""
import string
from datetime import datetime, timezone, timedelta
import sys
import openpyxl
from openpyxl.styles import PatternFill, Font
import boto3
REGION = sys.argv[1] if len(sys.argv) > 1 else "us-east-1"
EXCEL_ROW_ITER = 2
column_headers = [\
"Instance",\
"Class",\
"Engine",\
"Engine version",\
"MultiAZ",\
"AZ",\
"Storage type",\
"Allocated Storage",\
"cpu < 25",\
"cpu 25-50",\
"cpu 50-74",\
"cpu > 75",\
"free storage < 25%",\
"free storage 25-50%",\
"free storage 50-74%",\
"free storage > 75%",\
]
red = PatternFill(patternType="solid", fgColor="FC2C03")
orange = PatternFill(patternType="solid", fgColor="E57909")
green = PatternFill(patternType="solid", fgColor="35FC03")
yellow = PatternFill(patternType="solid", fgColor="FCBA03")
wb = openpyxl.Workbook()
ws = wb["Sheet"]
def get_color(usage_type, usage_value):
"""Get color for utilization"""
if usage_type == "bl_25":
if 0 <= usage_value <= 25:
return green
if 25 <= usage_value <= 50:
return yellow
if 50 <= usage_value <= 75:
return red
if usage_value >= 75:
return red
if usage_type in ["bt_25_49", "bt_50_74"]:
if 0 <= usage_value <= 25:
return red
if 25 <= usage_value <= 50:
return orange
if 50 <= usage_value <= 75:
return yellow
if usage_value >= 75:
return green
if usage_type == "gt_75":
if 0 <= usage_value <= 25:
return yellow
if 25 <= usage_value <= 50:
return green
if 50 <= usage_value <= 75:
return orange
if usage_value >= 75:
return red
else:
return None
def fetch_metrics(db_instance_name, metricName):
"""Fetch metrics from cloudwatch"""
stats = cw.get_metric_statistics(
Namespace="AWS/RDS",
MetricName=metricName,
Dimensions=[\
{"Name": "DBInstanceIdentifier", "Value": db_instance_name},\
],
StartTime=datetime.now(timezone.utc) - timedelta(days=60),
EndTime=datetime.now(timezone.utc),
Period=3600,
Statistics=["Maximum"],
)
return stats
def add_row_to_excel(ws, row_data):
"""Write to excel"""
for cnt, data in enumerate(row_data):
ws[f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'] = data
if cnt == 8:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bl_25", data)
if cnt == 9:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_25_49", data)
if cnt == 10:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_50_74", data)
if cnt == 11:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("gt_75", data)
globals()["EXCEL_ROW_ITER"] += 1
# Initialize Boto3 clients
rds = boto3.client("rds", region_name=REGION)
cw = boto3.client("cloudwatch", region_name=REGION)
# Define column headers
for cnt, header in enumerate(column_headers):
cell_address = f"{string.ascii_uppercase[cnt]}1"
ws[cell_address] = header
ws[cell_address].font = Font(bold=True)
# Fetch RDS instances
response = rds.describe_db_instances()
print(f'Found {len(response["DBInstances"])} databases')
for instance_data in response["DBInstances"]:
db_instance_name = instance_data["DBInstanceIdentifier"]
db_type = instance_data["DBInstanceClass"]
db_storage = instance_data["AllocatedStorage"]
db_engine = instance_data["Engine"]
db_engine_version = instance_data["EngineVersion"]
db_multiaz = instance_data["MultiAZ"]
db_az = instance_data["AvailabilityZone"]
db_storage_type = instance_data["StorageType"]
if db_engine == "docdb":
continue # Skip docdb instances
print(f"Pulling information for {db_instance_name}")
cpu_metrics = fetch_metrics(db_instance_name, "CPUUtilization")
# Calculate usage percentages
usage_values = [d["Maximum"] for d in cpu_metrics["Datapoints"]]
cpu_usage_percentages = [\
round(\
sum(1 for value in usage_values if 25 * i <= value < 25 * (i + 1))\
/ len(usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(cpu_usage_percentages):
print(f"\tCPU {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
storage_usage_percentages = []
if db_storage_type != "aurora":
print("\tStorage found")
storage_metrics = fetch_metrics(db_instance_name, "FreeStorageSpace")
storage_usage_values = [d["Maximum"] for d in storage_metrics["Datapoints"]]
storage_usage_percentages = [\
round(\
sum(\
1\
for value in storage_usage_values\
if 25 * i\
<= value / (1024 * 1024 * 1024) / db_storage * 100\
< 25 * (i + 1)\
)\
/ len(storage_usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(storage_usage_percentages):
print(f"\tStorage {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
# Add data to Excel worksheet
row_data = (
[\
db_instance_name,\
db_type,\
db_engine,\
db_engine_version,\
db_multiaz,\
db_az,\
db_storage_type,\
db_storage,\
]
+ cpu_usage_percentages
+ storage_usage_percentages
)
add_row_to_excel(ws, row_data)
# Save the Excel workbook
wb.save("results.xlsx")
Automatizando a redução de custos com Python
Para agilizar a identificação de instâncias do RDS subutilizadas, dá para recorrer ao Python — uma linguagem versátil e amplamente adotada.
1. Coletando dados das instâncias do RDS
O script começa se conectando à AWS e puxando dados das suas instâncias do RDS. Ele reúne informações essenciais como nome, classe, armazenamento e mais.
2. Coletando métricas
Em seguida, o script consulta o AWS CloudWatch em busca de métricas de uso de CPU e de armazenamento. Essas métricas mostram o quanto suas instâncias do RDS estão realmente sendo aproveitadas.
3. Calculando os percentuais de utilização
Com as métricas em mãos, o script calcula os percentuais de utilização de CPU e de armazenamento, classificando-os em diferentes níveis de uso (baixo, moderado, alto, por exemplo) com base em limites pré-definidos.
4. Visualizando os dados
O script não para na coleta: também gera uma planilha do Excel com tudo o que foi reunido. Ele usa células com cores para destacar instâncias em diferentes níveis de utilização, deixando os recursos subutilizados visíveis num piscar de olhos.
Colocando o script em prática
Para tirar o máximo proveito desse script de redução de custos, siga estes passos:
1. Pré-requisitos
- Tenha o Python instalado na sua máquina.
- Instale as bibliotecas Python necessárias:
boto3eopenpyxl.
pip3 install boto3 openpyxl
2. Configuração da AWS
- Confira se as suas credenciais da AWS estão configuradas corretamente. Rode o comando get-caller-identity e confirme que está na conta certa, com as permissões adequadas.
aws sts get-caller-identity
{
"UserId": "AIDAV7DHVCA7557LUGTRA",
"Account": "410386763839",
"Arn": "arn:aws:iam::410386763839:user/bogdan"
}
3. Execute o script
- Rode o script Python passando a região da AWS desejada como argumento (ou use a padrão 'us-east-1').
python3 run.py us-east-2
4. Analise o relatório em Excel
- O script gera um relatório em Excel chamado "results.xlsx" que destaca visualmente as instâncias do RDS subutilizadas. Use esse relatório para identificar oportunidades de economia.
5. Tome decisões
- Com base no relatório, considere redimensionar ou encerrar as instâncias do RDS subutilizadas para cortar custos.
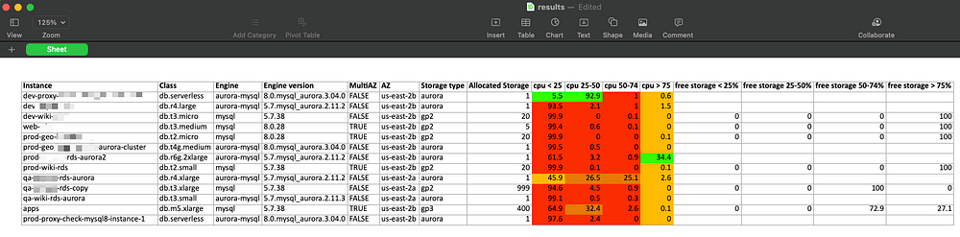
Interpretando os resultados
O script busca a métrica CPUUtilization máxima dos últimos 60 dias em períodos de 1 hora e a distribui em 4 faixas de utilização: 0–25, 25–50, 50–75 e 75–100.
Depois, ele calcula o percentual do total de horas em cada faixa em relação ao tempo total de funcionamento da instância.
Nos resultados de exemplo acima, dá para ver que a maioria dos bancos passa boa parte do tempo abaixo de 25% de uso de CPU — esses são os primeiros candidatos a downsizing, consolidação ou término.
Para o uso de armazenamento, o script puxa a métrica FreeStorageSpace dos últimos 60 dias em janelas de 1 hora, calcula o percentual em relação ao armazenamento total provisionado e o distribui em 4 faixas correspondentes.
Dá para notar que alguns bancos usam armazenamento provisionado (gp2/gp3). E, em alguns deles, em 100% das horas amostradas, sobram 75% ou mais de espaço livre. É um indicador claro de que o tamanho do armazenamento pode ser reduzido nesses bancos.
Gerenciar custos da AWS é parte essencial da gestão de infraestrutura em nuvem. Esse script Python simplifica a tarefa de obter visibilidade sobre recursos do RDS subutilizados, facilitando identificar oportunidades de economia. Ao automatizar a análise das métricas do CloudWatch e visualizar os resultados em um relatório do Excel, você toma decisões baseadas em dados para otimizar seus gastos com a AWS.
Embora não dê para comparar com soluções de monitoramento prontas para uso, o script oferece flexibilidade para fatiar e cruzar os dados como quiser, além de apresentá-los do jeito que preferir. Na próxima série, vou incluir mais funcionalidades de custo no relatório, então fique de olho.