Dans le cloud computing, maîtriser les coûts compte autant que les aspects techniques du déploiement et de la maintenance de l'infrastructure. AWS, l'un des principaux fournisseurs cloud, propose des services puissants comme Amazon RDS pour la gestion des bases de données relationnelles. Sans surveillance ni optimisation appropriées, ces services peuvent toutefois faire vite grimper la facture. Dans cet article, je partage un script que j'ai conçu pour les revues d'optimisation des coûts du service RDS : il vous aidera à y voir clair sur les ressources RDS inutilisées et à réduire efficacement vos dépenses.
Le défi des ressources sous-utilisées
Amazon RDS est un service de bases de données managé qui offre une scalabilité simple et une haute disponibilité. C'est un atout précieux, mais il n'est pas rare de provisionner des instances RDS avec bien plus de ressources que nécessaire. Au fil du temps, ces instances s'accumulent et pèsent inutilement sur le budget cloud.
Pour s'attaquer au problème, on peut surveiller la sous-utilisation des instances RDS, notamment via l'utilisation du CPU et du stockage, parmi d'autres métriques. AWS CloudWatch fournit les outils nécessaires pour collecter ces données. Analyser manuellement les métriques CloudWatch pour chaque instance RDS reste cependant chronophage et source d'erreurs ; j'ai donc choisi d'automatiser ce processus, à la fois pour la scalabilité, la cohérence et la réutilisabilité.
"""Module to calculade RDS utilization"""
import string
from datetime import datetime, timezone, timedelta
import sys
import openpyxl
from openpyxl.styles import PatternFill, Font
import boto3
REGION = sys.argv[1] if len(sys.argv) > 1 else "us-east-1"
EXCEL_ROW_ITER = 2
column_headers = [\
"Instance",\
"Class",\
"Engine",\
"Engine version",\
"MultiAZ",\
"AZ",\
"Storage type",\
"Allocated Storage",\
"cpu < 25",\
"cpu 25-50",\
"cpu 50-74",\
"cpu > 75",\
"free storage < 25%",\
"free storage 25-50%",\
"free storage 50-74%",\
"free storage > 75%",\
]
red = PatternFill(patternType="solid", fgColor="FC2C03")
orange = PatternFill(patternType="solid", fgColor="E57909")
green = PatternFill(patternType="solid", fgColor="35FC03")
yellow = PatternFill(patternType="solid", fgColor="FCBA03")
wb = openpyxl.Workbook()
ws = wb["Sheet"]
def get_color(usage_type, usage_value):
"""Get color for utilization"""
if usage_type == "bl_25":
if 0 <= usage_value <= 25:
return green
if 25 <= usage_value <= 50:
return yellow
if 50 <= usage_value <= 75:
return red
if usage_value >= 75:
return red
if usage_type in ["bt_25_49", "bt_50_74"]:
if 0 <= usage_value <= 25:
return red
if 25 <= usage_value <= 50:
return orange
if 50 <= usage_value <= 75:
return yellow
if usage_value >= 75:
return green
if usage_type == "gt_75":
if 0 <= usage_value <= 25:
return yellow
if 25 <= usage_value <= 50:
return green
if 50 <= usage_value <= 75:
return orange
if usage_value >= 75:
return red
else:
return None
def fetch_metrics(db_instance_name, metricName):
"""Fetch metrics from cloudwatch"""
stats = cw.get_metric_statistics(
Namespace="AWS/RDS",
MetricName=metricName,
Dimensions=[\
{"Name": "DBInstanceIdentifier", "Value": db_instance_name},\
],
StartTime=datetime.now(timezone.utc) - timedelta(days=60),
EndTime=datetime.now(timezone.utc),
Period=3600,
Statistics=["Maximum"],
)
return stats
def add_row_to_excel(ws, row_data):
"""Write to excel"""
for cnt, data in enumerate(row_data):
ws[f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'] = data
if cnt == 8:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bl_25", data)
if cnt == 9:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_25_49", data)
if cnt == 10:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_50_74", data)
if cnt == 11:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("gt_75", data)
globals()["EXCEL_ROW_ITER"] += 1
# Initialize Boto3 clients
rds = boto3.client("rds", region_name=REGION)
cw = boto3.client("cloudwatch", region_name=REGION)
# Define column headers
for cnt, header in enumerate(column_headers):
cell_address = f"{string.ascii_uppercase[cnt]}1"
ws[cell_address] = header
ws[cell_address].font = Font(bold=True)
# Fetch RDS instances
response = rds.describe_db_instances()
print(f'Found {len(response["DBInstances"])} databases')
for instance_data in response["DBInstances"]:
db_instance_name = instance_data["DBInstanceIdentifier"]
db_type = instance_data["DBInstanceClass"]
db_storage = instance_data["AllocatedStorage"]
db_engine = instance_data["Engine"]
db_engine_version = instance_data["EngineVersion"]
db_multiaz = instance_data["MultiAZ"]
db_az = instance_data["AvailabilityZone"]
db_storage_type = instance_data["StorageType"]
if db_engine == "docdb":
continue # Skip docdb instances
print(f"Pulling information for {db_instance_name}")
cpu_metrics = fetch_metrics(db_instance_name, "CPUUtilization")
# Calculate usage percentages
usage_values = [d["Maximum"] for d in cpu_metrics["Datapoints"]]
cpu_usage_percentages = [\
round(\
sum(1 for value in usage_values if 25 * i <= value < 25 * (i + 1))\
/ len(usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(cpu_usage_percentages):
print(f"\tCPU {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
storage_usage_percentages = []
if db_storage_type != "aurora":
print("\tStorage found")
storage_metrics = fetch_metrics(db_instance_name, "FreeStorageSpace")
storage_usage_values = [d["Maximum"] for d in storage_metrics["Datapoints"]]
storage_usage_percentages = [\
round(\
sum(\
1\
for value in storage_usage_values\
if 25 * i\
<= value / (1024 * 1024 * 1024) / db_storage * 100\
< 25 * (i + 1)\
)\
/ len(storage_usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(storage_usage_percentages):
print(f"\tStorage {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
# Add data to Excel worksheet
row_data = (
[\
db_instance_name,\
db_type,\
db_engine,\
db_engine_version,\
db_multiaz,\
db_az,\
db_storage_type,\
db_storage,\
]
+ cpu_usage_percentages
+ storage_usage_percentages
)
add_row_to_excel(ws, row_data)
# Save the Excel workbook
wb.save("results.xlsx")
Automatiser la réduction des coûts avec Python
Pour accélérer l'identification des instances RDS sous-utilisées, on peut s'appuyer sur Python, un langage polyvalent et largement adopté.
1. Récupération des données des instances RDS
Le script se connecte d'abord à AWS et récupère les données de vos instances RDS. Il collecte des informations clés : noms d'instances, types, stockage, et bien d'autres.
2. Collecte des données de métriques
Le script interroge ensuite AWS CloudWatch pour obtenir les métriques d'utilisation du CPU et du stockage. Elles permettent d'évaluer l'efficacité réelle d'utilisation de vos instances RDS.
3. Calcul des pourcentages d'utilisation
À partir des métriques collectées, le script calcule les pourcentages d'utilisation pour le CPU et le stockage. Ces pourcentages sont répartis selon différents niveaux d'usage (faible, modéré, élevé) en fonction de seuils prédéfinis.
4. Visualisation des données
Le script ne se contente pas de collecter les données : il génère également une feuille de calcul Excel à partir des informations recueillies. Un code couleur dans les cellules met en évidence les instances selon leur niveau d'utilisation, ce qui permet de repérer en un coup d'œil les ressources sous-utilisées.
Mettre le script en pratique
Pour tirer le meilleur parti de ce script d'optimisation des coûts, suivez ces étapes :
1. Prérequis
- Vérifiez que Python est installé sur votre système.
- Installez les bibliothèques Python requises :
boto3etopenpyxl.
pip3 install boto3 openpyxl
2. Configuration AWS
- Vérifiez que vos identifiants AWS sont correctement configurés sur votre machine. Lancez la commande get-caller-identity pour confirmer que vous êtes bien sur le bon compte avec les permissions adéquates.
aws sts get-caller-identity
{
"UserId": "AIDAV7DHVCA7557LUGTRA",
"Account": "410386763839",
"Arn": "arn:aws:iam::410386763839:user/bogdan"
}
3. Exécuter le script
- Lancez le script Python en passant la région AWS souhaitée en argument (ou utilisez la valeur par défaut us-east-1).
python3 run.py us-east-2
4. Consulter le rapport Excel
- Le script génère un rapport Excel nommé results.xlsx qui met visuellement en évidence les instances RDS sous-utilisées. Examinez-le pour identifier les pistes d'économies.
5. Passer à l'action
- Sur la base du rapport, envisagez de redimensionner ou de supprimer les instances RDS sous-utilisées pour réduire les coûts.
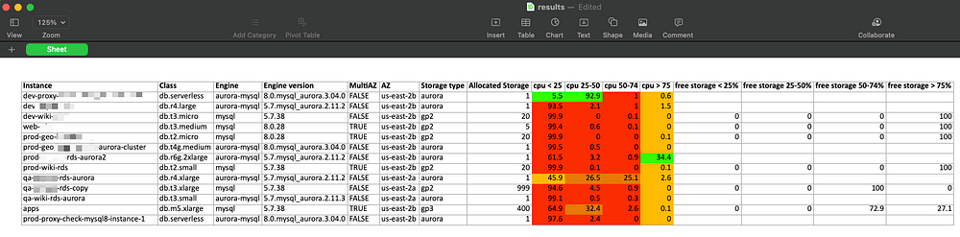
Interpréter les résultats
Le script récupère la métrique CPUUtilization maximale sur les 60 derniers jours, par tranches d'une heure, et la répartit dans 4 paliers d'utilisation : 0–25, 25–50, 50–75 et 75–100.
Il calcule ensuite, pour chaque palier, sa part dans le nombre total d'heures de fonctionnement de l'instance.
Dans l'exemple de résultats ci-dessus, on voit que la plupart des bases passent l'essentiel de leur temps sous les 25 % de charge CPU : ce sont les premières candidates au redimensionnement, à la consolidation ou à la suppression.
Pour le stockage, le script récupère la métrique FreeStorageSpace sur les 60 derniers jours par tranches d'une heure, calcule sa proportion par rapport au stockage total provisionné et la place dans 4 paliers correspondants.
On constate que certaines bases s'appuient sur du stockage provisionné (gp2/gp3). Pour quelques-unes, 100 % des heures échantillonnées affichent au moins 75 % d'espace libre : un signal clair que la taille du stockage peut être réduite.
La maîtrise des coûts AWS est un volet essentiel de la gestion d'une infrastructure cloud. Ce script Python facilite l'obtention d'une vraie visibilité sur les ressources RDS sous-utilisées et aide à repérer les pistes d'économies. En automatisant l'analyse des métriques CloudWatch et en visualisant les résultats dans un rapport Excel, vous prenez des décisions guidées par les données pour optimiser vos dépenses AWS.
Sans rivaliser avec les solutions de monitoring prêtes à l'emploi, ce script vous offre la liberté de découper et d'analyser les données comme vous le souhaitez, et de les présenter à votre convenance. Dans le prochain volet, j'enrichirai le rapport de fonctionnalités supplémentaires liées aux coûts, alors restez à l'écoute.