Im Cloud Computing ist Kostenmanagement genauso entscheidend wie die technische Bereitstellung und der Betrieb der Infrastruktur. AWS bietet als einer der führenden Cloud-Anbieter leistungsstarke Services wie Amazon RDS für die Verwaltung relationaler Datenbanken. Ohne sauberes Monitoring und Optimierung führen diese Services jedoch schnell zu unerwartet hohen Rechnungen. In diesem Blogbeitrag stelle ich ein Skript vor, das ich für Kostenoptimierungs-Reviews des RDS-Service entwickelt habe – damit verschaffen Sie sich Transparenz über ungenutzte RDS-Ressourcen und senken Ihre Kosten spürbar.
Die Herausforderung ungenutzter Ressourcen
Amazon RDS ist ein Managed-Database-Service, der einfache Skalierbarkeit und hohe Verfügbarkeit bietet. Das ist enorm wertvoll – allerdings kommt es häufig vor, dass RDS-Instanzen mit deutlich mehr Ressourcen bereitgestellt werden, als tatsächlich benötigt werden. Mit der Zeit summieren sich solche Instanzen und werden zu einer unnötigen Belastung für Ihr Cloud-Budget.
Ein Ansatz, dieses Problem in den Griff zu bekommen: Überwachen Sie Ihre RDS-Instanzen gezielt auf Unterauslastung. Geeignete Kennzahlen sind unter anderem CPU-Auslastung und Speichernutzung. AWS CloudWatch liefert die nötigen Werkzeuge, um diese Daten zu erfassen. Die manuelle Analyse von CloudWatch-Metriken pro Instanz ist allerdings zeitaufwendig und fehleranfällig – deshalb habe ich den Prozess automatisiert, um Skalierbarkeit, Konsistenz und Wiederverwendbarkeit sicherzustellen.
"""Module to calculade RDS utilization"""
import string
from datetime import datetime, timezone, timedelta
import sys
import openpyxl
from openpyxl.styles import PatternFill, Font
import boto3
REGION = sys.argv[1] if len(sys.argv) > 1 else "us-east-1"
EXCEL_ROW_ITER = 2
column_headers = [\
"Instance",\
"Class",\
"Engine",\
"Engine version",\
"MultiAZ",\
"AZ",\
"Storage type",\
"Allocated Storage",\
"cpu < 25",\
"cpu 25-50",\
"cpu 50-74",\
"cpu > 75",\
"free storage < 25%",\
"free storage 25-50%",\
"free storage 50-74%",\
"free storage > 75%",\
]
red = PatternFill(patternType="solid", fgColor="FC2C03")
orange = PatternFill(patternType="solid", fgColor="E57909")
green = PatternFill(patternType="solid", fgColor="35FC03")
yellow = PatternFill(patternType="solid", fgColor="FCBA03")
wb = openpyxl.Workbook()
ws = wb["Sheet"]
def get_color(usage_type, usage_value):
"""Get color for utilization"""
if usage_type == "bl_25":
if 0 <= usage_value <= 25:
return green
if 25 <= usage_value <= 50:
return yellow
if 50 <= usage_value <= 75:
return red
if usage_value >= 75:
return red
if usage_type in ["bt_25_49", "bt_50_74"]:
if 0 <= usage_value <= 25:
return red
if 25 <= usage_value <= 50:
return orange
if 50 <= usage_value <= 75:
return yellow
if usage_value >= 75:
return green
if usage_type == "gt_75":
if 0 <= usage_value <= 25:
return yellow
if 25 <= usage_value <= 50:
return green
if 50 <= usage_value <= 75:
return orange
if usage_value >= 75:
return red
else:
return None
def fetch_metrics(db_instance_name, metricName):
"""Fetch metrics from cloudwatch"""
stats = cw.get_metric_statistics(
Namespace="AWS/RDS",
MetricName=metricName,
Dimensions=[\
{"Name": "DBInstanceIdentifier", "Value": db_instance_name},\
],
StartTime=datetime.now(timezone.utc) - timedelta(days=60),
EndTime=datetime.now(timezone.utc),
Period=3600,
Statistics=["Maximum"],
)
return stats
def add_row_to_excel(ws, row_data):
"""Write to excel"""
for cnt, data in enumerate(row_data):
ws[f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'] = data
if cnt == 8:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bl_25", data)
if cnt == 9:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_25_49", data)
if cnt == 10:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("bt_50_74", data)
if cnt == 11:
ws[\
f'{string.ascii_uppercase[cnt]}{globals()["EXCEL_ROW_ITER"]}'\
].fill = get_color("gt_75", data)
globals()["EXCEL_ROW_ITER"] += 1
# Initialize Boto3 clients
rds = boto3.client("rds", region_name=REGION)
cw = boto3.client("cloudwatch", region_name=REGION)
# Define column headers
for cnt, header in enumerate(column_headers):
cell_address = f"{string.ascii_uppercase[cnt]}1"
ws[cell_address] = header
ws[cell_address].font = Font(bold=True)
# Fetch RDS instances
response = rds.describe_db_instances()
print(f'Found {len(response["DBInstances"])} databases')
for instance_data in response["DBInstances"]:
db_instance_name = instance_data["DBInstanceIdentifier"]
db_type = instance_data["DBInstanceClass"]
db_storage = instance_data["AllocatedStorage"]
db_engine = instance_data["Engine"]
db_engine_version = instance_data["EngineVersion"]
db_multiaz = instance_data["MultiAZ"]
db_az = instance_data["AvailabilityZone"]
db_storage_type = instance_data["StorageType"]
if db_engine == "docdb":
continue # Skip docdb instances
print(f"Pulling information for {db_instance_name}")
cpu_metrics = fetch_metrics(db_instance_name, "CPUUtilization")
# Calculate usage percentages
usage_values = [d["Maximum"] for d in cpu_metrics["Datapoints"]]
cpu_usage_percentages = [\
round(\
sum(1 for value in usage_values if 25 * i <= value < 25 * (i + 1))\
/ len(usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(cpu_usage_percentages):
print(f"\tCPU {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
storage_usage_percentages = []
if db_storage_type != "aurora":
print("\tStorage found")
storage_metrics = fetch_metrics(db_instance_name, "FreeStorageSpace")
storage_usage_values = [d["Maximum"] for d in storage_metrics["Datapoints"]]
storage_usage_percentages = [\
round(\
sum(\
1\
for value in storage_usage_values\
if 25 * i\
<= value / (1024 * 1024 * 1024) / db_storage * 100\
< 25 * (i + 1)\
)\
/ len(storage_usage_values)\
* 100,\
1,\
)\
for i in range(4)\
]
for i, usage in enumerate(storage_usage_percentages):
print(f"\tStorage {25 * i}% <= value < {25 * (i + 1)}%: {usage}%")
# Add data to Excel worksheet
row_data = (
[\
db_instance_name,\
db_type,\
db_engine,\
db_engine_version,\
db_multiaz,\
db_az,\
db_storage_type,\
db_storage,\
]
+ cpu_usage_percentages
+ storage_usage_percentages
)
add_row_to_excel(ws, row_data)
# Save the Excel workbook
wb.save("results.xlsx")
Kostensenkung mit Python automatisieren
Um unterausgelastete RDS-Instanzen schneller aufzuspüren, greifen wir auf Python zurück – eine vielseitige und weit verbreitete Programmiersprache.
1. RDS-Instanzdaten abrufen
Das Skript verbindet sich zunächst mit AWS und ruft Daten zu Ihren RDS-Instanzen ab. Dabei erfasst es zentrale Informationen wie Instanznamen, Typen, Speicher und mehr.
2. Metrikdaten einsammeln
Anschließend fragt das Skript bei AWS CloudWatch die Metriken zu CPU-Auslastung und Speichernutzung ab. Sie zeigen, wie effektiv Ihre RDS-Instanzen tatsächlich genutzt werden.
3. Auslastung in Prozent berechnen
Aus den erfassten Metriken berechnet das Skript prozentuale Auslastungswerte für CPU und Speicher. Anhand vordefinierter Schwellenwerte werden diese Werte in Auslastungsstufen (z. B. niedrig, mittel, hoch) eingeteilt.
4. Daten visualisieren
Das Skript sammelt nicht nur Daten, sondern erzeugt zusätzlich eine Excel-Tabelle mit den Ergebnissen. Farblich markierte Zellen heben Instanzen je nach Auslastungsstufe hervor – so erkennen Sie unterausgelastete Ressourcen auf einen Blick.
So setzen Sie das Skript ein
Damit Sie das volle Potenzial dieses Skripts ausschöpfen, gehen Sie folgendermaßen vor:
1. Voraussetzungen
- Stellen Sie sicher, dass Python auf Ihrem System installiert ist.
- Installieren Sie die benötigten Python-Bibliotheken:
boto3undopenpyxl.
pip3 install boto3 openpyxl
2. AWS-Konfiguration
- Vergewissern Sie sich, dass Ihre AWS-Zugangsdaten auf Ihrem Rechner korrekt konfiguriert sind. Führen Sie den Befehl get-caller-identity aus und prüfen Sie, ob Sie im richtigen Konto mit den passenden Berechtigungen angemeldet sind.
aws sts get-caller-identity
{
"UserId": "AIDAV7DHVCA7557LUGTRA",
"Account": "410386763839",
"Arn": "arn:aws:iam::410386763839:user/bogdan"
}
3. Skript ausführen
- Führen Sie das Python-Skript aus und übergeben Sie die gewünschte AWS-Region als Argument (oder verwenden Sie die Standardregion "us-east-1").
python3 run.py us-east-2
4. Excel-Bericht prüfen
- Das Skript erzeugt einen Excel-Bericht namens "results.xlsx", der unterausgelastete RDS-Instanzen visuell hervorhebt. Werten Sie diesen Bericht aus, um Einsparpotenziale zu identifizieren.
5. Maßnahmen ergreifen
- Auf Basis des Berichts können Sie unterausgelastete RDS-Instanzen verkleinern oder beenden, um Kosten zu senken.
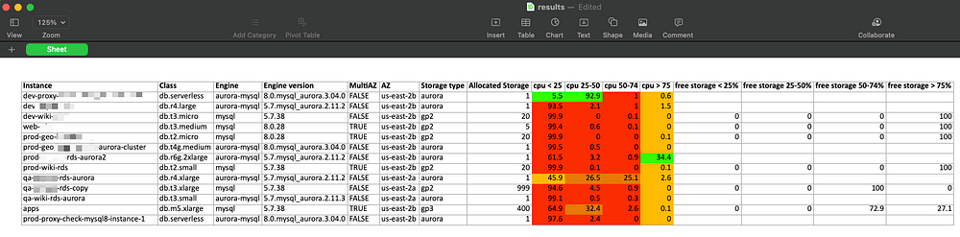
Ergebnisse interpretieren
Das Skript ruft die Metrik CPUUtilization (Maximum) der vergangenen 60 Tage in Stundenintervallen ab und ordnet sie vier Auslastungsklassen zu: 0–25, 25–50, 50–75 und 75–100.
Anschließend berechnet es den Anteil der Stunden in jeder Klasse an den gesamten Betriebsstunden der Instanz.
In den oben gezeigten Beispielergebnissen sehen wir, dass die meisten Datenbanken die meiste Zeit unter 25 % CPU-Last laufen – sie sind die ersten Kandidaten für Right-Sizing, Konsolidierung oder Abschaltung.
Für die Speichernutzung zieht das Skript die Metrik FreeStorageSpace der vergangenen 60 Tage in Stundenintervallen heran, berechnet den prozentualen Anteil am gesamten bereitgestellten Speicher und ordnet das Ergebnis ebenfalls vier entsprechenden Klassen zu.
So erkennen wir etwa, dass einige Datenbanken bereitgestellten Speicher (gp2/gp3) nutzen. Bei manchen davon sind in 100 % der erfassten Stunden 75 % oder mehr Speicher frei – ein klares Indiz dafür, dass die Speichergröße bei diesen Datenbanken reduziert werden kann.
AWS-Kosten im Griff zu haben, gehört zu den Kernaufgaben beim Betrieb einer Cloud-Infrastruktur. Dieses Python-Skript verschafft Ihnen schnell Transparenz über unterausgelastete RDS-Ressourcen und macht Einsparpotenziale sichtbar. Indem Sie die Auswertung von CloudWatch-Metriken automatisieren und die Ergebnisse als Excel-Bericht aufbereiten, treffen Sie datenbasierte Entscheidungen für Ihre AWS-Ausgaben.
Mit fertigen Monitoring-Lösungen kann das Skript zwar nicht mithalten, dafür haben Sie die volle Freiheit, die Daten nach Belieben auszuwerten und so darzustellen, wie Sie es brauchen. In der nächsten Folge ergänze ich weitere kostenrelevante Funktionen – bleiben Sie dran.