プロダクト分析でユーザー一人ひとりの動きを追うため、多くの企業がMixpanelを利用しています。しかし、プロダクトが軌道に乗りイベント量が増えるにつれ、Mixpanelのコストは決して無視できないものになります。本記事では、Jelly Button社向けにGoogle Cloud Platform上で独自のイベント分析基盤を効率よく設計し、年間およそ25万ドルのコスト削減につなげたプロジェクトをご紹介します。
Jelly Button Gamesは、インタラクティブなモバイル・ウェブゲームを開発・配信する企業です。2011年に設立され、看板タイトルは『Pirate Kings』。プレイヤー同士が競い合い、エキゾチックな島々を制覇し、金貨を集め、大海原の覇者を目指す——同社が「mingle-player」体験と呼ぶゲームです。2014年のリリース以降、iOS・Android・Facebook合計で約7,000万ダウンロードを記録しています。
DoiT Internationalは、Google Cloud PlatformやAmazon Web Servicesを基盤とする堅牢なデータソリューションの設計・構築・運用を、スタートアップに伴走しながら支援しています。今回は、Meir Shitrit氏とNir Shney-Dor氏が率いるJelly Buttonチームと協力し、毎時数百万件のイベントを処理・保存するグローバルかつセキュアなデータパイプラインを構築しました。
本ソリューションのベースには、Googleが公開しているMobile Gaming Analyticsのリファレンスアーキテクチャを採用しました。
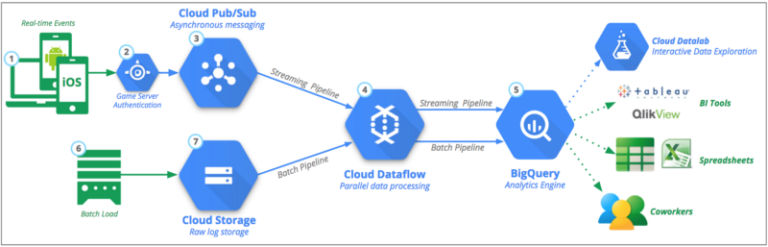
Google Mobile Gaming Analyticsのリファレンスアーキテクチャ
要件
Jelly Buttonが手がけるゲームは、世界中で7,000万人を超えるユーザーがスマートフォンでプレイしています。各プレイヤーからは、ゲームに関するイベントが分析バックエンドに送信され、後段の処理や分析に備えて保存される必要があります。Jelly Buttonはこのデータをゲーム分析、リサーチ、マーケティングに活用しています。
このバックエンドには、モバイルアプリの送信待ち時間を最小限に抑えるための極めて低いレイテンシと、毎秒できる限り多くのイベントを捌けるスループットが求められます。加えて、イベントデータは事業の生命線であり、データロスは一切許容されません。
さらに、イベントデータは可能な限り早く分析可能な状態になっていなければならず、毎時数百万件が流入する状況でも複雑な分析を支障なく行える必要があります。
ソリューション
このようなデータの保存・分析に最適なツールがGoogle BigQueryであることは、最初から明らかでした。事実上無制限のストレージ、圧倒的なクエリ速度、そしてテーブルあたり毎秒10万レコードまで取り込めるビルトインの取り込み機構を備えているからです。
一方で、数百万人のユーザーに低レイテンシを提供するために自動でスケールアップし、トラフィックが少ないときはコストを最小限に抑えるためスケールダウンする、高速かつグローバルで堅牢なバックエンド基盤も必要でした。そこで、マネージドKubernetesクラスタであるGoogle Container Engine(GKE)を採用しました。
Kubernetesを活用し、フェデレーテッドクラスタ構成で極めて効率的なバックエンドを構築しました。米国と欧州にそれぞれクラスタを配置し、両クラスタはジオアウェアネスを内蔵した単一のグローバルなGoogle HTTP/Sロードバランサ経由でトラフィックを受け取ります。これにより、モバイルクライアントからのレイテンシを最小限に抑えています。
もう一つの課題は、バックエンドが受け取ったイベントを確実にGoogle BigQueryへ転送・保存することでした。バックエンドの低レイテンシを損なわないために、Google Cloud Pub/Subを採用しました。Pub/Subは非常に高速なメッセージング基盤で、無制限のスループット、世界規模での配信保証、最大7日間のメッセージ保持に対応します。
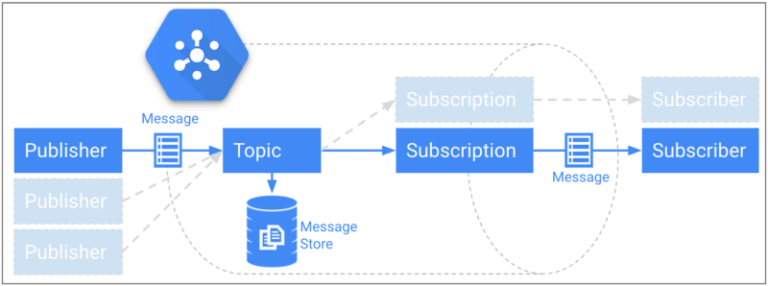
永続ストレージを備えたCloud Pub/Subのpublish-subscribeモデル
最後に必要となったのは、Google PubSubから流れてくる大量のメッセージを処理し、生データに対してフィルタリング・マッピング・集計を行ってからGoogle BigQueryへ保存するETLでした。幸い、Google Dataflowはフルマネージドなワーカークラスタを提供しており、ストリーミングモードでETLを実行できます。これによりニアリアルタイムで変換・集計を処理し、ほぼ即座にデータを分析可能な状態にできます。
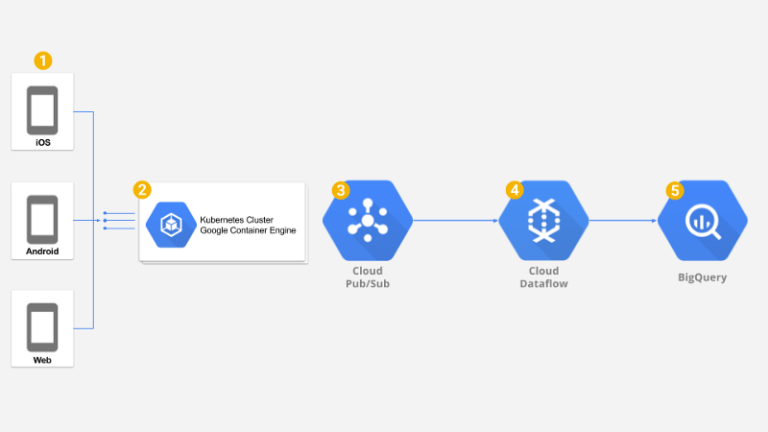
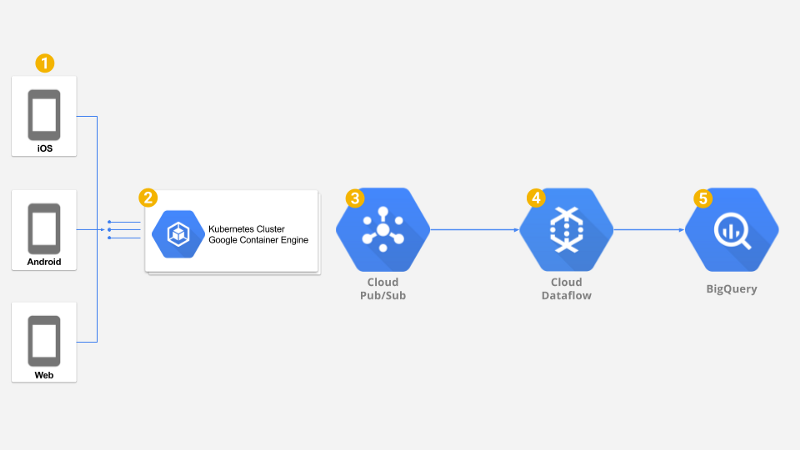
ソリューション全体像
Kubernetes
今回の構成では、各Podに2つのコンテナを配置しています。nginxコンテナと、バックエンドコードを動かすNode.jsコンテナです。
バックエンドコードは、シンプルなNode.jsベースのサーバーです。
https://gist.github.com/spark2ignite/d9e927f589f2b3b998988b913ee27dc4
バックエンドはメタデータを付与し、ペイロードとともにGoogle PubSubへプッシュするだけです。低レイテンシを維持するため、ここでは余計な処理を行いません。
デプロイされたサービスは、KubernetesのHorizontal Pod Autoscalerで自動スケールします。
https://gist.github.com/spark2ignite/26a9fbeeea279394730ac39b9c1b1df1
クラスタ自体もGoogle Container Engine Node Autoscalerで自動スケールされ、ノードも自動的にスケールアップ・スケールダウンします。
Google Cloud Dataflow
必要となる変換・集計ロジックの大半は、Dataflowパイプライン内で実行しています。これにより、Dataflowの分散コンピューティングクラスタ上で、非同期かつノンブロッキングに処理できます。
基本パイプラインは、Google PubSubから受け取ったメッセージをパースし、一部のフィールドをBigQueryのカラムに展開しつつ、残りのデータはJSONオブジェクトとしてBigQueryの文字列カラムに格納します。
https://gist.github.com/spark2ignite/a833f04c98d38c11a7398967835c9317
機能を追加する場合、通常は該当するMappingクラスを編集するだけで済みます。
https://gist.github.com/spark2ignite/35b78bb689060eb630468e0e8616b70f
次の一行に注目してください。
options.setStreaming(true);これにより、Dataflowパイプラインがストリーミングモードで起動します。手動で停止しない限り稼働し続け、Google Pub/Subに到着したメッセージをニアリアルタイムで処理し続けます。
コスト
Jelly Buttonが独自のデータパイプライン構築に踏み切った狙いは、Mixpanelのコストを抑えつつ、より柔軟なデータ分析基盤を手に入れることでした。
2017年7月時点で、新しいデータ分析パイプラインは毎秒およそ500件のイベントを処理していました。Google Cloud Platformのコスト内訳は次のとおりです。
- Google Cloud Dataflow:約500ドル
- Google Container Engine:約500ドル
- Google Pub/Sub:約200ドル
- Google BigQuery:約100ドル
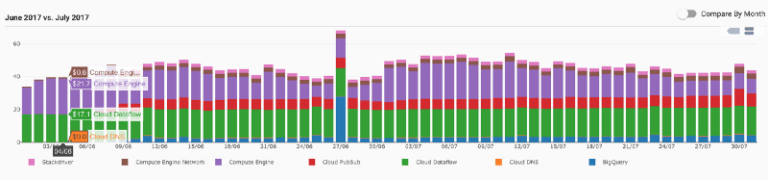
Jelly ButtonはGoogle Cloud PlatformのコストをDoiT Cloud Intelligence™で追跡・管理しています。日次の平均支出は次のように可視化されています。
まとめ
プロジェクト全体は、約5週間で完了しました。Jelly Buttonと密に連携しながら、アーキテクチャの設計、PoCの構築、そして実装と実トラフィックでのテストに、しっかりと時間を割きました。本番稼働の開始から数か月が経ちましたが、Jelly Buttonは『Pirate Kings』をはじめ今後リリースされる新タイトルで加わる数百万人規模のプレイヤーを支えるだけの堅牢な分析パイプラインを手にしたと確信しています。