Molte aziende si affidano da sempre a Mixpanel per la product analytics e per ricostruire il percorso di ogni utente. Quando però il prodotto decolla e il volume di eventi cresce, Mixpanel può diventare piuttosto oneroso. In questo articolo ripercorriamo uno dei progetti realizzati con Jelly Button: una soluzione di event-analytics su misura, basata su Google Cloud Platform, estremamente efficiente, che farà risparmiare a Jelly Button circa un quarto di milione di dollari l'anno.
Jelly Button Games sviluppa e pubblica giochi interattivi per mobile e web. Fondata nel 2011, ha come titolo di punta Pirate Kings, in cui i giocatori si sfidano con gli amici per conquistare isole esotiche, accumulare oro e diventare il signore dei sette mari, in quella che Jelly Button Games definisce un'esperienza "mingle-player". Lanciato nel 2014, il gioco ha superato i 70 milioni di download tra iOS, Android e Facebook.
Noi di DoiT International aiutiamo le startup a progettare, realizzare e gestire soluzioni dati altamente affidabili su Google Cloud Platform e Amazon Web Services. Insieme al team di Jelly Button, guidato da Meir Shitrit e Nir Shney-Dor, abbiamo costruito una pipeline dati globale, robusta e sicura, capace di elaborare e archiviare milioni di eventi ogni ora.
Come punto di partenza per la nostra soluzione abbiamo adottato la Reference Architecture di Google per la Mobile Gaming Analytics.
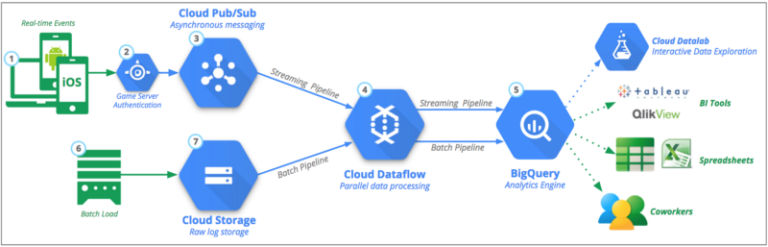
Reference Architecture di Google per la Mobile Gaming Analytics
I requisiti
Jelly Button sviluppa giochi a cui giocano oltre 70 milioni di persone dal proprio smartphone. Ogni giocatore invia al backend di analytics gli eventi legati al gioco, che devono essere archiviati per la successiva elaborazione e analisi. Jelly Button utilizza questi dati per game analytics, ricerca e marketing.
Il backend deve garantire una latenza molto bassa, così che l'app mobile attenda il meno possibile durante l'invio degli eventi, ed elaborare il maggior numero di eventi al secondo. Detto questo, i dati degli eventi sono un asset critico: nessuna perdita è ammissibile.
Infine, i dati degli eventi devono essere disponibili per l'analisi nel più breve tempo possibile, e i milioni di eventi che arrivano ogni ora non devono ostacolare l'esecuzione di analisi complesse.
La soluzione
Fin da subito è stato chiaro che lo strumento migliore per archiviare e analizzare questo tipo di dati fosse Google BigQuery: offre uno storage praticamente illimitato, query fulminee e un meccanismo di ingestion integrato che consente di inserire fino a 100K record al secondo per tabella.
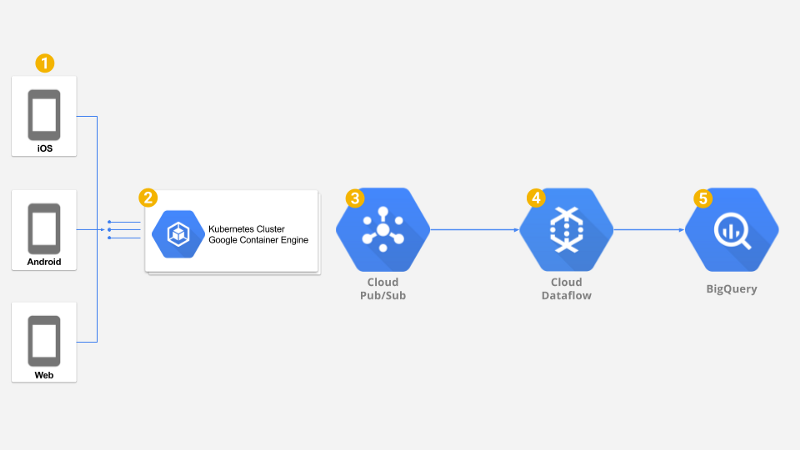
Serviva poi un'infrastruttura backend veloce, globale e robusta, in grado di scalare automaticamente verso l'alto per garantire una bassa latenza a milioni di utenti, oppure verso il basso per contenere al minimo i costi. Abbiamo quindi scelto Google Container Engine (GKE), un cluster Kubernetes gestito.
Con Kubernetes siamo riusciti a configurare un backend molto efficiente, distribuito come cluster federato — uno negli Stati Uniti e uno in Europa, entrambi al servizio del traffico instradato da un unico Google HTTP/S Load Balancer globale con geo-awareness integrata, garantendo così una latenza minima per i client mobile.
Un'altra sfida riguardava il trasferimento degli eventi raccolti dal backend e la loro archiviazione affidabile su Google BigQuery. Per preservare la bassa latenza del backend abbiamo scelto Google Cloud Pub/Sub: un canale di messaggistica molto rapido, capace di sostenere un throughput illimitato con consegna garantita a livello globale e fino a 7 giorni di persistenza dei messaggi.
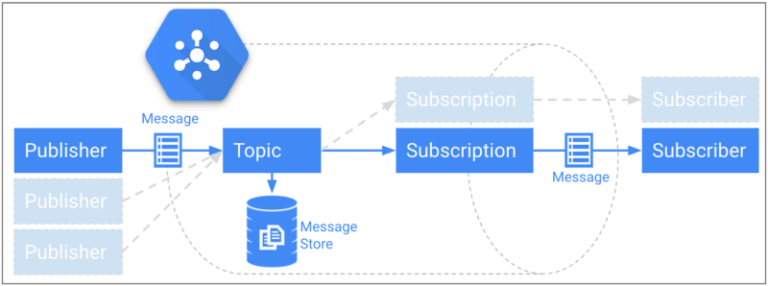
Modello publish/subscribe di Cloud Pub/Sub con storage persistente
L'ultimo tassello mancante era un ETL in grado di gestire l'enorme volume di messaggi provenienti da Google PubSub ed eseguire filtri, mapping e aggregazioni sui dati grezzi prima di archiviarli su Google BigQuery per l'analisi. Per nostra fortuna, Google Dataflow mette a disposizione un cluster di workers completamente gestito, capace di eseguire il nostro ETL in modalità streaming per gestire trasformazioni e aggregazioni in near realtime, rendendo i dati disponibili per l'analisi quasi istantaneamente.
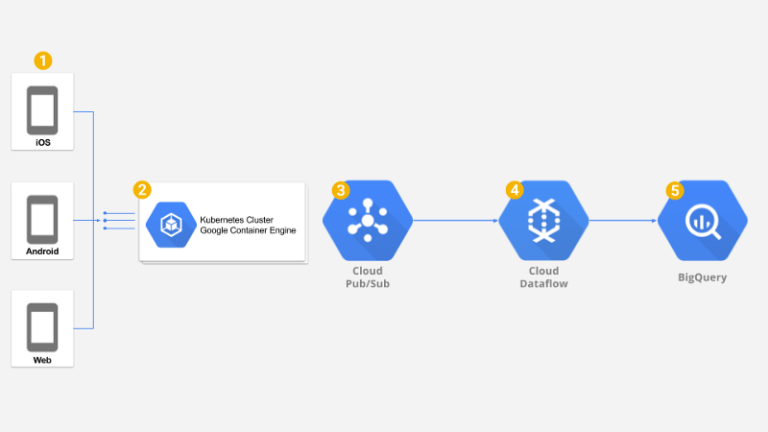
Panoramica della soluzione
Kubernetes
Nella nostra configurazione, ogni pod contiene due container: un container nginx e uno nodejs con il codice del backend.
Il codice del backend è in sostanza un semplice server in nodejs
https://gist.github.com/spark2ignite/d9e927f589f2b3b998988b913ee27dc4
Il backend si limita ad aggiungere alcuni metadati e a inoltrare il payload a Google PubSub. Nient'altro, così da mantenere bassa la latenza.
Il servizio distribuito viene scalato automaticamente tramite l'Horizontal Pod Autoscaler di Kubernetes
https://gist.github.com/spark2ignite/26a9fbeeea279394730ac39b9c1b1df1
Anche il cluster stesso scala automaticamente grazie al Google Container Engine Node Autoscaler, che aggiunge o rimuove i nodi in autonomia.
Google Cloud Dataflow
La maggior parte della logica di trasformazione e aggregazione viene eseguita all'interno della pipeline Dataflow. In questo modo può essere svolta in modo asincrono e non bloccante grazie al cluster di calcolo distribuito di Dataflow.
La pipeline di base si limita a fare il parsing dei messaggi provenienti da Google PubSub e a mappare alcuni campi su colonne BigQuery, conservando il resto dei dati come oggetto json in una colonna di tipo string su BigQuery.
https://gist.github.com/spark2ignite/a833f04c98d38c11a7398967835c9317
Per aggiungere nuove funzionalità, di norma basta modificare la classe Mapping pertinente
https://gist.github.com/spark2ignite/35b78bb689060eb630468e0e8616b70f
Si noti la riga:
options.setStreaming(true);Questa istruzione avvia la pipeline Dataflow in modalità streaming: non si fermerà finché non verrà arrestata manualmente e continuerà a elaborare i messaggi mano a mano che arrivano su Google Pub/Sub, in near realtime.
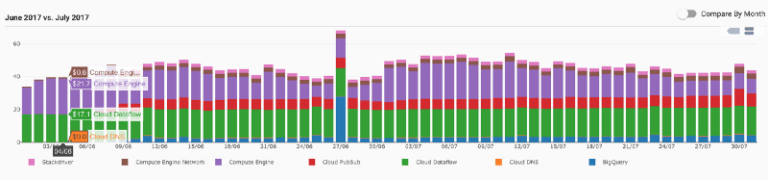
I costi
Jelly Button ha intrapreso il percorso di costruzione di una pipeline dati interna per abbattere i costi di Mixpanel e dotarsi di una pipeline di data analytics più flessibile.
A luglio 2017 la nostra nuova pipeline di data analytics elaborava circa 500 eventi al secondo. Ecco il riepilogo dei costi sostenuti su Google Cloud Platform:
- Circa 500$ per Google Cloud Dataflow
- Circa 500$ per Google Container Engine
- Circa 200$ per Google Pub/Sub
- Circa 100$ per Google BigQuery
Jelly Button monitora e tiene sotto controllo i costi di Google Cloud Platform con DoiT Cloud Intelligence™. Ecco com'è la spesa media giornaliera di Jelly Button:
In sintesi
L'intero progetto ci ha richiesto circa 5 settimane. Abbiamo dedicato parecchio tempo, fianco a fianco con Jelly Button, alla progettazione della soluzione, alla realizzazione di un proof of concept e infine allo sviluppo e al collaudo con traffico reale. È in produzione ormai da un paio di mesi e siamo certi che oggi Jelly Button possa contare su una pipeline di analytics solida, capace di supportare i milioni di nuovi giocatori di Pirate Kings e dei titoli in arrivo.